Python图表数据可视化Seaborn:3. 线性关系数据| 时间线图表| 热图
1. 线性关系数据可视化
lmplot( )
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
% matplotlib inline sns.set_style("darkgrid")
sns.set_context("paper")
# 设置风格、尺度 import warnings
warnings.filterwarnings('ignore')
# 不发出警告
# 基本用法
tips = sns.load_dataset("tips")
print(tips.head())
# 加载数据
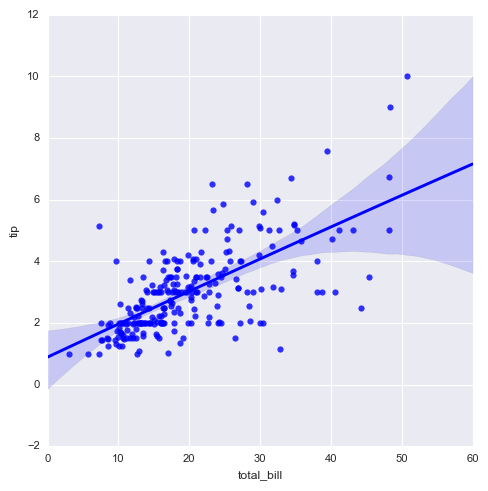
sns.lmplot(x="total_bill", y="tip", hue = 'smoker',data=tips,palette="Set1",
ci = 70, # 误差值
size = 5, # 图表大小
markers = ['+','o'], # 点样式
)

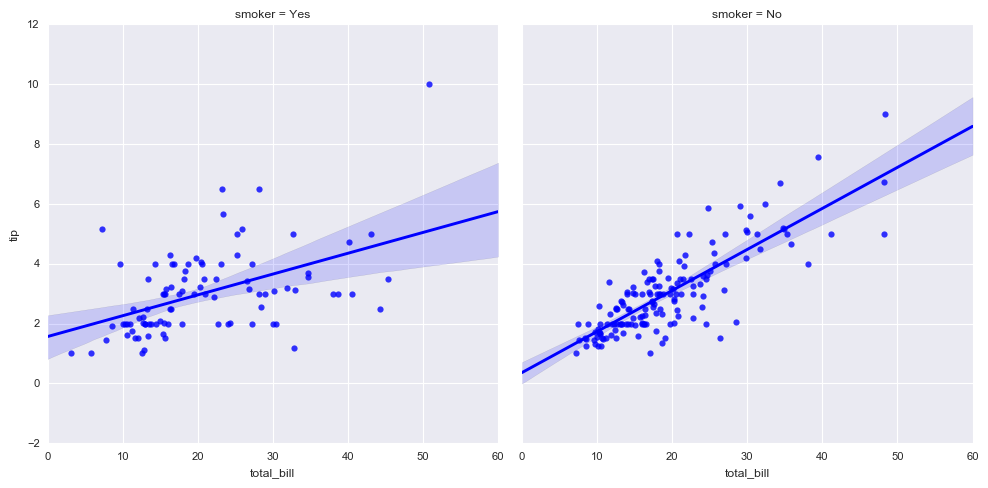
# 拆分多个表格 sns.lmplot(x="total_bill", y="tip", col="smoker", data=tips)
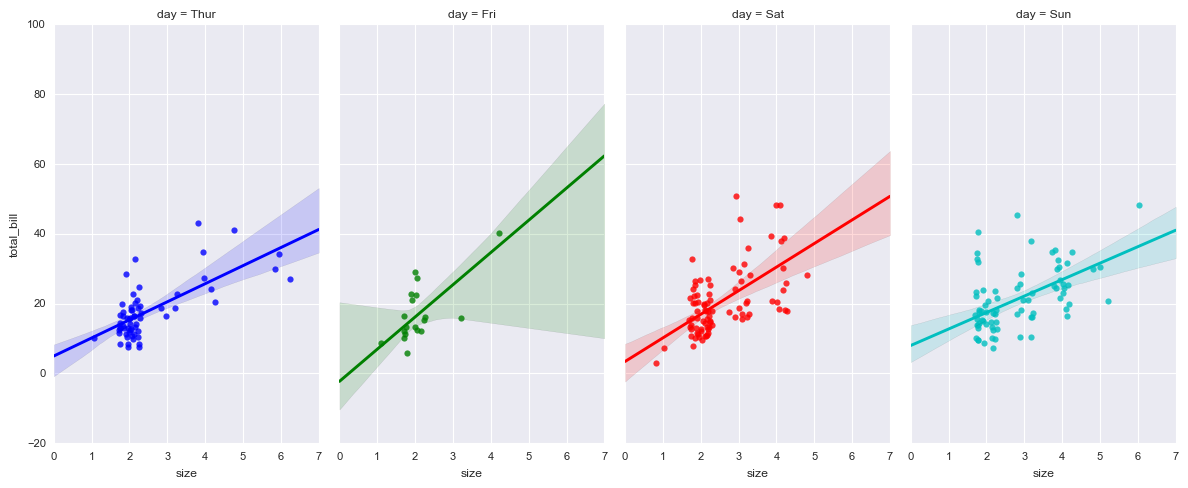
# 多图表1 sns.lmplot(x="size", y="total_bill", hue="day", col="day",data=tips,
aspect=0.6, # 长宽比
x_jitter=.30, # 给x或者y轴随机增加噪音点
col_wrap=4, # 每行的列数
)
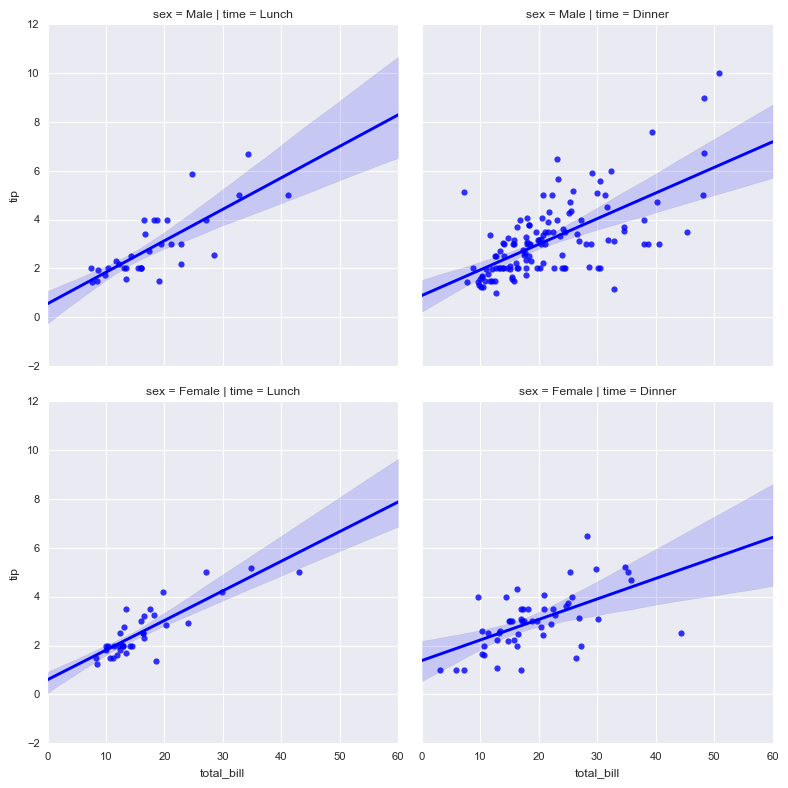
# 多图表2 sns.lmplot(x="total_bill", y="tip", row="sex", col="time",data=tips, size=4)
# 行为sex字段,列为time字段
# x轴total_bill, y轴tip
# 非线性回归 sns.lmplot(x="total_bill", y="tip",data=tips,
order = 2) #可以做更高阶的回归;2就是按照2次方做回归;
