用eclipce编写 MR程序 MapReduce

package com.bw.mr; import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; // yarn mr--->Mapper map Reducer reduce
// Mapper:四个泛型
//keyin :Map端输入的K值 keyin :偏移量
// hello word hello tom hello jim
//hello word 9 (hello word) String
// hello tom 17( hello tom)
// hello jim .....
//valuein: word
// hadoop 的api writeable
// keyout valueout ----> k(单词)
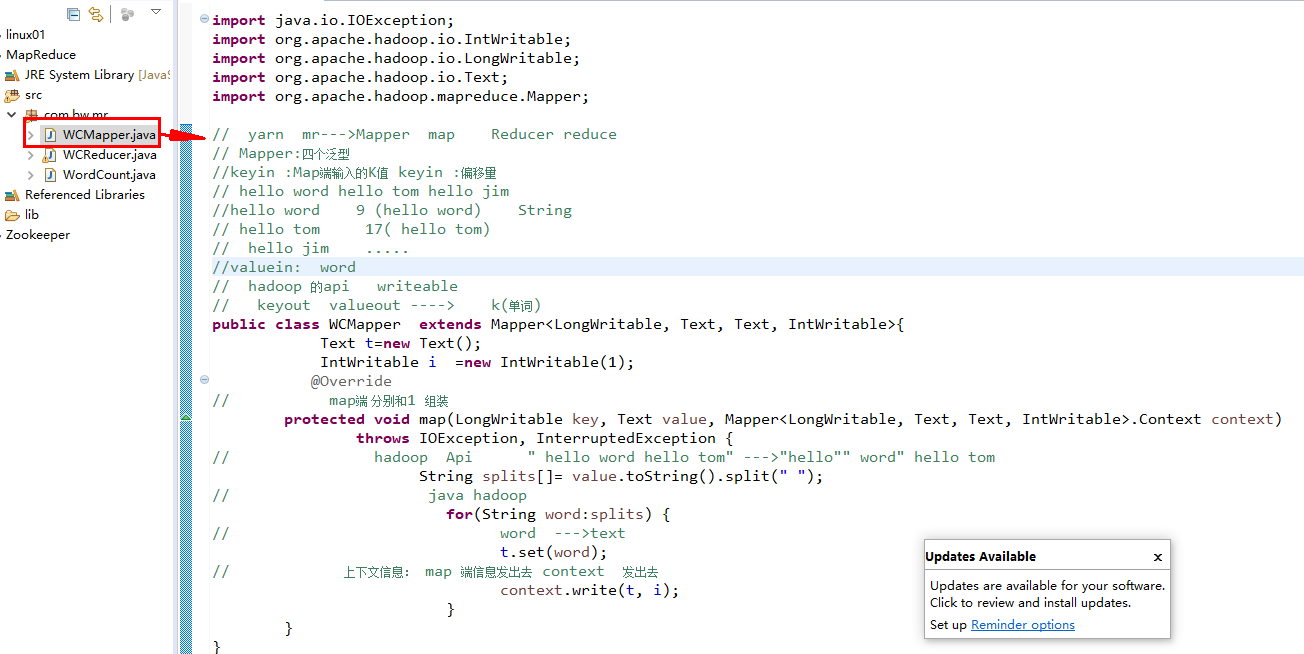
public class WCMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
Text t=new Text();
IntWritable i =new IntWritable(1);
@Override
// map端 分别和1 组装
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
// hadoop Api " hello word hello tom" --->"hello"" word" hello tom
String splits[]= value.toString().split(" ");
// java hadoop
for(String word:splits) {
// word --->text
t.set(word);
// 上下文信息: map 端信息发出去 context 发出去
context.write(t, i);
}
}
}
package com.bw.mr; import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; // Mr :input map reduce output
// reducer reduce hello(1,1,1,1,1)-->hello(1+1+1+...)
