无忧代理免费ip爬取(端口js加密)
起因
为了训练爬虫技能(其实主要还是js技能…),翻了可能有反爬的网站挨个摧残,现在轮到这个网站了:http://www.data5u.com/free/index.shtml
解密过程
打开网站,在免费ip的列表页查看元素选一个端口,发现表示端口的元素class属性上有可疑的东西(代理ip类网站的反爬总是这么没有创意…):
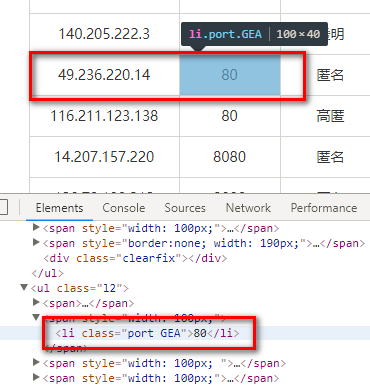
上面的“GEA”很像是密文存储的东西,怀疑端口号是页面加载完再用js计算出来填充上的,要证明的话也很简单,只需要对照下这个元素当前的值和刚下载下来的时候值是否一致,在控制台查看元素看到的是内存中元素的当前状态,查看页面源代码的才是页面被下载来那一刻的状态,右键-->查看网页源代码。搜索“49.236.220.14”,发现端口号果然不一样,页面被下载下来时是8916,现在显示的却是80.

解密逻辑在这个js中:http://www.data5u.com/theme/data5u/javascript/pde.js?v=1.0,原始的js进行了压缩,使用之前写过的展开eval的方法进行eval展开并格式化(注意需要eval展开两次):
var _$ = ['\x2e\x70\x6f\x72\x74', "\x65\x61\x63\x68", "\x68\x74\x6d\x6c", "\x69\x6e\x64\x65\x78\x4f\x66", '\x2a', "\x61\x74\x74\x72", '\x63\x6c\x61\x73\x73', "\x73\x70\x6c\x69\x74", "\x20", "", "\x6c\x65\x6e\x67\x74\x68", "\x70\x75\x73\x68", '\x41\x42\x43\x44\x45\x46\x47\x48\x49\x5a', "\x70\x61\x72\x73\x65\x49\x6e\x74", "\x6a\x6f\x69\x6e", ''];
$(function() {
$(_$[0])[_$[1]](function() {
var a = $(this)[_$[2]]();
if (a[_$[3]](_$[4]) != -0x1) {
return
};
var b = $(this)[_$[5]](_$[6]);
try {
b = (b[_$[7]](_$[8]))[0x1];
var c = b[_$[7]](_$[9]);
var d = c[_$[10]];
var f = [];
for (var g = 0x0; g < d; g++) {
f[_$[11]](_$[12][_$[3]](c[g]))
};
$(this)[_$[2]](window[_$[13]](f[_$[14]](_$[15])) >> 0x3)
} catch(e) {}
})
})
上面这段js仍然是不可读的,可以看到一些关键词被抽取出来放到了一个字典数组中,字典数组中的字面值还被十六进制编码了,所以接下来需要写点js将其转换为可读形式,下面是转换的代码:
<html>
<head></head>
<body>
<script type="text/code-template" id="functionBody">
$(function() {
$(_$[0])[_$[1]](function() {
var a = $(this)[_$[2]]();
if (a[_$[3]](_$[4]) != -0x1) {
return
};
var b = $(this)[_$[5]](_$[6]);
try {
b = (b[_$[7]](_$[8]))[0x1];
var c = b[_$[7]](_$[9]);
var d = c[_$[10]];
var f = [];
for (var g = 0x0; g < d; g++) {
f[_$[11]](_$[12][_$[3]](c[g]))
};
$(this)[_$[2]](window[_$[13]](f[_$[14]](_$[15])) >> 0x3)
} catch(e) {}
})
})
</script>
<script type="text/javascript"> var _$ = ['\x2e\x70\x6f\x72\x74', "\x65\x61\x63\x68", "\x68\x74\x6d\x6c", "\x69\x6e\x64\x65\x78\x4f\x66", '\x2a', "\x61\x74\x74\x72", '\x63\x6c\x61\x73\x73', "\x73\x70\x6c\x69\x74", "\x20", "", "\x6c\x65\x6e\x67\x74\x68", "\x70\x75\x73\x68", '\x41\x42\x43\x44\x45\x46\x47\x48\x49\x5a', "\x70\x61\x72\x73\x65\x49\x6e\x74", "\x6a\x6f\x69\x6e", ''];
let functionBody = document.getElementById("functionBody").innerHTML;
