爬虫基础(五)-----scrapy框架简介
---------------------------------------------------摆脱穷人思维 <五> :拓展自己的视野,适当做一些眼前''无用''的事情,防止进入只关注当下的''管窥''状态,建立长远规划的战略.
一 scrapy框架简介
1 介绍
(1) 什么是Scrapy?
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍。所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等)的具有很强通用性的项目模板。对于框架的学习,重点是要学习其框架的特性、各个功能的用法即可。
Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速、简单、可扩展的方式从网站中提取所需的数据。但目前Scrapy的用途十分广泛,可用于如数据挖掘、监测和自动化测试等领域,也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy 是基于twisted框架开发而来,twisted是一个流行的事件驱动的python网络框架。因此Scrapy使用了一种非阻塞(又名异步)的代码来实现并发。
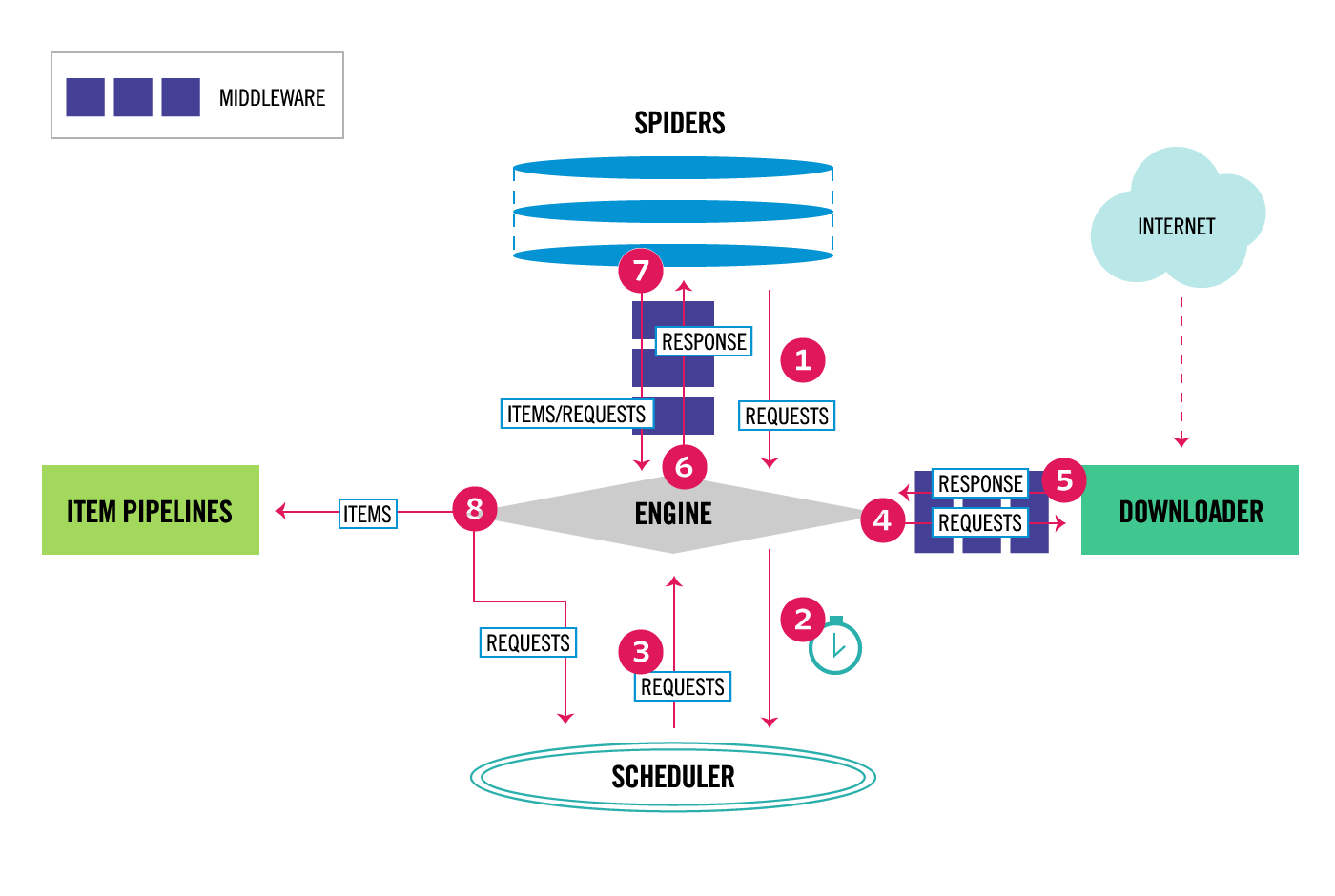
整体架构大致如下:
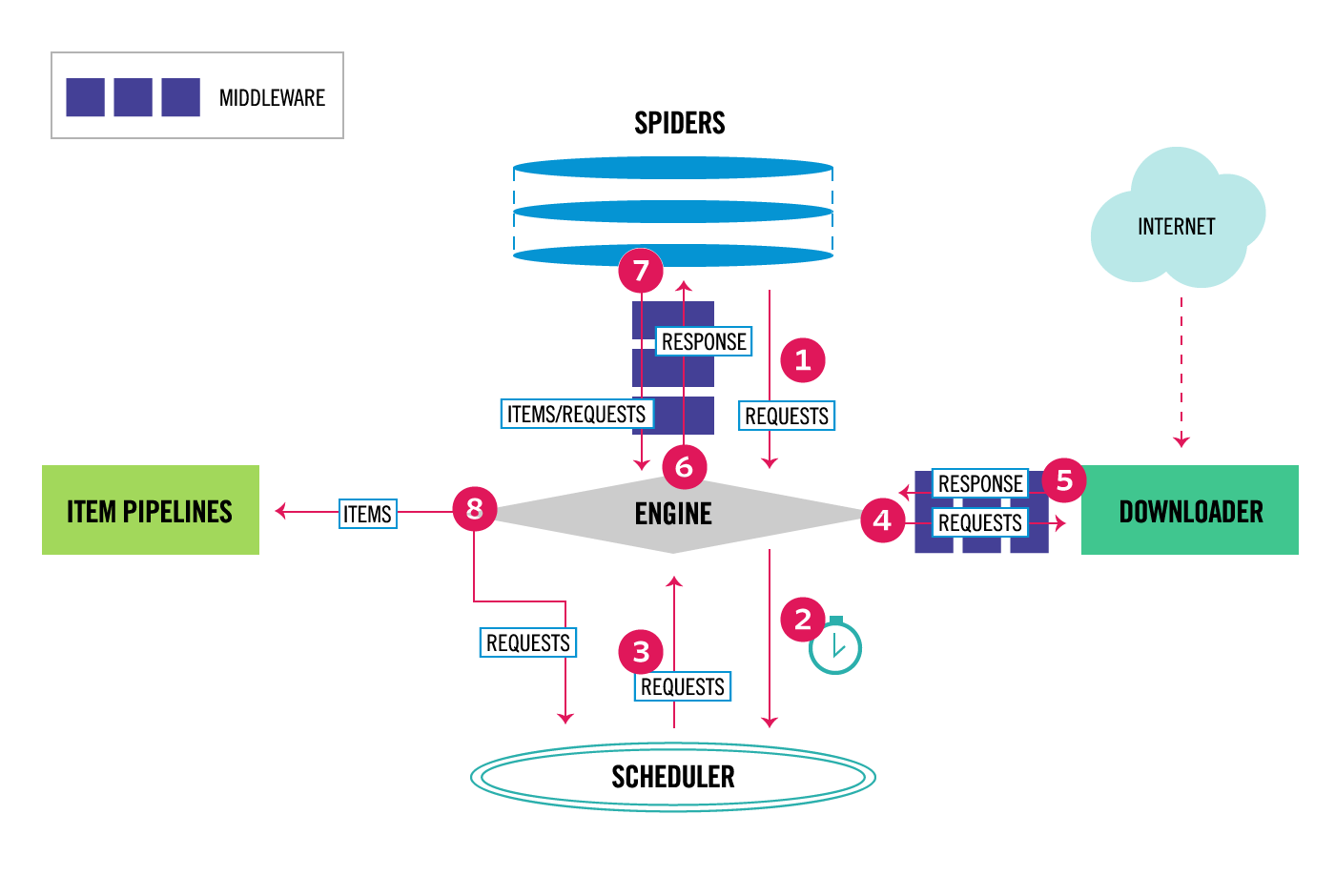

'''
Components: 1、引擎(EGINE)
引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件。有关详细信息,请参见上面的数据流部分。 2、调度器(SCHEDULER)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL的优先级队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
3、下载器(DOWLOADER)
用于下载网页内容, 并将网页内容返回给EGINE,下载器是建立在twisted这个高效的异步模型上的
4、爬虫(SPIDERS)
SPIDERS是开发人员自定义的类,用来解析responses,并且提取items,或者发送新的请求
5、项目管道(ITEM PIPLINES)
在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作
下载器中间件(Downloader Middlewares)位于Scrapy引擎和下载器之间,主要用来处理从EGINE传到DOWLOADER的请求request,已经从DOWNLOADER传到EGINE的响应response,
你可用该中间件做以下几件事:
(1) process a request just before it is sent to the Downloader (i.e. right before Scrapy sends the request to the website);
(2) change received response before passing it to a spider;
(3) send a new Request instead of passing received response to a spider;
(4) pass response to a spider without fetching a web page;
(5) silently drop some requests.