// map(LongWriteable,text) --->(text,IntWriteable)\
// reduce (text,IntWriteable) ---->(text,IntWriteable)
// hello(1,1,1,1,1)-->
public class WCReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
// 重写 reduce 方法
@Override
// text :word Iterable (111111111111111)
protected void reduce(Text arg0, Iterable<IntWritable> arg1,
Reducer<Text, IntWritable, Text, IntWritable>.Context arg2) throws IOException, InterruptedException {
// reduce --->归并 ---》 word(1,1,1,1,...)---->word(count)
int count =0;
// 循环 。。。for
for(IntWritable i:arg1) {
count++;
}
// 输出最后 的结果
arg2.write(arg0,new IntWritable(count));
}
}
package com.bw.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
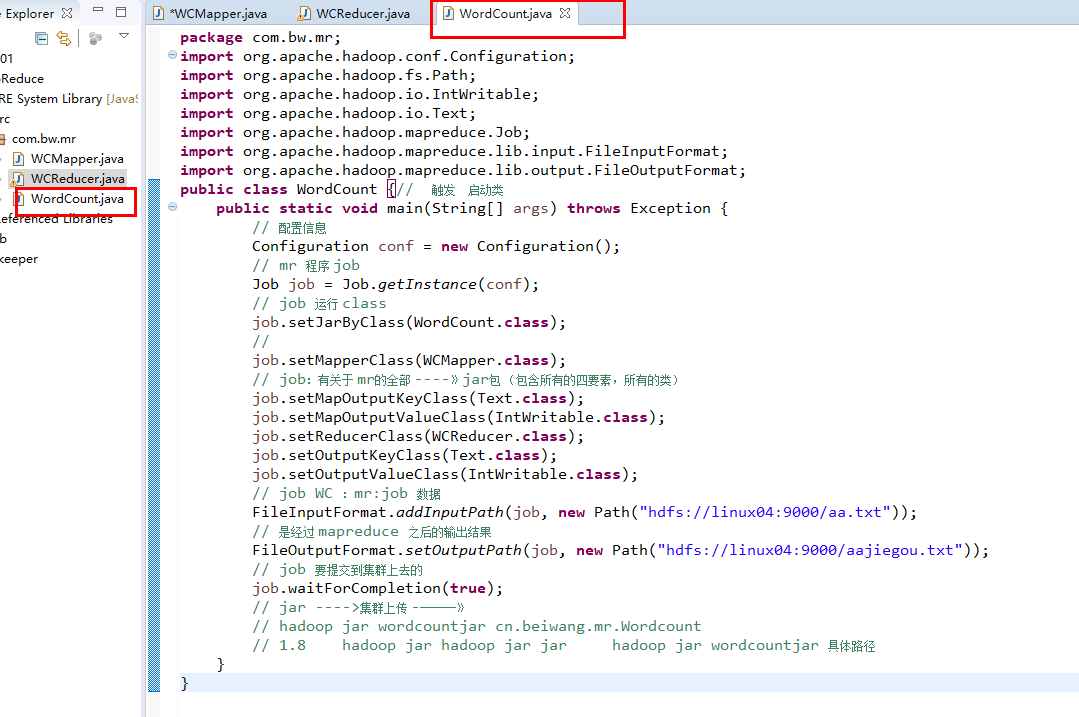
public class WordCount {// 触发 启动类
public static void main(String[] args) throws Exception {