let readableFunctionBody = functionBody.replace(/_\$\[[0-9]+\]/g, x => "'" + eval(x) + "'");
document.write(readableFunctionBody); </script>
</body>
</html>
转换并格式化:
$(function() {
$('.port')['each'](function() {
var a = $(this)['html']();
if (a['indexOf']('*') != -0x1) {
return
};
var b = $(this)['attr']('class');
try {
b = (b['split'](' '))[0x1];
var c = b['split']('');
var d = c['length'];
var f = [];
for (var g = 0x0; g < d; g++) {
f['push']('ABCDEFGHIZ' ['indexOf'](c[g]))
};
$(this)['html'](window['parseInt'](f['join']('')) >> 0x3)
} catch(e) {}
})
})
可以看到解密逻辑已经很清晰了,就是把端口元素上第二个class(假定从1开始),也就是那个奇怪的字符串拿出来,然后在'ABCDEFGHIZ'中找其位置,最后把找到的位置坐标按顺序拼接并转为数字然后除以8,即得到最终的端口号,根据解密逻辑写出java代码:
private static int decodePort(String rawContent) {
String rawNum = Stream.of(rawContent.split(""))
.map("ABCDEFGHIZ"::indexOf)
.map(Object::toString)
.collect(Collectors.joining());
return Integer.parseInt(rawNum) >> 3;
}
一个简单的抓取demo:
package org.cc11001100.t1; import javaslang.Tuple;
import javaslang.Tuple2;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements; import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.net.URL;
import java.net.URLEncoder;
import java.util.Collections;
import java.util.List;
import java.util.Objects;
import java.util.stream.Collectors;
import java.util.stream.Stream; import static java.util.stream.Collectors.toList; /**
* 这个网站的代理: http://www.data5u.com/free/index.shtml
* 端口有加密
*
* @author CC11001100
*/
public class Data5UProxyGrab { private static int decodePort(String rawContent) {
String rawNum = Stream.of(rawContent.split(""))
.map("ABCDEFGHIZ"::indexOf)
.map(Object::toString)
.collect(Collectors.joining());
return Integer.parseInt(rawNum) >> 3;
} private static List<Tuple2<String, Integer>> parse(String url) {
try {
Document document = Jsoup.parse(new URL(url), 3000);
return document.select(".wlist ul li[style=text-align:center;] ul.l2")
.stream()
.map(elt -> {
String ip = elt.select("span").first().text();
Elements portElt = elt.select(".port");
if (!portElt.isEmpty() && !portElt.html().contains("*")) {
String[] ss = portElt.attr("class").split("\\s+");
if (ss.length >= 2) {
return Tuple.of(ip, decodePort(ss[1]));
}
}
return null;
})
.filter(Objects::nonNull)
.collect(toList());
