使用python scrapy爬取知乎提问信息
前文介绍了python的scrapy爬虫框架和登录知乎的方法.
这里介绍如何爬取知乎的问题信息,并保存到mysql数据库中.
首先,看一下我要爬取哪些内容:
如下图所示,我要爬取一个问题的6个信息:
- 问题的id(question_id)
- 标题(title)
- 问题描述(intro)
- 回答个数(answer_num)
- 关注人数(attention_uv)
- 浏览次数(read_pv)
 

爬取结果我保存到mysql数据库中,表名为:zhihu_question
如下图中,红框里的就是上图是有人为我的穿着很轻浮,我该如何回应?问题的信息.
(回答个数,关注着和浏览次数数据不一致是因为我是在爬取文章信息之后的一段时间才抽出来时间写的文章,在这期间回答个数,关注着和浏览次数都会增长.)
 

爬取方法介绍
我用的是scrapy框架中自带的选择器selectors.
selectors通过特定的 XPath 或者 CSS 表达式来“选择” HTML文件中的某个部分。
XPath 是一门用来在XML文件中选择节点的语言,也可以用在HTML上。 CSS 是一门将HTML文档样式化的语言。
XPath最最直观的介绍:
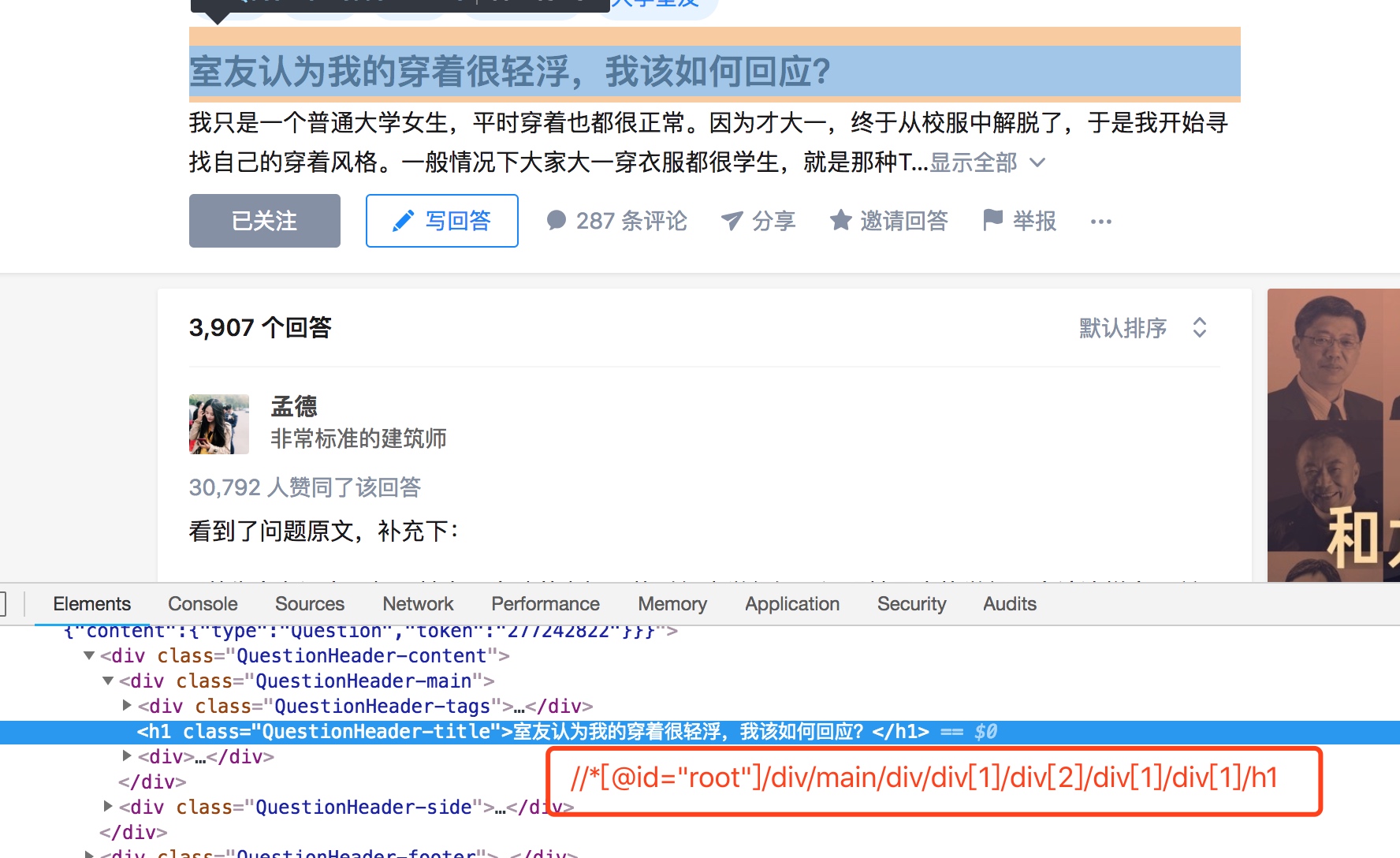
例如:知乎问题页面上的标题的XPath如下:
图中红框里就是标题的XPath.(这只是一个直观的介绍,还有一些细节可以在代码中看到)

爬取代码:
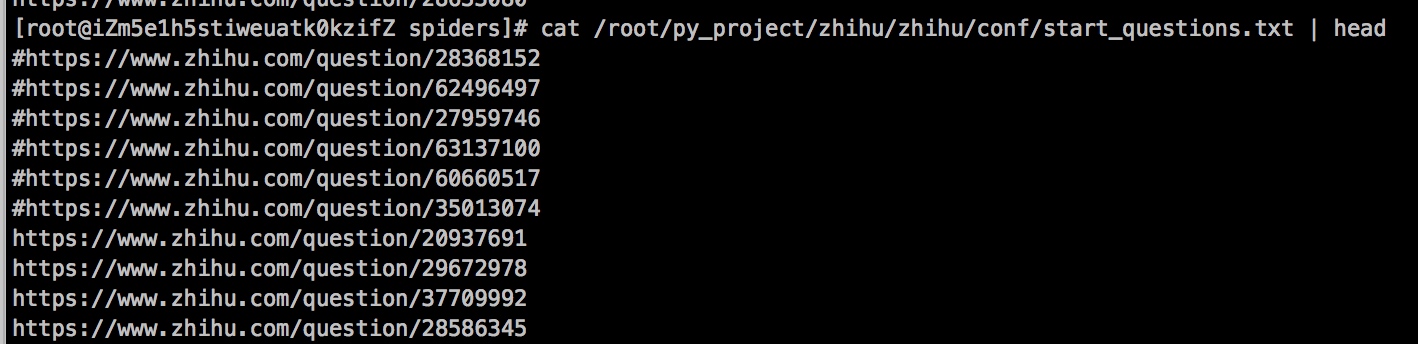
爬取问题的相关信息只需要问题url即可,我这里把收集的问题url写到文件中,爬虫程序去遍历文件,然后依次爬取.
我是在登录成功知乎后的check_login这个方法里面构造的起始url,所以读文件的方法也在这里,代码如下:
def check_login(self, response):
# 验证登录成功之后构造初始问题url
file = open("/root/py_project/zhihu/zhihu/conf/start_questions.txt")
while 1:
line = file.readline()
line = line.strip('\n') #去掉最后的换行
if not line:
break
if(line[0:1] == "#"):
#如果是#开头的url, 跳过
print line
pass
else:
print("current url : " + line)
yield scrapy.Request(line,callback=self.parse_question, headers=self.headers)
file.close()
其中最重要的一行是:
yield scrapy.Request(line,callback=self.parse_question, headers=self.headers)
yield scrapy.Request 代表开始爬取一条url,如果有多个url就yield多次. 这里的次数等同于start_question.txt中非#开头的url