2. 时间线图表
sns. tsplot( )
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
% matplotlib inline sns.set_style("darkgrid")
sns.set_context("paper")
# 设置风格、尺度 import warnings
warnings.filterwarnings('ignore')
# 不发出警告
# 1、时间线图表 - tsplot()
# 简单示例 x = np.linspace(0, 15, 31)
data = np.sin(x) + np.random.rand(10, 31) + np.random.randn(10, 1)
print(data.shape)
print(pd.DataFrame(data).head()) #每一行数据是一个变量,31列是代表有31天或31种情况下的观测值。
# 创建数 sns.tsplot(data=data,
err_style="ci_band", # 误差数据风格,可选:ci_band, ci_bars, boot_traces, boot_kde, unit_traces, unit_points
interpolate=True, # 是否连线
ci = [40,70,90], # 设置误差 置信区间
color = 'g' # 设置颜色
)
一个变量里边有10个变量,每个变量里边有31个观测值

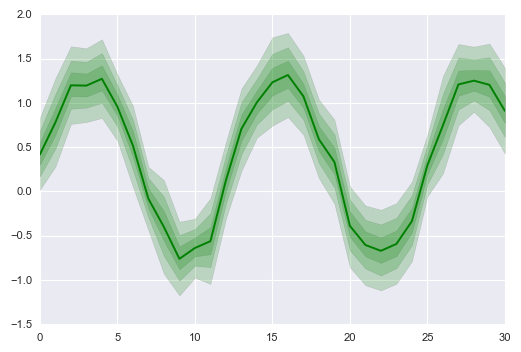 10个变量,做了一个均值的估计,其他31个维度代表它的变化程度。
10个变量,做了一个均值的估计,其他31个维度代表它的变化程度。
# 1、时间线图表 - tsplot()
# 简单示例 sns.tsplot(data=data, err_style="boot_traces",
n_boot=300 # 迭代次数,就是有多少个线;
)

# 1、时间线图表 - tsplot()
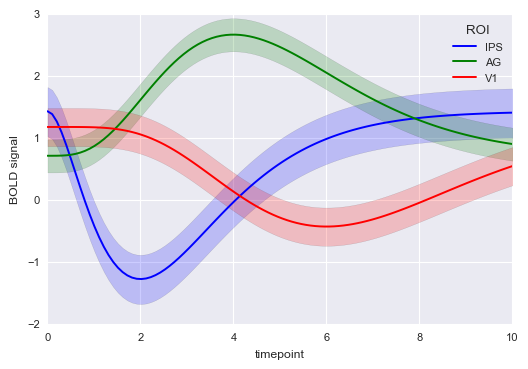
# 参数设置 gammas = sns.load_dataset("gammas")
print(gammas.head())
print('数据量为:%i条' % len(gammas))