6、爬虫中间件(Spider Middlewares)
位于EGINE和SPIDERS之间,主要工作是处理SPIDERS的输入(即responses)和输出(即requests)
'''
2 安装
#Linux:
pip3 install scrapy
#Windows:
a. pip3 install wheel
b. 下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
c. 进入下载目录,执行 pip3 install Twisted‑17.1.0‑cp35‑cp35m‑win_amd64.whl
d. pip3 install pywin32
e. pip3 install scrapy
3 命令行工具
# 1 查看帮助
scrapy -h
scrapy <command> -h # 2 有两种命令:其中Project-only必须切到项目文件夹下才能执行,而Global的命令则不需要
Global commands:
startproject #创建项目
genspider #创建爬虫程序
settings #如果是在项目目录下,则得到的是该项目的配置
runspider #运行一个独立的python文件,不必创建项目
shell #scrapy shell url地址 在交互式调试,如选择器规则正确与否
fetch #独立于程单纯地爬取一个页面,可以拿到请求头
view #下载完毕后直接弹出浏览器,以此可以分辨出哪些数据是ajax请求
version #scrapy version 查看scrapy的版本,scrapy version -v查看scrapy依赖库的版本
Project-only commands:
crawl #运行爬虫,必须创建项目才行,确保配置文件中ROBOTSTXT_OBEY = False
check #检测项目中有无语法错误
list #列出项目中所包含的爬虫名
edit #编辑器,一般不用
parse #scrapy parse url地址 --callback 回调函数 #以此可以验证我们的回调函数是否正确
bench #scrapy bentch压力测试 # 3 官网链接
https://docs.scrapy.org/en/latest/topics/commands.html
4 目录结构
'''
project_name/
scrapy.cfg
project_name/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
爬虫1.py
爬虫2.py
爬虫3.py '''
文件说明:
- scrapy.cfg 项目的主配置信息,用来部署scrapy时使用,爬虫相关的配置信息在settings.py文件中。
- items.py 设置数据存储模板,用于结构化数据,如:Django的Model
- pipelines 数据处理行为,如:一般结构化的数据持久化
- settings.py 配置文件,如:递归的层数、并发数,延迟下载等。强调:配置文件的选项必须大写否则视为无效,正确写法USER_AGENT='xxxx'
- spiders 爬虫目录,如:创建文件,编写爬虫规则
注意:
1、一般创建爬虫文件时,以网站域名命名
2、默认只能在终端执行命令,为了更便捷操作:
|
1
2
3
|
#在项目根目录下新建:entrypoint.pyfrom scrapy.cmdline import executeexecute(['scrapy', 'crawl', 'xiaohua']) |
框架基础:spider类,选择器
5 牛刀小试
1.创建爬虫应用程序
|
1
2
|
cd project_name(进入项目目录)scrapy genspider 应用名称 爬取网页的起始url (例如:scrapy genspider qiubai www.qiushibaike.com) |
2 编写爬虫文件:在步骤2执行完毕后,会在项目的spiders中生成一个应用名的py爬虫文件,文件源码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
# -*- coding: utf-8 -*-import scrapyclass QiubaiSpider(scrapy.Spider): name = 'qiubai' #应用名称 #允许爬取的域名(如果遇到非该域名的url则爬取不到数据) allowed_domains = ['https://www.qiushibaike.com/'] #起始爬取的url start_urls = ['https://www.qiushibaike.com/'] #访问起始URL并获取结果后的回调函数,该函数的response参数就是向起始的url发送请求后,获取的响应对象.该函数返回值必须为可迭代对象或者NUll def parse(self, response): print(response.text) #获取字符串类型的响应内容 print(response.body)#获取字节类型的相应内容 |
3 设置修改settings.py配置文件相关配置
|
1
2
3
4
|
修改内容及其结果如下:19行:USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36' #伪装请求载体身份22行:ROBOTSTXT_OBEY = False #可以忽略或者不遵守robots协议 |
4 执行爬虫程序:
|
1
|
scrapy crawl 应用名称 |
5 将糗百首页中段子的内容和标题进行爬取
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
# -*- coding: utf-8 -*-import scrapyclass QiubaiSpider(scrapy.Spider): name = 'qiubai' allowed_domains = ['https://www.qiushibaike.com/'] start_urls = ['https://www.qiushibaike.com/'] def parse(self, response): #xpath为response中的方法,可以将xpath表达式直接作用于该函数中 odiv = response.xpath('//div[@id="content-left"]/div') content_list = [] #用于存储解析到的数据 for div in odiv: #xpath函数返回的为列表,列表中存放的数据为Selector类型的数据。我们解析到的内容被封装在了Selector对象中,需要调用extract()函数将解析的内容从Selecor中取出。 author = div.xpath('.//div[@class="author clearfix"]/a/h2/text()')[0].extract() content=div.xpath('.//div[@class="content"]/span/text()')[0].extract() #将解析到的内容封装到字典中 dic={ '作者':author, '内容':content } #将数据存储到content_list这个列表中 content_list.append(dic) return content_list |
执行爬虫程序:
|
1
2
|
scrapy crawl 爬虫名称 :该种执行形式会显示执行的日志信息scrapy crawl 爬虫名称 --nolog:该种执行形式不会显示执行的日志信息 |
二 Spider类
Spiders是定义如何抓取某个站点(或一组站点)的类,包括如何执行爬行(即跟随链接)以及如何从其页面中提取结构化数据(即抓取项目)。换句话说,Spiders是您为特定站点(或者在某些情况下,一组站点)爬网和解析页面定义自定义行为的地方。
'''
1、 生成初始的Requests来爬取第一个URLS,并且标识一个回调函数
第一个请求定义在start_requests()方法内默认从start_urls列表中获得url地址来生成Request请求,