// 配置信息
Configuration conf = new Configuration();
// mr 程序 job
Job job = Job.getInstance(conf);
// job 运行 class
job.setJarByClass(WordCount.class);
//
job.setMapperClass(WCMapper.class);
// job:有关于 mr的全部 ----》jar包 (包含所有的四要素,所有的类)
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(WCReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// job WC :mr:job 数据
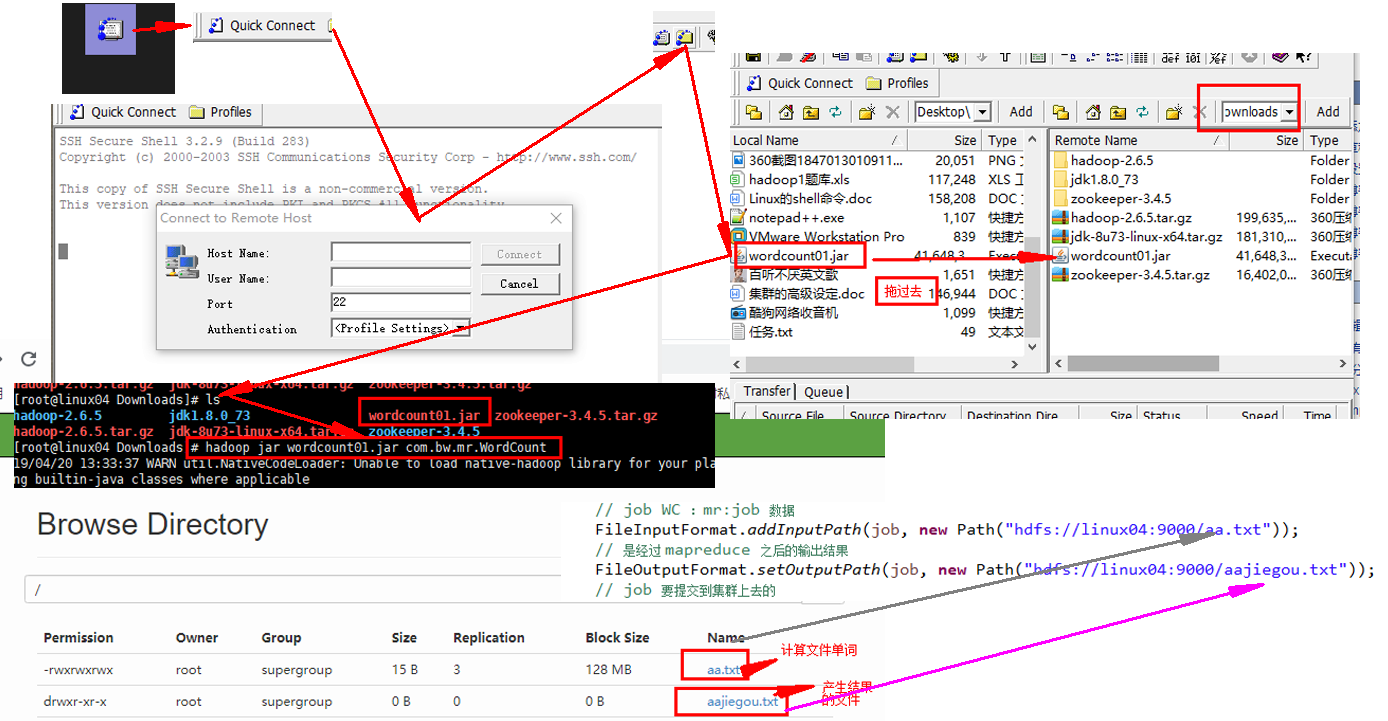
FileInputFormat.addInputPath(job, new Path("hdfs://linux04:9000/aa.txt"));
// 是经过 mapreduce 之后的输出结果
FileOutputFormat.setOutputPath(job, new Path("hdfs://linux04:9000/aajiegou.txt"));
// job 要提交到集群上去的
job.waitForCompletion(true);
// jar ---->集群上传 -————》
// hadoop jar wordcountjar cn.beiwang.mr.Wordcount
// 1.8 hadoop jar hadoop jar jar hadoop jar wordcountjar 具体路径
}
}
