使用sklearn进行数据挖掘-房价预测(1)
使用sklearn进行数据挖掘系列文章:
- 1.使用sklearn进行数据挖掘-房价预测(1)
- 2.使用sklearn进行数据挖掘-房价预测(2)—划分测试集
- 3.使用sklearn进行数据挖掘-房价预测(3)—绘制数据的分布
- 4.使用sklearn进行数据挖掘-房价预测(4)—数据预处理
- 5.使用sklearn进行数据挖掘-房价预测(5)—训练模型
- 6.使用sklearn进行数据挖掘-房价预测(6)—模型调优
前言##
sklearn是比较流行的机器学习工具包,想必很多人都或多或少使用过,但完整的去处理数据挖掘的流程可能还需要去加强。本文将根据实际案例,利用sklearn进行一次完整的数据挖掘案例分析,通过本文的学习,将会对数据挖掘流程进行了解,以及机器学习算法的使用,模型的调参等,希望对你有帮助。
使用的数据为加利福尼亚的房价数据,数据来自加利福尼亚州人口普查,收录了20640条样本。数据包含的属性有 longitude,latitude,housing_median_age,total_rooms,total_bedrooms,population,households(家庭人数),median_income,median_house_value,ocean_proximity,其中mdeia_houese_value是我们的目标(需要预测)变量。
查看数据###
首先使用pandas加载数据
import pandas as pd
def load_housing_data():
return pd.read_csv('housing.csv')
使用pandas提供的head方法查看数据
housing = load_housing_data()
housing.head

从图中可以看出,本数据集总共包含10个特征,9个为数值类型,1个为标签类型。使用housing.info()方法能够查看数据集各个特征的详细信息
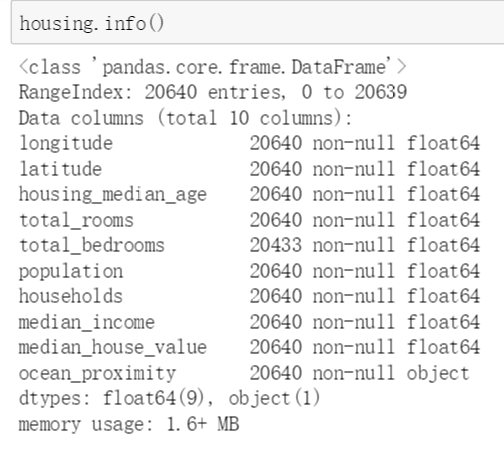