默认的回调函数是parse方法。回调函数在下载完成返回response时自动触发 2、 在回调函数中,解析response并且返回值
返回值可以4种:
包含解析数据的字典
Item对象
新的Request对象(新的Requests也需要指定一个回调函数)
或者是可迭代对象(包含Items或Request) 3、在回调函数中解析页面内容
通常使用Scrapy自带的Selectors,但很明显你也可以使用Beutifulsoup,lxml或其他你爱用啥用啥。 4、最后,针对返回的Items对象将会被持久化到数据库
通过Item Pipeline组件存到数据库:https://docs.scrapy.org/en/latest/topics/item-pipeline.html#topics-item-pipeline)
或者导出到不同的文件(通过Feed exports:https://docs.scrapy.org/en/latest/topics/feed-exports.html#topics-feed-exports) '''
三 选择器
为了解释如何使用选择器,我们将使用Scrapy shell(提供交互式测试)和Scrapy文档服务器中的示例页面, 这是它的HTML代码: <html>
<head>
<base href='http://example.com/' />
<title>Example website</title>
</head>
<body>
<div id='images'>
<a href='image1.html'>Name: My image 1 <br /><img src='image1_thumb.jpg' /></a>
<a href='image2.html'>Name: My image 2 <br /><img src='image2_thumb.jpg' /></a>
<a href='image3.html'>Name: My image 3 <br /><img src='image3_thumb.jpg' /></a>
<a href='image4.html'>Name: My image 4 <br /><img src='image4_thumb.jpg' /></a>
<a href='image5.html'>Name: My image 5 <br /><img src='image5_thumb.jpg' /></a>
</div>
</body>
</html> 首先,让我们打开shell: 1 scrapy shell https://doc.scrapy.org/en/latest/_static/selectors-sample1.html
然后,在shell加载之后,您将获得响应作为response shell变量,并在response.selector属性中附加选择器。 让我们构建一个XPath来选择title标签内的文本: >>> response.selector.xpath('//title/text()')
[<Selector (text) xpath=//title/text()>]
使用XPath和CSS查询响应非常常见,响应包括两个便捷快捷方式:response.xpath()和response.css(): >>> response.xpath('//title/text()')
[<Selector (text) xpath=//title/text()>]
>>> response.css('title::text')
[<Selector (text) xpath=//title/text()>]
正如你所看到的,.xpath()并且.css()方法返回一个 SelectorList实例,这是新的选择列表。此API可用于快速选择嵌套数据: >>> response.css('img').xpath('@src').extract()
[u'image1_thumb.jpg',
u'image2_thumb.jpg',
u'image3_thumb.jpg',
u'image4_thumb.jpg',
u'image5_thumb.jpg']
要实际提取文本数据,必须调用selector .extract() 方法,如下所示: >>> response.xpath('//title/text()').extract()
[u'Example website']
如果只想提取第一个匹配的元素,可以调用选择器 .extract_first() >>> response.xpath('//div[@id="images"]/a/text()').extract_first()
u'Name: My image 1 '
现在我们将获得基本URL和一些图像链接: >>> response.xpath('//base/@href').extract()
[u'http://example.com/'] >>> response.css('base::attr(href)').extract()
[u'http://example.com/'] >>> response.xpath('//a[contains(@href, "image")]/@href').extract()
[u'image1.html',
u'image2.html',
u'image3.html',
u'image4.html',
u'image5.html'] >>> response.css('a[href*=image]::attr(href)').extract()
[u'image1.html',
u'image2.html',
u'image3.html',
u'image4.html',
u'image5.html'] >>> response.xpath('//a[contains(@href, "image")]/img/@src').extract()
[u'image1_thumb.jpg',
u'image2_thumb.jpg',
u'image3_thumb.jpg',
u'image4_thumb.jpg',
u'image5_thumb.jpg'] >>> response.css('a[href*=image] img::attr(src)').extract()
[u'image1_thumb.jpg',
u'image2_thumb.jpg',
u'image3_thumb.jpg',
u'image4_thumb.jpg',
u'image5_thumb.jpg']
四 DupeFilter(去重)
默认使用方式:
|
1
2
|
DUPEFILTER_CLASS = 'scrapy.dupefilter.RFPDupeFilter'Request(...,dont_filter=False) ,如果dont_filter=True则告诉Scrapy这个URL不参与去重。 |
源码解析:
|
1
2
|
from scrapy.core.scheduler import Scheduler见Scheduler下的enqueue_request方法:self.df.request_seen(request) |
自定义去重规则:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
from scrapy.dupefilter import RFPDupeFilter,看源码,仿照BaseDupeFilter#步骤一:在项目目录下自定义去重文件dup.pyclass UrlFilter(object): def __init__(self): self.visited = set() #或者放到数据库 @classmethod def from_settings(cls, settings): return cls() def request_seen(self, request): if request.url in self.visited: return True self.visited.add(request.url) def open(self): # can return deferred pass def close(self, reason): # can return a deferred pass def log(self, request, spider): # log that a request has been filtered pass |