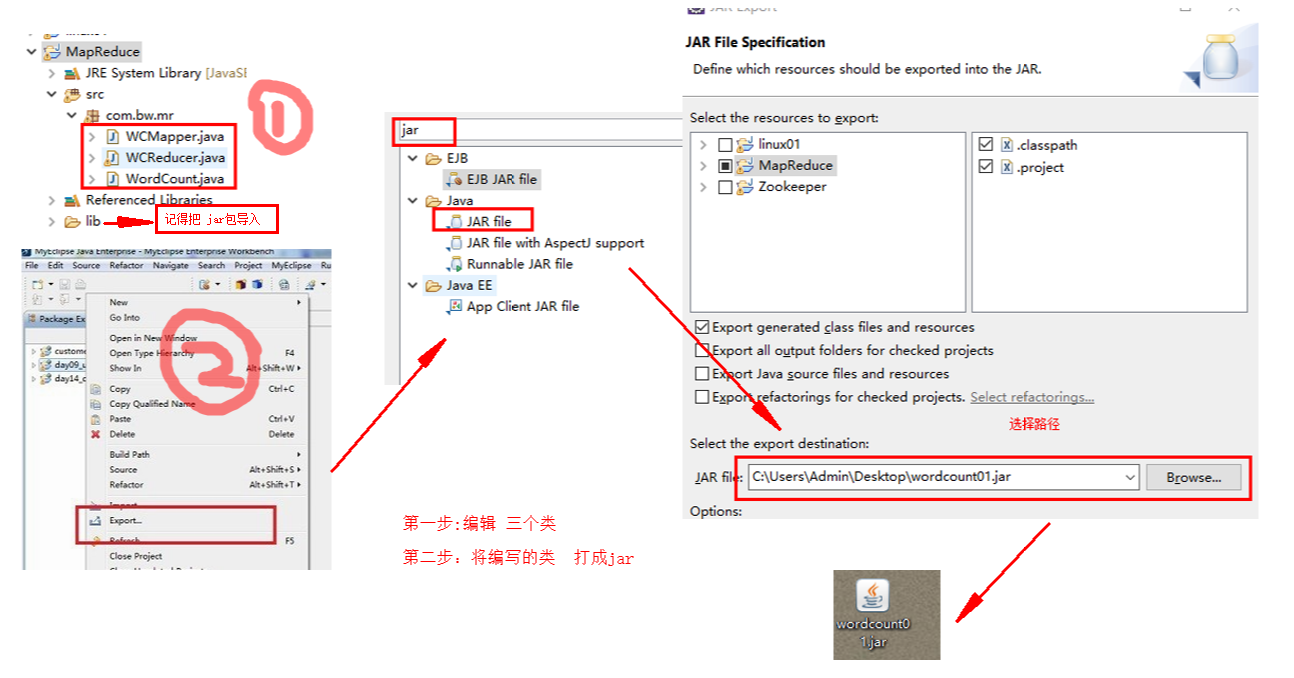
用eclipce编写 MR程序 MapReduce的更多相关文章
- C#码农的大数据之路 - 使用C#编写MR作业
系列目录 写在前面 从Hadoop出现至今,大数据几乎就是Java平台专属一般.虽然Hadoop或Spark也提供了接口可以与其他语言一起使用,但作为基于JVM运行的框架,Java系语言有着天生优势. ...
- 2 weekend110的mapreduce介绍及wordcount + wordcount的编写和提交集群运行 + mr程序的本地运行模式
把我们的简单运算逻辑,很方便地扩展到海量数据的场景下,分布式运算. Map作一些,数据的局部处理和打散工作. Reduce作一些,数据的汇总工作. 这是之前的,weekend110的hdfs输入流之源 ...
- 编写简单的Mapreduce程序并部署在Hadoop2.2.0上运行
今天主要来说说怎么在Hadoop2.2.0分布式上面运行写好的 Mapreduce 程序. 可以在eclipse写好程序,export或用fatjar打包成jar文件. 先给出这个程序所依赖的Mave ...
- Hadoop MapReduce概念学习系列之mr程序组件全貌(二十)
其实啊,spilt是,控制Apache Hadoop Mapreduce的map并发任务数,详细见http://www.cnblogs.com/zlslch/p/5713652.html map,是m ...
- 用PHP编写Hadoop的MapReduce程序
用PHP编写Hadoop的MapReduce程序 Hadoop流 虽然Hadoop是用Java写的,但是Hadoop提供了Hadoop流,Hadoop流提供一个API, 允许用户使用任何语言编 ...
