Pcb-Merging:无需训练的多任务模型合并方案 | NeurIPS'24
来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: Parameter Competition Balancing for Model Merging

创新点
- 重新审视了现有的模型合并方法,强调参数竞争意识的关键作用。
- 提出了一种名为 \({\tt Pcb-Merging}\) 的新方法,通过平衡参数竞争有效地调整参数系数。
- 提出的方法在各种应用场景中稳定并提升了模型合并性能,无需额外训练。
内容概述
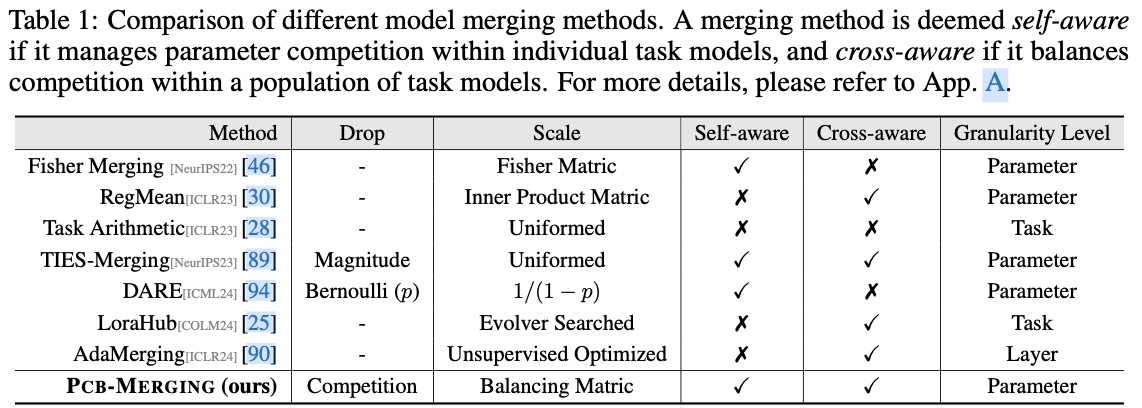
尽管对预训练模型进行微调已成为一种常见做法,但这些模型在其特定领域之外往往表现不佳。最近模型融合技术使得能够将多个经过不同任务微调的模型直接集成到一个模型中,集成模型具备多任务能力而无需在原始数据集上进行重新训练。然而,现有方法在解决任务之间潜在冲突和复杂相关性方面存在不足,特别是在参数级别调整中,造成在不同任务间有效平衡参数竞争的挑战。
论文提出了轻量级且无需训练的创新模型融合技术 \({\tt Pcb-Merging}\) (Parameter Competition Balancing),通过调整每个参数的系数实现有效的模型融合。 \({\tt Pcb-Merging}\) 采用内部平衡来评估各个任务中参数的重要性,并采用外部平衡来评估不同任务间的参数相似性。重要性分数较低的参数被舍弃,其余参数被重新缩放,以形成最终的融合模型。
论文在多种融合场景中评估了该方法,包括跨任务、跨领域和跨训练配置,以及领域外泛化。实验结果表明,该方法在多个模态、领域、模型大小、任务数量、微调形式以及大型语言模型中实现了显著的性能提升,超越了现有的模型融合方法。
PCB-Merging
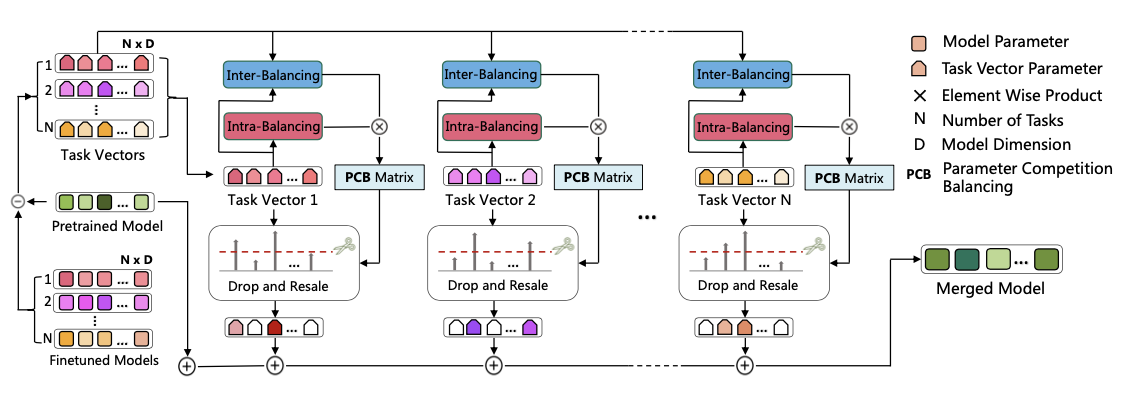
最近的模型合并研究基于任务向量完成各种任务算术操作和模型合并。对于任务 \(T_i\) ,任务向量 \(\tau_{i} \in \mathbb{R}^\textrm{d}\) 定义为通过从微调权重 \(\theta_\textrm{i}\) 中减去预训练权重 \(\theta_\textrm{pre}\) 所得到的向量,即 \(\tau_{i} = \theta_\textrm{i} - \theta_\textrm{pre}\) ,用于专注每个任务特定模型微调阶段发生的变化。基于任务向量的多任务模型合并方法可以表达为 \(\theta_m = \theta_\textrm{pre} + \lambda * \sum_{i=1}^{n}\tau_i\) ,其中系数 \(\lambda\) 表示合并任务向量 \(\tau_m\) 的重要性。这个概念简单而有效,显著优于简单的权重平均方案,即 \(\theta_m = (1/N)\sum_{i=1}^{n}\theta_i\) 。