print('timepoint为0.0时的数据量为:%i条' % len(gammas[gammas['timepoint'] == 0]))
print('timepoint共有%i个唯一值' % len(gammas['timepoint'].value_counts()))
# print(gammas['timepoint'].value_counts()) # 查看唯一值具体信息
# 导入数据 sns.tsplot(time="timepoint", # 时间数据,x轴
value="BOLD signal", # y轴value
unit="subject", #
condition="ROI", # 分类
data=gammas)
# gammas[['ROI', 'subject']]

3.热图
sns.heatmap()
# 2、热图 - heatmap()
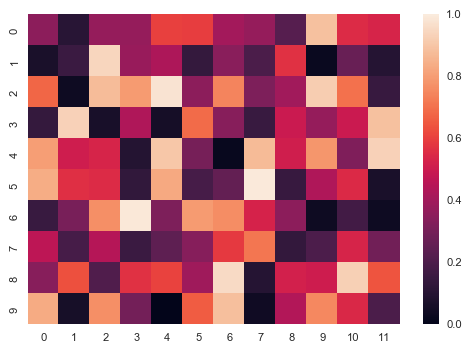
# 简单示例
df = pd.DataFrame(np.random.rand(10,12))
# 创建数据 - 10*12图表 sns.heatmap(df, # 加载数据
vmin=0, vmax=1 # 设置图例最大最小值
)
# 2、热图 - heatmap()
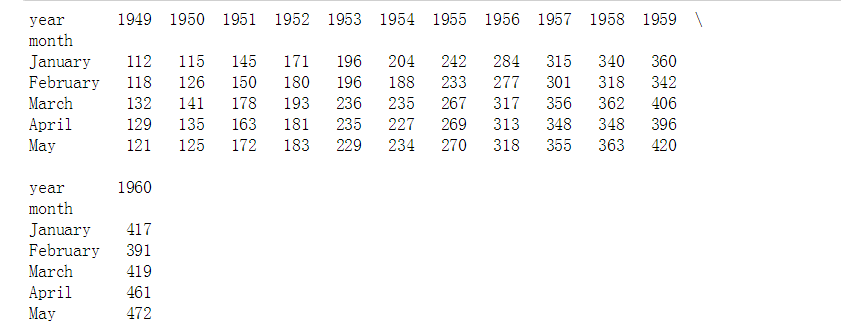
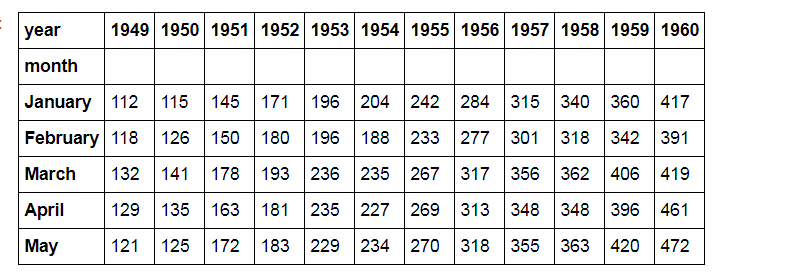
# 参数设置 flights = sns.load_dataset("flights")
flights = flights.pivot("month", "year", "passengers")
print(flights.head())
# 加载数据
sns.heatmap(flights,
annot = True, # 是否显示数值
fmt = 'd', # 格式化字符串
linewidths = 0.2, # 格子边线宽度
#center = 100, # 调色盘的色彩中心值,若没有指定,则以cmap为主
#cmap = 'Reds', # 设置调色盘
cbar = True, # 是否显示图例色带
#cbar_kws={"orientation": "horizontal"}, # 是否横向显示图例色带