本数据集包含20640个样本,算是一个比较小的数据集了。total_bedrooms只有20433个非空样本,也就意味着有207个样本这一特征数据缺失。使用describe()方法查看数据集的详细信息。
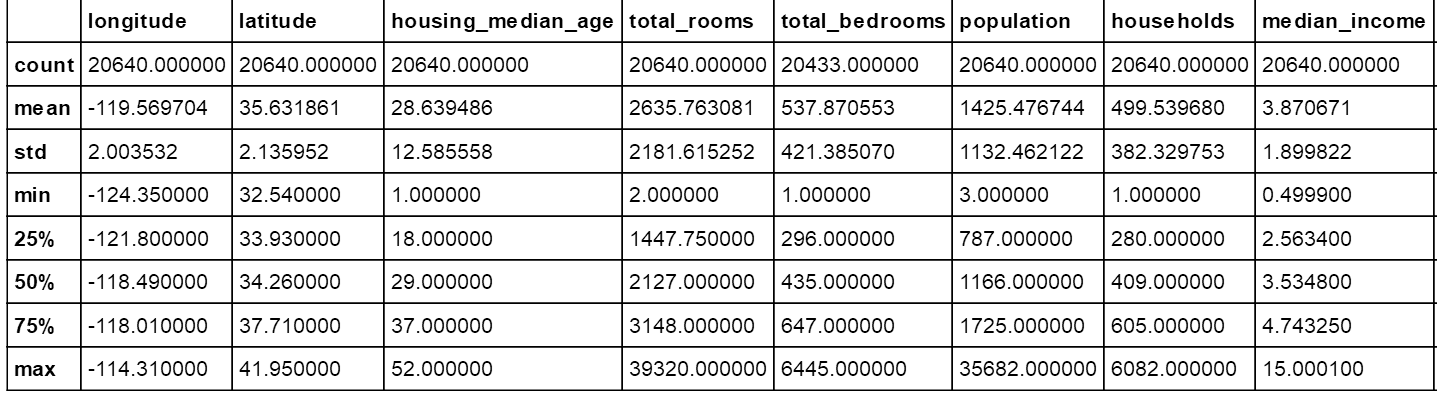
强大的pandas给出了数值类型特征的数值信息,std是标准差,表示数据集的分布广度;三个百分数25、50、75是四分位点,熟悉箱线图的朋友应该知道。例如housing_median_age这一特征,大约有25%的样本小于18、50%的小于29。
对于标称类型特征查看其取值类型
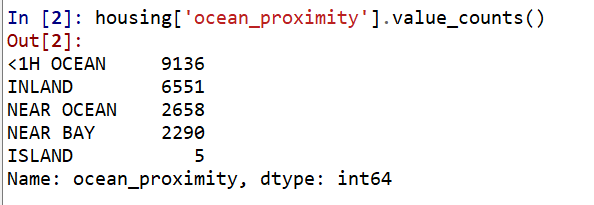
人们对于数值或许不够敏感,从上面的系列表格看不出数据的特点,那么我们可以通过绘制直方图的形式将特征的数值分布展示出来
import matplotlib.pyplot as plt
housing.hist(bins=50,figsize=(15,10))#bins 柱子个数
#plt.savefig('a.jpg') #保存图片
plt.show()
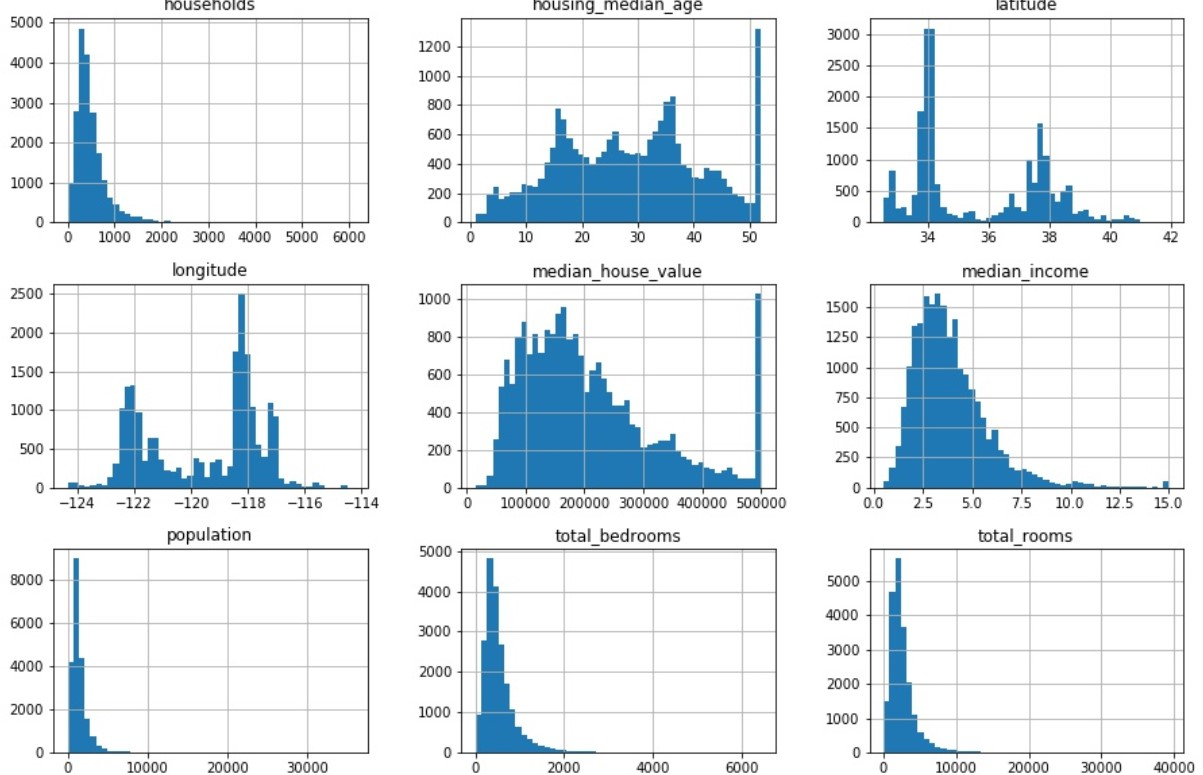
从上图中我们可以得出以下结论:
- 1.发现media income这一维度的值被缩放到[0.5,15]范围区间内,数值的放缩经常被用到机器学习任务中。
- 2.house media age 和 media house value这两个维度也是被缩放过的,其中
media house value是我们的目标属性。 - 3.不同的特征有着不同的尺度(scale),在后面的部分我们将对特征缩放进行讨论。
- 4.从上面的图可以看出,特征趋向于长尾分布,在机器学习任务中我们更加希望特征的分布趋近于正态分布。我们将使用一些方法对这些特征进行转换
使用sklearn进行数据挖掘-房价预测(1)的更多相关文章
- 使用sklearn进行数据挖掘-房价预测(4)—数据预处理
在使用机器算法之前,我们先把数据做下预处理,先把特征和标签拆分出来 housing = strat_train_set.drop("median_house_value",axis ...