平衡参数竞争
PCB-Merging旨在调节每个任务和参数的缩放因子,实现任务内部和平衡任务之间的相互平衡。具体而言,使用参数竞争平衡(PCB)矩阵 \(\beta_i \in \mathbb{R}^{d}\) 来调整每个任务模型 \(\theta_i \in \mathbb{R}^{d}\) 中参数的规模,从而得到最终的融合模型,具体如下:

Intra-Balancing
首先,通过对任务向量的幅度应用非线性激活函数(即softmax)来实现self-awareness,强调重要参数,同时在一定程度上抑制冗余参数。
随着融合任务数量的增加,参数之间的竞争加剧。因此,使用任务数量 \(N\) 来调节冗余参数的抑制程度。
\beta_{intra, i} = \text{Softmax}(N*\text{Norm}({\tau}_i \odot{\tau}_i))
\end{equation}
\]
Inter-Balancing
接下来,使用cross-awareness来使一组任务内的参数能够与其他参数互动,从而解决任务之间潜在的冲突和复杂的相关性。
为了实现这一目标,计算不同任务向量中相同位置参数之间的相似度,使得每个参数能够基于来自其他任务的信息更新其分数。计算过程如下:
\beta_{inter, i} = \sum\nolimits_{j=1}^{n} \text{Softmax}(\text{Norm}({\tau}_i \odot{\tau}_j))
\end{equation}
\]
Drop and Rescale
得到 \(\beta_{i} = \beta_{intra, i} \odot \beta_{inter, i}\) 后,基于 \(\beta_i\) 构建一个掩码 \(m_i \in \mathbb{R}^{d}\) 以关注更重要的参数。具体而言,这个掩码 \(m_i\) 用于从 \(\beta_i\) 的 \(D\) 个元素中选择高分数元素。
定义掩码比例为 \(r\) ,其中 \(0 < r \leq 1\) 。掩码 \(m_i\) 可以通过以下公式推导得出:
m_{i, d} = \begin{cases}
1,& \text{if } \beta_{i, d} \geq\text{sorted}(\beta_i)[(1-r) \times D] \\
0,& \text{otherwise}
\end{cases}
\end{equation}
\]
重要性分数定义为 \(\hat{\beta} = m_i \odot \beta_i\) ,使用掩码平衡矩阵的分数来加权每个任务向量中每个参数的重要性,得到最终合并的任务向量 \(\tau_m\) :
\tau_m = \sum\nolimits_{i=1}^{n}(\hat{\beta}_i \odot{\tau}_i) / \sum\nolimits_{i=1}^{n}\hat{\beta}_i
\end{equation}
\]