#square = True, # 是否正方形显示图表
)
flights.head()

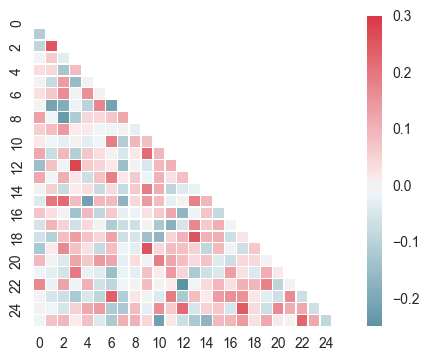
# 2、热图 - heatmap() 绘制半边热图 sns.set(style="white")
# 设置风格 rs = np.random.RandomState(33)
d = pd.DataFrame(rs.normal(size=(100, 26)))
corr = d.corr() #26*26的一个正方数据; # 求解相关性矩阵表格
# 创建数据
mask = np.zeros_like(corr, dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
# 设置一个“上三角形”蒙版 cmap = sns.diverging_palette(220, 10, as_cmap=True)
# 设置调色盘 sns.heatmap(corr, mask=mask, cmap=cmap, vmax=.3, center=0,
square=True, linewidths=0.2)
# 生成半边热图
Python图表数据可视化Seaborn:3. 线性关系数据| 时间线图表| 热图的更多相关文章
- 基于echarts 24种数据可视化展示,填充数据就可用,动手能力强的还可以DIY(演示地址+下载地址)
前言 我们先跟随百度百科了解一下什么是"数据可视化 [1]". 数据可视化,是关于数据视觉表现形式的科学技术研究. 其中,这种数据的视觉表现形式被定义为,一种以某种概要形式抽提出来 ...
- Python图表数据可视化Seaborn:2. 分类数据可视化-分类散点图|分布图(箱型图|小提琴图|LV图表)|统计图(柱状图|折线图)
1. 分类数据可视化 - 分类散点图 stripplot( ) / swarmplot( ) sns.stripplot(x="day",y="total_bill&qu ...
- Python图表数据可视化Seaborn:1. 风格| 分布数据可视化-直方图| 密度图| 散点图
conda install seaborn 是安装到jupyter那个环境的 1. 整体风格设置 对图表整体颜色.比例等进行风格设置,包括颜色色板等调用系统风格进行数据可视化 set() / se ...