五 Item(项目)
抓取的主要目标是从非结构化源(通常是网页)中提取结构化数据。Scrapy蜘蛛可以像Python一样返回提取的数据。虽然方便和熟悉,但P很容易在字段名称中输入拼写错误或返回不一致的数据,尤其是在具有许多蜘蛛的较大项目中。
为了定义通用输出数据格式,Scrapy提供了Item类。 Item对象是用于收集抓取数据的简单容器。它们提供类似字典的 API,并具有用于声明其可用字段的方便语法。
1 声明项目
使用简单的类定义语法和Field 对象声明项。这是一个例子:
|
1
2
3
4
5
6
7
|
import scrapyclass Product(scrapy.Item):name = scrapy.Field()price = scrapy.Field()stock = scrapy.Field()last_updated = scrapy.Field(serializer=str) |
注意那些熟悉Django的人会注意到Scrapy Items被宣告类似于Django Models,除了Scrapy Items更简单,因为没有不同字段类型的概念。
2 项目字段
Field对象用于指定每个字段的元数据。例如,last_updated上面示例中说明的字段的序列化函数。
您可以为每个字段指定任何类型的元数据。Field对象接受的值没有限制。出于同样的原因,没有所有可用元数据键的参考列表。
Field对象中定义的每个键可以由不同的组件使用,只有那些组件知道它。您也可以根据Field自己的需要定义和使用项目中的任何其他键。
Field对象的主要目标是提供一种在一个地方定义所有字段元数据的方法。通常,行为取决于每个字段的那些组件使用某些字段键来配置该行为。
3 使用项目
以下是使用上面声明的Product项目对项目执行的常见任务的一些示例 。您会注意到API与dict API非常相似。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
|
创建项目>>> product = Product(name='Desktop PC', price=1000)>>> print productProduct(name='Desktop PC', price=1000)获取字段值>>> product['name']Desktop PC>>> product.get('name')Desktop PC>>> product['price']1000>>> product['last_updated']Traceback (most recent call last):...KeyError: 'last_updated'>>> product.get('last_updated', 'not set')not set>>> product['lala'] # getting unknown fieldTraceback (most recent call last):...KeyError: 'lala'>>> product.get('lala', 'unknown field')'unknown field'>>> 'name' in product # is name field populated?True>>> 'last_updated' in product # is last_updated populated?False>>> 'last_updated' in product.fields # is last_updated a declared field?True>>> 'lala' in product.fields # is lala a declared field?False设定字段值>>> product['last_updated'] = 'today'>>> product['last_updated']today>>> product['lala'] = 'test' # setting unknown fieldTraceback (most recent call last):...KeyError: 'Product does not support field: lala'访问所有填充值要访问所有填充值,只需使用典型的dict API:>>> product.keys()['price', 'name']>>> product.items()[('price', 1000), ('name', 'Desktop PC')]其他常见任务复制项目:>>> product2 = Product(product)>>> print product2Product(name='Desktop PC', price=1000)>>> product3 = product2.copy()>>> print product3Product(name='Desktop PC', price=1000)从项目创建dicts:>>> dict(product) # create a dict from all populated values{'price': 1000, 'name': 'Desktop PC'}从dicts创建项目:>>> Product({'name': 'Laptop PC', 'price': 1500})Product(price=1500, name='Laptop PC')>>> Product({'name': 'Laptop PC', 'lala': 1500}) # warning: unknown field in dictTraceback (most recent call last):...KeyError: 'Product does not support field: lala' |
4 扩展项目
您可以通过声明原始Item的子类来扩展Items(以添加更多字段或更改某些字段的某些元数据)。
例如:
|
1
2
3
|
class DiscountedProduct(Product): discount_percent = scrapy.Field(serializer=str) discount_expiration_date = scrapy.Field() |
六 Item PipeLine
在一个项目被蜘蛛抓取之后,它被发送到项目管道,该项目管道通过顺序执行的几个组件处理它。
每个项目管道组件(有时简称为“项目管道”)是一个实现简单方法的Python类。他们收到一个项目并对其执行操作,同时决定该项目是否应该继续通过管道或被丢弃并且不再处理。
项目管道的典型用途是:
- cleansing HTML data
- validating scraped data (checking that the items contain certain fields)
- checking for duplicates (and dropping them)
- storing the scraped item in a database
1 编写自己的项目管道
'''
每个项管道组件都是一个必须实现以下方法的Python类: process_item(self,项目,蜘蛛)
为每个项目管道组件调用此方法。process_item() 必须要么:返回带数据的dict,返回一个Item (或任何后代类)对象,返回Twisted Deferred或引发 DropItem异常。丢弃的项目不再由其他管道组件处理。 此外,他们还可以实现以下方法: open_spider(self,蜘蛛)
打开蜘蛛时会调用此方法。 close_spider(self,蜘蛛)
当蜘蛛关闭时调用此方法。 from_crawler(cls,crawler )
如果存在,则调用此类方法以从a创建管道实例Crawler。它必须返回管道的新实例。Crawler对象提供对所有Scrapy核心组件的访问,
如设置和信号; 它是管道访问它们并将其功能挂钩到Scrapy的一种方式。
'''
2 项目管道示例