最终合并的任务向量 \(\tau_m\) 可以进一步按比例调整其幅度,并将其与初始参数值结合以生成融合后的模型参数 \(\theta_m\) ,表示为 \(\theta_m = \theta_\textrm{pre} + \lambda * \tau_m\) ,其中 \(\lambda\) 是一个缩放超参数。
系数搜索
先前的研究表明,基于任务向量的模型合并方法对合并系数 \(\lambda\) 非常敏感。即便选取了合适的统一 \(\lambda\) ,要进一步提高融合性能仍然需要对每个任务向量进行合并系数的网格搜索。这个过程复杂且繁琐,特别是在处理大量任务时。
论文采用智能优化算法来搜索混合系数,旨在比使用统一系数获得更大的改进。这一优化过程旨在寻找最佳的集合 \(\{\lambda_1, \cdots, \lambda_n\}\) ,以增强验证准确性,最终目标是最大化合并模型的验证准确性。
\theta_m = \theta_\textrm{pre} + \sum\nolimits_{i=1}^{n}(\hat{\beta}_i \odot \lambda_i {\tau}_i) / \sum\nolimits_{i=1}^{n}\hat{\beta}_i
\end{equation}
\]
在大多数实验设置中,主要使用协方差矩阵自适应进化策略(CMA-ES)。作为一种基于概率的种群优化算法,CMA-ES动态调整由协方差矩阵定义的搜索分布。它在每次迭代中系统地更新该分布的均值和协方差,以学习并利用搜索空间的潜在结构,从而提高优化效率。
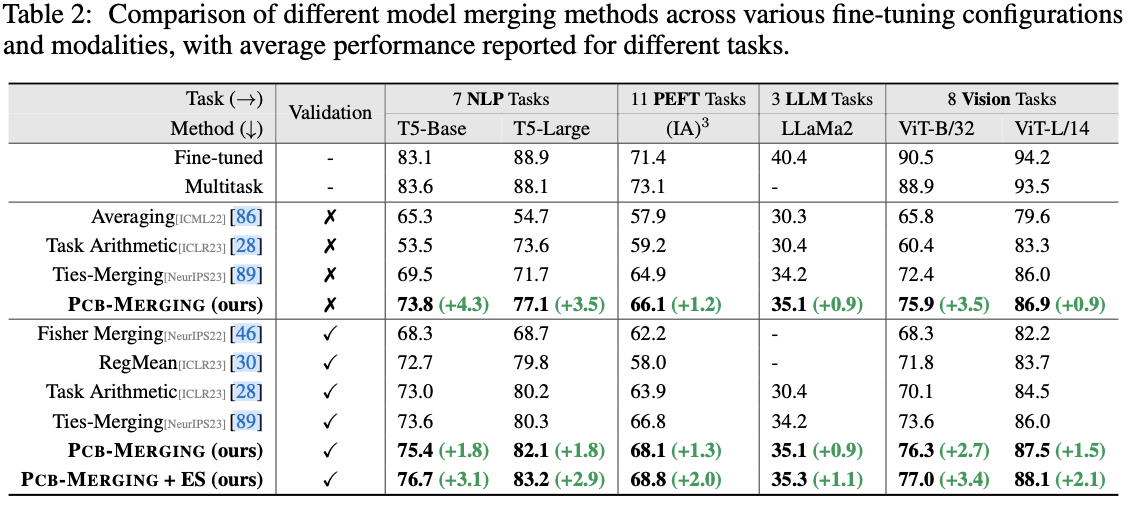
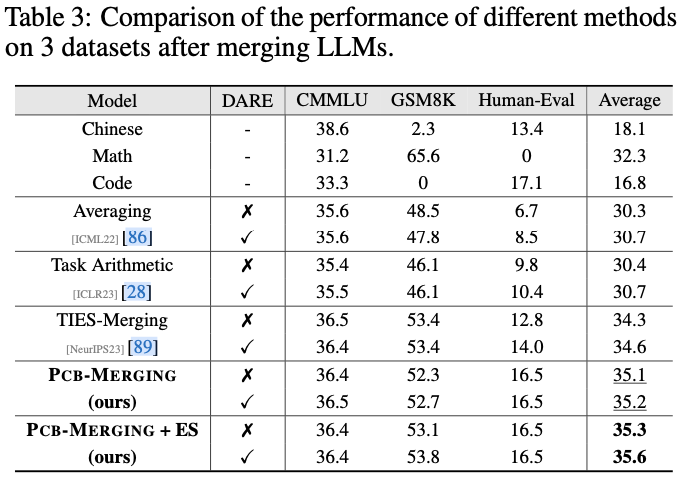
主要结果
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

Pcb-Merging:无需训练的多任务模型合并方案 | NeurIPS'24的更多相关文章
- 人脸检测及识别python实现系列(5)——利用keras库训练人脸识别模型
人脸检测及识别python实现系列(5)——利用keras库训练人脸识别模型 经过前面稍显罗嗦的准备工作,现在,我们终于可以尝试训练我们自己的卷积神经网络模型了.CNN擅长图像处理,keras库的te ...
- [源码解析] 模型并行分布式训练 Megatron (3) ---模型并行实现
[源码解析] 模型并行分布式训练 Megatron (3) ---模型并行实现 目录 [源码解析] 模型并行分布式训练 Megatron (3) ---模型并行实现 0x00 摘要 0x01 并行Tr ...
- (原)ubuntu16在torch中使用caffe训练好的模型
转载请注明出处: http://www.cnblogs.com/darkknightzh/p/5783006.html 之前使用的是torch,由于其他人在caffe上面预训练了inception模型 ...