} catch (IOException e) {
e.printStackTrace();
}
return Collections.emptyList();
} /**
* 按照国家抓取
*/
public static List<Tuple2<String, Integer>> grabByCountry() throws IOException {
String url = "http://www.data5u.com/free/country/%s/index.html";
return Jsoup.parse(new URL(String.format(url, urlEncode("中国"))), 3000)
.select("#areaDist ul.bigr span")
.stream()
.map(elt -> elt.attr("title"))
.flatMap(countryName -> parse(String.format(url, urlEncode(countryName))).stream())
.distinct()
.collect(toList());
} private static String urlEncode(String raw) {
try {
return URLEncoder.encode(raw, "UTF-8");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return "";
} public static void main(String[] args) throws IOException {
grabByCountry().forEach(System.out::println);
} }
更省力的方案
上面都太麻烦了,只是为了锻炼一下js技能,其实观察一下发现这个网站的功能设计得很奇怪,比如ip列表提供的筛选功能,下面被圈起来的都是可以作为筛选条件的:

但是偏偏没有端口,鼠标移动到端口上点击是没有反应的,这是因为他要做端口加密啊,让你知道了端口不白做了,然而木用…
下面是分别使用几种过滤条件时地址栏中显示的url:
http://www.data5u.com/free/anoy/匿名/index.html
http://www.data5u.com/free/type/https/index.html
http://www.data5u.com/free/country/中国/index.html
http://www.data5u.com/free/area/云南/index.html
http://www.data5u.com/free/isp/电信/index.html
根据以上已知基本可推出端口过滤的话可能是类似于下面这种:
http://www.data5u.com/free/port/80/index.html
然后试了一下,只一次就成功了 …
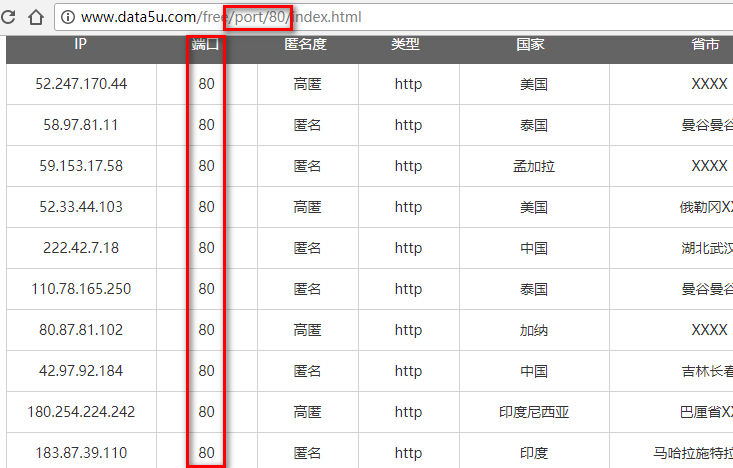
不知道作者怎么想的,这点不如蚂蚁代理了,蚂蚁代理也支持端口号筛选,不过它普通的情况下是这样的:
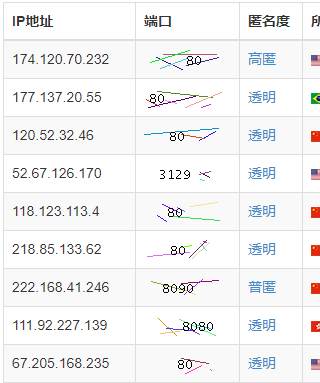
端口号是用图片显示的,按照端口筛选是这样的:
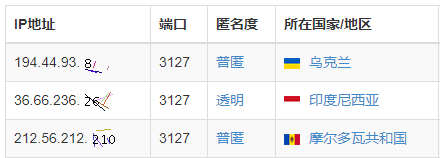
因为发请求的人已经知道端口号了,所以再图片显示端口号也没用了,不如干脆将ip地址的一部分按图片显示,这种设计还是比较好的,因为反爬虫对对方已知信息增加获取难度没有意义,应该对其未知信息设计获取门槛。
不过没卵用,下一篇写破解蚂蚁代理的反爬。
无忧代理免费ip爬取(端口js加密)的更多相关文章
- 全网代理公开ip爬取(隐藏元素混淆+端口加密)
简述 本次要爬取的网站是全网代理,貌似还是代理ip类网站中比较有名的几个之一,其官网地址: http://www.goubanjia.com/. 对于这个网站的爬取是属于比较悲剧的,因为很久之前就写好 ...
- requests 使用免费的代理ip爬取网站
import requests import queue import threading from lxml import etree #要爬取的URL url = "http://xxx ...
- 代理IP爬取和验证(快代理&西刺代理)
前言 仅仅伪装网页agent是不够的,你还需要一点新东西 今天主要讲解两个比较知名的国内免费IP代理网站:西刺代理&快代理,我们主要的目标是爬取其免费的高匿代理,这些IP有两大特点:免费,不稳 ...
- 代理IP爬取,计算,发放自动化系统
IoC Python端 MySQL端 PHP端 怎么使用 这学期有一门课叫<物联网与云计算>,于是我就做了一个大作业,实现的是对代理IP的爬取,计算推荐,发放给用户等任务的的自动化系统.由 ...
- 蚂蚁代理免费代理ip爬取(端口图片显示+token检查)
分析 蚂蚁代理的列表页大致是这样的: 端口字段使用了图片显示,并且在图片上还有各种干扰线,保存一个图片到本地用画图打开观察一下: 仔细观察蓝色的线其实是在黑色的数字下面的,其它的干扰线也是,所以这幅图 ...