(1) 价格验证和丢弃物品没有价格
让我们看看下面的假设管道,它调整 price那些不包含增值税(price_excludes_vat属性)的项目的属性,并删除那些不包含价格的项目:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
from scrapy.exceptions import DropItemclass PricePipeline(object): vat_factor = 1.15 def process_item(self, item, spider): if item['price']: if item['price_excludes_vat']: item['price'] = item['price'] * self.vat_factor return item else: raise DropItem("Missing price in %s" % item) |
(2) 将项目写入JSON文件
以下管道将所有已删除的项目(来自所有蜘蛛)存储到一个items.jl文件中,每行包含一个以JSON格式序列化的项目:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
import jsonclass JsonWriterPipeline(object): def open_spider(self, spider): self.file = open('items.jl', 'w') def close_spider(self, spider): self.file.close() def process_item(self, item, spider): line = json.dumps(dict(item)) + "\n" self.file.write(line) return item |
注意JsonWriterPipeline的目的只是介绍如何编写项目管道。如果您确实要将所有已删除的项目存储到JSON文件中,则应使用Feed导出。
(3) 将项目写入数据库
在这个例子中,我们将使用pymongo将项目写入MongoDB。MongoDB地址和数据库名称在Scrapy设置中指定; MongoDB集合以item类命名。
这个例子的要点是展示如何使用from_crawler() 方法以及如何正确地清理资源:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
import pymongoclass MongoPipeline(object): collection_name = 'scrapy_items' def __init__(self, mongo_uri, mongo_db): self.mongo_uri = mongo_uri self.mongo_db = mongo_db @classmethod def from_crawler(cls, crawler): return cls( mongo_uri=crawler.settings.get('MONGO_URI'), mongo_db=crawler.settings.get('MONGO_DATABASE', 'items') ) def open_spider(self, spider): self.client = pymongo.MongoClient(self.mongo_uri) self.db = self.client[self.mongo_db] def close_spider(self, spider): self.client.close() def process_item(self, item, spider): self.db[self.collection_name].insert_one(dict(item)) return item |
(4) 重复过滤
一个过滤器,用于查找重复项目,并删除已处理的项目。假设我们的项目具有唯一ID,但我们的蜘蛛会返回具有相同ID的多个项目:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
from scrapy.exceptions import DropItemclass DuplicatesPipeline(object): def __init__(self): self.ids_seen = set() def process_item(self, item, spider): if item['id'] in self.ids_seen: raise DropItem("Duplicate item found: %s" % item) else: self.ids_seen.add(item['id']) return item |
3 激活项目管道组件
要激活Item Pipeline组件,必须将其类添加到 ITEM_PIPELINES设置中,如下例所示:
|
1
2
3
4
|
ITEM_PIPELINES = { 'myproject.pipelines.PricePipeline': 300, 'myproject.pipelines.JsonWriterPipeline': 800,} |
您在此设置中为类分配的整数值决定了它们运行的顺序:项目从较低值到较高值类进行。习惯上在0-1000范围内定义这些数字。
七 下载中间件
class MyDownMiddleware(object):
def process_request(self, request, spider):
"""
请求需要被下载时,经过所有下载器中间件的process_request调用
:param request:
:param spider:
:return:
None,继续后续中间件去下载;
Response对象,停止process_request的执行,开始执行process_response
Request对象,停止中间件的执行,将Request重新调度器
raise IgnoreRequest异常,停止process_request的执行,开始执行process_exception
"""
pass def process_response(self, request, response, spider):
"""
spider处理完成,返回时调用
:param response:
:param result:
:param spider:
:return:
Response 对象:转交给其他中间件process_response
Request 对象:停止中间件,request会被重新调度下载
raise IgnoreRequest 异常:调用Request.errback
"""
print('response1')
return response def process_exception(self, request, exception, spider):
"""
当下载处理器(download handler)或 process_request() (下载中间件)抛出异常
:param response:
:param exception:
:param spider:
:return:
None:继续交给后续中间件处理异常;
Response对象:停止后续process_exception方法
Request对象:停止中间件,request将会被重新调用下载
"""
return None
八 基于scrapy-redis实现分布式爬虫
Scrapy-Redis则是一个基于Redis的Scrapy分布式组件。它利用Redis对用于爬取的请求(Requests)进行存储和调度(Schedule),并对爬取产生的项目(items)存储以供后续处理使用。scrapy-redi重写了scrapy一些比较关键的代码,将scrapy变成一个可以在多个主机上同时运行的分布式爬虫。
单机玩法:
按照正常流程就是大家都会进行重复的采集;我们都知道进程之间内存中的数据不可共享的,那么你在开启多个Scrapy的时候,它们相互之间并不知道对方采集了些什么那些没有没采集。那就大家伙儿自己玩自己的了。完全没没有效率的提升啊!