- 一起学Hadoop——使用IDEA编写第一个MapReduce程序(Java和Python)
上一篇我们学习了MapReduce的原理,今天我们使用代码来加深对MapReduce原理的理解. wordcount是Hadoop入门的经典例子,我们也不能免俗,也使用这个例子作为学习Hadoop的第 ...
- 编写一个基于HBase的MR程序,结果遇到一个错:ERROR security.UserGroupInformation - PriviledgedActionException as ,求帮助
环境说明:Ubuntu12.04,使用CDH4.5,伪分布式环境 Hadoop配置如下: core-site.xml: <configuration><property> ...
- Windows下Eclipse提交MR程序到HadoopCluster
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 欢迎转载,转载请注明出处. 以前Eclipse上写好的MapReduce项目经常是打好包上传到Hadoop测试集 ...
- 用python + hadoop streaming 编写分布式程序(一) -- 原理介绍,样例程序与本地调试
相关随笔: Hadoop-1.0.4集群搭建笔记 用python + hadoop streaming 编写分布式程序(二) -- 在集群上运行与监控 用python + hadoop streami ...
随机推荐
- HTTP 内容编码,也就这 2 点需要知道 | 实用 HTTP
Hi,大家好,我是承香墨影! HTTP 协议在网络知识中占据了重要的地位,HTTP 协议最基础的就是请求和响应的报文,而报文又是由报文头(Header)和实体组成.大多数 Http 协议的使用方式,都 ...
- 【Android Studio安装部署系列】六、在模拟器上运行项目
版权声明:本文为HaiyuKing原创文章,转载请注明出处! 概述 在模拟器上运行项目的步骤.不过在实际开发中,一般不采用这种方式,因为影响电脑的运行,所以一般使用真机运行项目. 运行项目 创建模拟器 ...
- 试试使用 eolinker 扫描 GitLab 代码注释自动生成 API 文档?
前言: 一般写完代码之后,还要将各类参数注解写入API文档,方便后续进行对接和测试,这个过程通常都很麻烦,如果有工具可以读取代码注释直接生成API文档的话,那会十分方便. 此前一直都是在使用eolin ...
- 贝塞尔曲线控件 for .NET (EN)
Conmajia 2012 Updated on Feb. 18, 2018 In Photoshop, there is a very powerful feature Curve Adjust, ...
- Cayley图数据库的可视化(Visualize)
引入 在文章Cayley图数据库的简介及使用中,我们已经了解了Cayley图数据库的安装.数据导入以及进行查询等. Cayley图数据库是Google开发的开源图数据库,虽然功能还没有Neo4 ...
- .net core api +swagger(一个简单的入门demo 使用codefirst+mysql)
前言: 自从.net core问世之后,就一直想了解.但是由于比较懒惰只是断断续续了解一点.近段时间工作不是太忙碌,所以偷闲写下自己学习过程.慢慢了解.net core 等这些基础方面学会之后再用.n ...
- VS code 设置中文后也显示英文的问题
按f1 搜索 Configore Display Language 设置 zh-cn 关闭软件重启. 如果重启菜单等还是英文的,在商店查看已安装的插件,把中文插件重新安装一遍,然后重启软件.
- mysql 盲注二分法python脚本
import urllib import urllib2 def doinject(payload): url = 'xxxxxxxxxxxxxxxxxxxxx' values = {'injecti ...
- C#之使类型参数--泛型
1.泛型是什么 泛型的就是“通用类型”,它可以代替任何的数据类型,使类型参数化,从而达到只实现一个方法就可以操作多种数据类型的目的. 2.为什么使用泛型 举一个比较两个数大小的例子: 以上例子实现in ...
- LIS3DH三轴加速度计-实现欧拉角(俯仰角,横滚角)
1. LIS3DH管脚定义 PS:LIS3DH和mpu6050的X和Y方向是相反的, mpu6050如下图所示: 2.LIS3DH加速度计介绍 由于LIS3DH只可以得到XYZ加速度,无法获取角速度, ...