- 酷伯伯实时免费HTTP代理ip爬取(端口图片显示+document.write)
分析 打开页面http://www.coobobo.com/free-http-proxy/,端口数字一看就不对劲,老规律ctrl+shift+c选一下: 这就很悲剧了,端口数字都是用图片显示的: 不 ...
- 爬虫 selenium+Xpath 爬取动态js页面元素内容
介绍 selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如 ...
- 爬虫05 /js加密/js逆向、常用抓包工具、移动端数据爬取
爬虫05 /js加密/js逆向.常用抓包工具.移动端数据爬取 目录 爬虫05 /js加密/js逆向.常用抓包工具.移动端数据爬取 1. js加密.js逆向:案例1 2. js加密.js逆向:案例2 3 ...
- 爬取西刺ip代理池
好久没更新博客啦~,今天来更新一篇利用爬虫爬取西刺的代理池的小代码 先说下需求,我们都是用python写一段小代码去爬取自己所需要的信息,这是可取的,但是,有一些网站呢,对我们的网络爬虫做了一些限制, ...
随机推荐
- 用js来实现那些数据结构(数组篇03)
终于,这是有关于数组的最后一篇,下一篇会真真切切给大家带来数据结构在js中的实现方式.那么这篇文章还是得啰嗦一下数组的相关知识,因为数组真的太重要了!不要怀疑数组在JS中的重要性与实用性.这篇文章分为 ...
- Linux kernel 4.9及以上开启TCP BBR拥塞算法
Linux kernel 4.9及以上开启TCP BBR拥塞算法 BBR 目的是要尽量跑满带宽, 并且尽量不要有排队的情况, 效果并不比速锐差 Linux kernel 4.9+ 已支持 tcp_bb ...
- 用js来实现那些数据结构06(队列)
其实队列跟栈有很多相似的地方,包括其中的一些方法和使用方式,只是队列使用了与栈完全不同的原则,栈是后进先出原则,而队列是先进先出(First In First Out). 一.队列 队列是一种特 ...
- Spring-framework 源码导入 IntelliJ IDEA 记录
前言 想学习spring框架,不看源码怎么行.网上有很多教程,但是自己实施起来还是稍微有点坎坷的,不过最后还是成功了.遂以此文记录. 环境说明: Idea 2017.2.5 spring-frame ...
- python 随笔
python 学习笔记 运算符重载 PYTHON-进阶-魔术方法小结(方法运算符重载) python有着像C++相似的运算符重载,只需要在类中重写__add__.sub 等方法,就可以直接对对象进行 ...
- osx mitmproxy ssl 错误
记录一下,总是在这里折腾. cd ~ cd .mitmproxy cp mitmproxy-ca-cert.pem ~/ 然后到目录下双击mitmproxy-ca-cert.pem ,在钥匙串中的登录 ...
- 计蒜客NOIP模拟赛4 D1T2小X的密室
小 X 正困在一个密室里,他希望尽快逃出密室. 密室中有 N 个房间,初始时,小 X 在 1 号房间,而出口在 N 号房间. 密室的每一个房间中可能有着一些钥匙和一些传送门,一个传送门会单向地创造一条 ...
- [Codeforces]856C - Eleventh Birthday
题目大意:给出n个数,问有多少种排列把数字接起来是11的倍数.(n<=2000) 做法:一个数后面接一个数等同于乘上10的若干次幂然后加上这个数,10模11等于-1,所以10的若干次幂是-1或1 ...
- UVA11552:Fewest Flops
发现如果只有一块就是种类的数目,也就是同种放在一起, 再考虑多块,如果违背的上面的规律,可以发现不会更优, 于是问题就是求在满足同种类放在一起的前提下,尽量使得相邻块的两端一模一样 然后dp一下就可以 ...
- 【BZOJ1835】【ZJOI2010】基站选址
原题传送门 Description 有N个村庄坐落在一条直线上,第i(i>1)个村庄距离第1个村庄的距离为Di.需要在这些村庄中建立不超过K个通讯基站,在第i个村庄建立基站的费用为Ci.如果在距 ...