怎么解决呢?
这就是我们Scrapy-Redis解决的问题了,不能协作不就是因为请求和去重这两个不能共享吗?
那我把这两个独立出来好了。
将Scrapy中的调度器组件独立放到大家都能访问的地方不就OK啦!加上scrapy,Redis的后流程图就应该变成这样了
分布式玩法:

1 redis连接
配置scrapy使用redis提供的共享去重队列 # 在settings.py中配置链接Redis
REDIS_HOST = 'localhost' # 主机名
REDIS_PORT = 6379 # 端口
REDIS_URL = 'redis://user:pass@hostname:9001' # 连接URL(优先于以上配置)
REDIS_PARAMS = {} # Redis连接参数
REDIS_PARAMS['redis_cls'] = 'myproject.RedisClient' # 指定连接Redis的Python模块
REDIS_ENCODING = "utf-8" # redis编码类型
# 默认配置:\python3.6\Lib\site-packages\scrapy_redis\defaults.py
2 dupefilter
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
#使用scrapy-redis提供的去重功能,查看源码会发现是基于Redis的集合实现的 # 需要指定Redis中集合的key名,key=存放不重复Request字符串的集合
DUPEFILTER_KEY = 'dupefilter:%(timestamp)s'
#源码:dupefilter.py内一行代码key = defaults.DUPEFILTER_KEY % {'timestamp': int(time.time())}
3 Scheduler
#1、源码:\python3.6\Lib\site-packages\scrapy_redis\scheduler.py #2、settings.py配置 # Enables scheduling storing requests queue in redis.
SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 调度器将不重复的任务用pickle序列化后放入共享任务队列,默认使用优先级队列(默认),其他:PriorityQueue(有序集合),FifoQueue(列表)、LifoQueue(列表)
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue' # 对保存到redis中的request对象进行序列化,默认使用pickle
SCHEDULER_SERIALIZER = "scrapy_redis.picklecompat" # 调度器中请求任务序列化后存放在redis中的key
SCHEDULER_QUEUE_KEY = '%(spider)s:requests' # 是否在关闭时候保留原来的调度器和去重记录,True=保留,False=清空
SCHEDULER_PERSIST = True # 是否在开始之前清空 调度器和去重记录,True=清空,False=不清空
SCHEDULER_FLUSH_ON_START = False # 去调度器中获取数据时,如果为空,最多等待时间(最后没数据,未获取到)。如果没有则立刻返回会造成空循环次数过多,cpu占用率飙升
SCHEDULER_IDLE_BEFORE_CLOSE = 10 # 去重规则,在redis中保存时对应的key
SCHEDULER_DUPEFILTER_KEY = '%(spider)s:dupefilter' # 去重规则对应处理的类,将任务request_fingerprint(request)得到的字符串放入去重队列
SCHEDULER_DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter'
3 RedisPipeline(持久化)
ITEM_PIPELINES = { 'scrapy_redis.pipelines.RedisPipeline': 300, }
#将item持久化到redis时,指定key和序列化函数
REDIS_ITEMS_KEY = '%(spider)s:items'
REDIS_ITEMS_SERIALIZER = 'json.dumps'
4 从Redis中获取起始URL
scrapy程序爬取目标站点,一旦爬取完毕后就结束了,如果目标站点更新内容了,我们想重新爬取,那么只能再重新启动scrapy,非常麻烦
scrapy-redis提供了一种供,让scrapy从redis中获取起始url,如果没有scrapy则过一段时间再来取而不会关闭
这样我们就只需要写一个简单的脚本程序,定期往redis队列里放入一个起始url。 #具体配置如下 #1、编写爬虫时,起始URL从redis的Key中获取
REDIS_START_URLS_KEY = '%(name)s:start_urls' #2、获取起始URL时,去集合中获取还是去列表中获取?True,集合;False,列表
REDIS_START_URLS_AS_SET = False # 获取起始URL时,如果为True,则使用self.server.spop;如果为False,则使用self.server.lpop
九 项目代码
爬虫基础(五)-----scrapy框架简介的更多相关文章
- 爬虫开发7.scrapy框架简介和基础应用
scrapy框架简介和基础应用阅读量: 1432 scrapy 今日概要 scrapy框架介绍 环境安装 基础使用 今日详情 一.什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数 ...