如下:

callback=self.parse_question 是请求url地址后,返回的response的回调处理函数,也是整个爬取过程中最核心的代码.
如下:
def parse_question(self,response):
item = QuestionItem()
url = response.url
questionid=url[url.rindex("/")+1:]
item['questionid']=questionid
item['title']=response.selector.xpath('//*[@class="QuestionHeader-title"]/text()')[0].extract()
descarr=response.selector.xpath('//span[@itemprop="text"]/text()')
if len(descarr) > 0:
item['desc']=descarr[0].extract()
else:
item['desc']="-"
item['answer_num']=response.selector.xpath('//*[@id="QuestionAnswers-answers"]/div/div/div[1]/h4/span/text()[1]')[0].extract().replace(',','')
item['attention_uv']=response.selector.xpath('//strong[@class="NumberBoard-itemValue"]/text()')[0].extract().replace(',','')
item['read_pv']=response.selector.xpath('//strong[@class="NumberBoard-itemValue"]/text()')[1].extract().replace(',','')
yield item
其中主要代码是用selectors.xpath选取我们需要的问题信息(注意:这里的路径并不一定与 chrome的debug模式中复制的xpath一致,直接复制的xpath一般不太能用,自己看html代码结构写的),
获取到问题的信息之后放到item.py中定义好的QuestionItem对象中,然后yield 对象 , 会把对象传递到配置的pipelines中.
pipelines一般是在配置文件中配置,
因为这里爬取问题只保存到mysql数据库,并不下载图片,(而爬取答案需要下载图片)所以各自在在爬虫程序中定义的pipelines,如下:
custom_settings = {
'ITEM_PIPELINES' : {
'zhihu.mysqlpipelines.MysqlPipeline': 5
#'scrapy.pipelines.images.ImagesPipeline': 1,#这个是scrapy自带的图片下载pipelines
}
}
以上是爬取知乎问题的整个大致过程.