- Python数据可视化-seaborn库之countplot
在Python数据可视化中,seaborn较好的提供了图形的一些可视化功效. seaborn官方文档见链接:http://seaborn.pydata.org/api.html countplot是s ...
- Python数据可视化编程实战——导入数据
1.从csv文件导入数据 原理:with语句打开文件并绑定到对象f.不必担心在操作完资源后去关闭数据文件,with的上下文管理器会帮助处理.然后,csv.reader()方法返回reader对象,通过 ...
- 数据可视化 seaborn绘图(1)
seaborn是基于matplotlib的数据可视化库.提供更高层的抽象接口.绘图效果也更好. 用seaborn探索数据分布 绘制单变量分布 绘制二变量分布 成对的数据关系可视化 绘制单变量分布 se ...
- Python 绘图与可视化 seaborn
Seaborn是一个基于matplotlib的Python数据可视化库.它提供了一个高级界面,用于绘制有吸引力且信息丰富的统计图形. 主页:http://seaborn.pydata.org/ 官方教 ...
- 第二篇:Power BI数据可视化之基于Web数据的报表制作(经典级示例)
前言 报表制作流程的第一步显然是从各个数据源导入数据,Power BI能从很多种数据源导入数据:如Excel,CSV,XML,以及各类数据库(SQL Server,Oracle,My SQL等),两大 ...
- JavaScript数据可视化编程学习(二)Flotr2,雷达图
一.雷达图 使用雷达图显示多维数据. 如果你有多维的数据要展示,那么雷达图就是一种非常有效的可视化方法. 由于雷达图不常用,比较陌生,所以向用户解释的时候有一些难度.注意使用雷达图会增加用户认知负担. ...
随机推荐
- linux云主机cpu一直很高降不下来,系统日志报nf_conntrack: table full, dropping packet.
在启用了iptables web服务器上,流量高的时候经常会出现下面的错误: ip_conntrack: table full, dropping packet 这个问题的原因是由于web服务器收到了 ...
- 如何去掉li标签的重叠边框
当我们的li标签设置了border的时候就会出现重叠边框,如何去掉呢,见代码 html代码 <ul class="friendLink_list"> <li> ...
- Vue-tab选项卡
<div id='test'> <ul class="nav" > <li v-for='(item,index) in dataNav' @clic ...
- iOS -- Effective Objective-C 阅读笔记 (1)
1: 在类的头文件中尽量 少 的引用其他头文件,尽量用 @class xxxxxx; 理解: 当你创建了一个 A 类,这个类又 需要具有 B 类的实例, 你可以直接为 A 类添加 B 类类型的 属性, ...
- ios 调整 label 的字体行间距
UILabel *label = [[UILabel alloc] initWithFrame:CGRectMake(0, 100, self.view.frame.size.width, 200) ...
- json字符串和字典的区别补充
json字符串和字典的区别:json:(JavaScript Object Notation)的首字母缩写,字面的意思是(javascript对象表示法),这里说的json指的是类似于javascri ...
- day12 函数的嵌套调用 闭包函数,函数对象
函数嵌套: 函数嵌套: 嵌套指的是,一个物体包含另一个物体,函数嵌套就是一个函数包含另一个函数 按照函数的两个阶段 嵌套调用 指的是在函数的执行过程中调用了另一个函数,其好处可以简化外层大函数的代码, ...
- Matplotlib模块:绘图和可视化
一.简单介绍Matplotlib 1.Matplotlib是一个强大的Python绘图和数据可视化的工具包 2.安装方法:pip install matplotlib 3.引用方法:import ma ...
- <a>之间怎么放值</a> 挺简单的,第一次遇到···
需求描述:对列表中的某一列内容添加a标签(其实就是对td标签下添加a标签了). 思路简介:拿到这个我首先的反应就是在td标签对text获取内容的代码中动态拼接<a></a>字符 ...
- 【深度学习】吴恩达网易公开课练习(class1 week3)
知识点梳理 python工具使用: sklearn: 数据挖掘,数据分析工具,内置logistic回归 matplotlib: 做图工具,可绘制等高线等 绘制散点图: plt.scatter(X[0, ...