- 使用sklearn进行数据挖掘-房价预测(6)—模型调优
通过上一节的探索,我们会得到几个相对比较满意的模型,本节我们就对模型进行调优 网格搜索 列举出参数组合,直到找到比较满意的参数组合,这是一种调优方法,当然如果手动选择并一一进行实验这是一个十分繁琐的工 ...
- 使用sklearn进行数据挖掘-房价预测(2)—划分测试集
使用sklearn进行数据挖掘系列文章: 1.使用sklearn进行数据挖掘-房价预测(1) 2.使用sklearn进行数据挖掘-房价预测(2)-划分测试集 3.使用sklearn进行数据挖掘-房价预 ...
- 使用sklearn进行数据挖掘-房价预测(3)—绘制数据的分布
使用sklearn进行数据挖掘系列文章: 1.使用sklearn进行数据挖掘-房价预测(1) 2.使用sklearn进行数据挖掘-房价预测(2)-划分测试集 3.使用sklearn进行数据挖掘-房价预 ...
- 使用sklearn进行数据挖掘-房价预测(5)—训练模型
使用sklearn进行数据挖掘系列文章: 1.使用sklearn进行数据挖掘-房价预测(1) 2.使用sklearn进行数据挖掘-房价预测(2)-划分测试集 3.使用sklearn进行数据挖掘-房价预 ...
- 基于sklearn的波士顿房价预测_线性回归学习笔记
> 以下内容是我在学习https://blog.csdn.net/mingxiaod/article/details/85938251 教程时遇到不懂的问题自己查询并理解的笔记,由于sklear ...
- 第十三次作业——回归模型与房价预测&第十一次作业——sklearn中朴素贝叶斯模型及其应用&第七次作业——numpy统计分布显示
第十三次作业——回归模型与房价预测 1. 导入boston房价数据集 2. 一元线性回归模型,建立一个变量与房价之间的预测模型,并图形化显示. 3. 多元线性回归模型,建立13个变量与房价之间的预测模 ...
- 转载:使用sklearn进行数据挖掘
目录 1 使用sklearn进行数据挖掘 1.1 数据挖掘的步骤 1.2 数据初貌 1.3 关键技术2 并行处理 2.1 整体并行处理 2.2 部分并行处理3 流水线处理4 自动化调参5 持久化6 回 ...
- Ames房价预测特征工程
最近学人工智能,讲到了Kaggle上的一个竞赛任务,Ames房价预测.本文将描述一下数据预处理和特征工程所进行的操作,具体代码Click Me. 原始数据集共有特征81个,数值型特征38个,非数值型特 ...
随机推荐
- 【转】RAM 大全-DRAM, SRAM, SDRAM的关系与区别
http://blog.csdn.net/huleide/article/details/5506698 ROM和RAM指的都是半导体存储器,ROM是Read Only Memory的缩写,RAM是R ...
- java中的static关键字详解
static对于我们这些初学者在编写代码和阅读代码是一个难以理解的关键字,也是大量公司面试题最喜欢考的之一.下面我就来就先讲述一下static关键字的用法和我们初学者容易误解的地方. static关键 ...
- Java规范推荐
Java规范推荐 推荐:http://blog.csdn.net/tristansmile/article/details/7989670 命名规范 项目名:全部小写 Package 的命名:应该都是 ...
- *.do和*.action的区别
最近发现个问题,都是SpringMVC 请求地址有的是*.do有的是*.action,想了半天区别没想出来. struts早期的1版本,以.do为后缀.同时spring的MVC也是以.do为后缀.几年 ...
- yii2之GridView小部件
GridView小部件用于展示多条数据的列表.GridView小部件的使用需要数据提供器即yii\data\ActiveDataProvider的实例作为参数,所以 第一步就是要在控制器方法中创建这个 ...
- ssh更改默认端口号及实现免密码远程登陆
近来在复习防火墙管理工具 iptables 的基本使用方法,涉及到对端口添加或删除防火墙策略的内容,之前对ssh更改默认端口号及免密码登录的方法不熟悉,这次做一个基本的总结防止自己遗忘. 错误偏差及其 ...
- 从零起步学python计划及感想
从纯传统bi转型过来的技术顾问,比较有优势的是对业务的熟悉,对数据有敏感度,熟悉数据模型.但是长年累月基本都是用sql处理问题.目前还没有经历过sql解决不了的问题,一个sql解决不了就用临时表,几个 ...
- 点击下拉,其余不动的jquery事件(转)
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- Vue源码后记-其余内置指令(2)
-- 指令这个讲起来还有点复杂,先把html弄上来: <body> <div id='app'> <div v-if="vIfIter" v-bind ...
- centos 源码安装python
一.准备环境 首先在官网下载想要的python对应版本http//www.python.org/downloads/source 下载tgz就可以了.文件有两种 1,Python-版本号.tgz(解压 ...