- 训练 smallcorgi/Faster-RCNN_TF 模型(附ImageNet model百度云下载地址)
1. 下载训练.验证.测试数据和 VOCdevkit,下载地址: http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2 ...
- 第三十二节,使用谷歌Object Detection API进行目标检测、训练新的模型(使用VOC 2012数据集)
前面已经介绍了几种经典的目标检测算法,光学习理论不实践的效果并不大,这里我们使用谷歌的开源框架来实现目标检测.至于为什么不去自己实现呢?主要是因为自己实现比较麻烦,而且调参比较麻烦,我们直接利用别人的 ...
- 如何用Tensorflow训练模型成pb文件和和如何加载已经训练好的模型文件
这篇薄荷主要是讲了如何用tensorflow去训练好一个模型,然后生成相应的pb文件.最后会将如何重新加载这个pb文件. 首先先放出PO主的github: https://github.com/ppp ...
- 用C++调用tensorflow在python下训练好的模型(centos7)
本文主要参考博客https://blog.csdn.net/luoyexuge/article/details/80399265 [1] bazel安装参考:https://blog.csdn.net ...
- Caffe使用step by step:使用自己数据对已经训练好的模型进行finetuning
在经过前面Caffe框架的搭建以及caffe基本框架的了解之后,接下来就要回到正题:使用caffe来进行模型的训练. 但如果对caffe并不是特别熟悉的话,从头开始训练一个模型会花费很多时间和精力,需 ...
- 在 C/C++ 中使用 TensorFlow 预训练好的模型—— 直接调用 C++ 接口实现
现在的深度学习框架一般都是基于 Python 来实现,构建.训练.保存和调用模型都可以很容易地在 Python 下完成.但有时候,我们在实际应用这些模型的时候可能需要在其他编程语言下进行,本文将通过直 ...
- TensorFlow 同时调用多个预训练好的模型
在某些任务中,我们需要针对不同的情况训练多个不同的神经网络模型,这时候,在测试阶段,我们就需要调用多个预训练好的模型分别来进行预测. 调用单个预训练好的模型请点击此处 弄明白了如何调用单个模型,其实调 ...
随机推荐
- c# 复制文件夹内所有文件到另外一个文件夹
/// <summary> /// 开始转移 /// </summary> /// <param name="sender"></para ...
- git重命名文件夹
在源代码文件夹中打开git bash, 不同名称的文件夹命令: 1. git mv A An 3. git add -u An 4. git commit -m "重命名A为An&quo ...
- java-GUI编程之布局类型介绍
java使用AWT和Swing相关的类可以完成图形化界面编程,其中AWT的全称是抽象窗口工具集(Abstract Window Toolkit),它是sun公司最早提供的GUI库,这个GUI库提供了一 ...
- 2023/11/15 NOIP 模拟赛
T1 游戏 标签 尺取 线段树 单调队列 线段树进阶 思路 抽象题意,相当于有 \(t\) 个点,有 \(n\) 个下接 \(x\) 轴的矩形. 首先明显可以按照 \(c\) 排序,然后尺取. 写法 ...
- DVI与VGA有什么区别?
DVI接口:DVI(Digital Visual Interface),即数字视频接口.DVI接口速度快.画面清晰.支持HDCP协议. VGA接口:VGA(Video Graphics Array)即 ...
- 合合信息扫描全能王亮相静安区3·15活动,AI扫描带来绿色消费新体验
保护消费者的合法权益,是全社会的共同责任.为优化消费环境.促进品质消费高地建设,打造安全优质和谐的消费环境,上海静安区消保委于3月15日举办静安区2024年"3·15"国际消费者权 ...
- BOOST 定时器 stop探究
Asio是一个建立在Boost所提供的相关组件之上的异步的网络库,可以运行在Win/Linux/Unix等各种平台之上. 不过随着C++11的发布,其对Boost的依赖也越来越少,作者又做了一个不依赖 ...
- OxyPlot公共属性一览
一.PlotModel 1.构造函数中设置的属性 public PlotModel() { this.Axes = new ElementCollection(this); //坐标轴集合; this ...
- 九问 GBase | 如何看待“科技制裁”?如何助力中国数据库国产化落地?
导读: Oracle.SAP.Apple.Google.Github等国际科技巨头纷纷宣布停止在俄罗斯业务,英特尔.AMD.戴尔等科技企业也被曝已中断向俄供货.当全面科技制裁来临,俄罗斯将如何应对此次 ...
- 怎么理解vue的单向数据流
单向数据流是父组件传给子组件的数据,子组件没有权利修改,只能委托父组件修改,然后子组件更新