- 第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码
第三百三十五节,web爬虫讲解2—Scrapy框架爬虫—豆瓣登录与利用打码接口实现自动识别验证码 打码接口文件 # -*- coding: cp936 -*- import sys import os ...
- 5、爬虫系列之scrapy框架
一 scrapy框架简介 1 介绍 (1) 什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性能 ...
- 爬虫系列之Scrapy框架
一 scrapy框架简介 1 介绍 (1) 什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性能 ...
- 第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令
第三百三十一节,web爬虫讲解2—Scrapy框架爬虫—Scrapy安装—Scrapy指令 Scrapy框架安装 1.首先,终端执行命令升级pip: python -m pip install --u ...
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
- 第三百三十三节,web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录—获取Scrapy框架Cookies
第三百三十三节,web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录 模拟浏览器登录 start_requests()方法,可以返回一个请求给爬虫的起始网站,这个返回的请求相当于star ...
- 第三百三十二节,web爬虫讲解2—Scrapy框架爬虫—Scrapy使用
第三百三十二节,web爬虫讲解2—Scrapy框架爬虫—Scrapy使用 xpath表达式 //x 表示向下查找n层指定标签,如://div 表示查找所有div标签 /x 表示向下查找一层指定的标签 ...
- Python爬虫进阶之Scrapy框架安装配置
Python爬虫进阶之Scrapy框架安装配置 初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此 ...
随机推荐
- Linux下查看文件内容的命令和工具
1.catcat命令主要用来查看文件内容,创建文件,合并文件,追加文件等. 1.1.查看文件 格式:cat 文件名称 说明:这条命令会把文件内容全部输出到显示屏上. cat -n 文件名称:查看文件内 ...
- python列表的交、并、差集
#!/usr/bin/env python3 l1 = ['] l2 = ['] # 交集 result1 = [i for i in l1 if i in l2] result2 = list(se ...
- Vue(day4)
这里说的Vue中的路由是指前端路由,与后端路由有所区别.我们可以使用url来获取服务器的资源,而这种url与资源的映射关系就是我们所说的路由.对于单页面程序来说,我们使用url时常常通过hash的方法 ...
- LindDotNetCore~职责链模式的应用
回到目录 职责链模式 它是一种设计模块,主要将操作流程与具体操作解耦,让每个操作都可以设置自己的操作流程,这对于工作流应用是一个不错的选择! 下面是官方标准的定义:责任链模式是一种设计模式.在责任链模 ...
- Springboot整合Elastic-Job
Elastic-Job是当当网的任务调度开源框架,有以下功能 分布式调度协调 弹性扩容缩容 失效转移 错过执行作业重触发 作业分片一致性,保证同一分片在分布式环境中仅一个执行实例 自诊断并修复分布式不 ...
- 微信公众号开发C#系列-10、长链接转短链接
1.概述 短网址的好处众多,便于记忆,占用字符少等,现在市面上出现了众多的将长网址转变为短网址的方法,但是由于他们都是小的公司在幕后运营,所以很不靠谱,面对随时关闭服务的可能,这样也导致我们将转换好了 ...
- centos7 python3 pip
pip of python3 installed is play well with Django and spider. #安装pip可以很好的使用django和爬虫 wget https:// ...
- 详解MySQL表空间以及ibdata1文件过大问题
ibdata1文件过大 原因分析 ibdata1是一个用来构建innodb系统表空间的文件,关于系统表空间详细介绍参考MySQL官网文档 上面是一个数据库的ibdata1文件,达到了780多G,而且还 ...
- 简述C#中IO的应用
在.NET Framework 中. System.IO 命名空间主要包含基于文件(和基于内存)的输入输出(I/O)服务的相关基础类库.和其他命名空间一样. System.IO 定义了一系列类.接口. ...
- 了解spring
一.spring简介 Spring是一个JavaEE轻量级的一站式的开发框架(spring的可插拔特性,企业用于整合其他框架)轻量级:使用最少的代码启动程序,根据所需选择功能选择模块使用一站式:提供了 ...