后文介绍爬取收藏夹下的回答 和 问题下的回答(包括内容和图片).
使用python scrapy爬取知乎提问信息的更多相关文章
- python scrapy爬取知乎问题和收藏夹下所有答案的内容和图片
上文介绍了爬取知乎问题信息的整个过程,这里介绍下爬取问题下所有答案的内容和图片,大致过程相同,部分核心代码不同. 爬取一个问题的所有内容流程大致如下: 一个问题url 请求url,获取问题下的答案个数 ...
- 利用 Scrapy 爬取知乎用户信息
思路:通过获取知乎某个大V的关注列表和被关注列表,查看该大V和其关注用户和被关注用户的详细信息,然后通过层层递归调用,实现获取关注用户和被关注用户的关注列表和被关注列表,最终实现获取大量用户信息. 一 ...
- 爬虫(十六):scrapy爬取知乎用户信息
一:爬取思路 首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账 ...
- 爬虫实战--利用Scrapy爬取知乎用户信息
思路: 主要逻辑图:
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
- scrapy 爬取知乎问题、答案 ,并异步写入数据库(mysql)
python版本 python2.7 爬取知乎流程: 一 .分析 在访问知乎首页的时候(https://www.zhihu.com),在没有登录的情况下,会进行重定向到(https://www. ...
- scrapy爬取知乎某个问题下的所有图片
前言: 1.仅仅是想下载图片,别人上传的图片也是没有版权的,下载来可以自己欣赏做手机背景但不商用 2.由于爬虫周期的问题,这个代码写于2019.02.13 1.关于知乎爬虫 网上能访问到的理论上都能爬 ...
- python scrapy爬取HBS 汉堡南美航运公司柜号信息
下面分享个scrapy的例子 利用scrapy爬取HBS 船公司柜号信息 1.前期准备 查询提单号下的柜号有哪些,主要是在下面的网站上,输入提单号,然后点击查询 https://www.hamburg ...
- Python——Scrapy爬取链家网站所有房源信息
用scrapy爬取链家全国以上房源分类的信息: 路径: items.py # -*- coding: utf-8 -*- # Define here the models for your scrap ...
随机推荐
- redis 五种数据类型
前言 前面学会了单机, 学会了集群, 但是redis咋用啊? 或者说, redis支持哪些数据类型呢? 常用的有五种: String , Hash, List, Set, zset(SortedSet ...
- 泛型理解及应用(二):使用泛型编写通用型Dao层
相信目前所有的IT公司网站在设计WEB项目的时候都含有持久层,同样地使用过Hibernate的程序员都应该看过或者了解过Hibernate根据数据库反向生成持久层代码的模板.对于Hibernate生成 ...
- 由浅入深:CNN中卷积层与转置卷积层的关系
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由forrestlin发表于云+社区专栏 导语:转置卷积层(Transpose Convolution Layer)又称反卷积层或分数卷 ...
- [NOI 2015]品酒大会
Description 题库链接 \(n\) 杯鸡尾酒排成一行,其中第 \(i\) 杯酒 (\(1 \leq i \leq n\)) 被贴上了一个标签 \(s_i\),每个标签都是 \(26\) 个小 ...
- Shell 实例:备份最后一天内所有修改过的文件
在一个"tarball"中(经过 tar 和 gzip 处理过的文件)备份最后 24 小时之内当前目录下所有修改的文件. 程序代码如下: #!/bin/bash BACKUPFIL ...
- EF select 匿名类 问题
连续两次被相同问题困扰. 一.举例 var query=db.StudentScore.Where(r=> r.SubjectId==subjectId).Select(g=>new {S ...
- Flask在Pycharm开启调试模式
一.Flask在Pycharm2018前的版本只需设置(两种方法之一): 1. 直接设置app的debug为true: app.debug=true 2. 把debug=true作为参数,传入到 ...
- 【Spring】10、Spring中用@Component、@Repository、@Service和 @Controller等标注的默认Bean名称会是小写开头的非限定类名
@Service用于标注业务层组件(我们通常定义的service层就用这个) @Controller用于标注控制层组件(如struts中的action) @Repository用于标注数据访问组件,即 ...
- JQuery的事件委托;jQuery注册事件;jQuery事件解绑
一.事件 ①事件委托:就是给子元素的父元素或者祖先元素注册一个事件,但是事件的执行者是子元素,委托事件的好处是能够给动态创建出来时元素也加上事件. ②简单事件:就是给自己注册事件自己执行动态创建出来的 ...
- java.io.IOException No space left on device
磁盘空间不足 1.df -k,发现程序所在的工作目录/data,居然到了100%. 1604050 free allocated Kb 535144219 used allocated Kb 100 ...