【Python3爬虫】网络小说更好看?十四万条书籍信息告诉你
一、前言简述
因为最近微信读书出了网页版,加上自己也在闲暇的时候看了两本书,不禁好奇什么样的书更受欢迎,哪位作者又更受读者喜欢呢?话不多说,爬一下就能有个了解了。
二、页面分析
首先打开微信读书:https://weread.qq.com/,往下拉之后可以看到有榜单推荐,而且显示总共有25个榜单,有的榜单只有几百本,有的榜单却有几万本书。
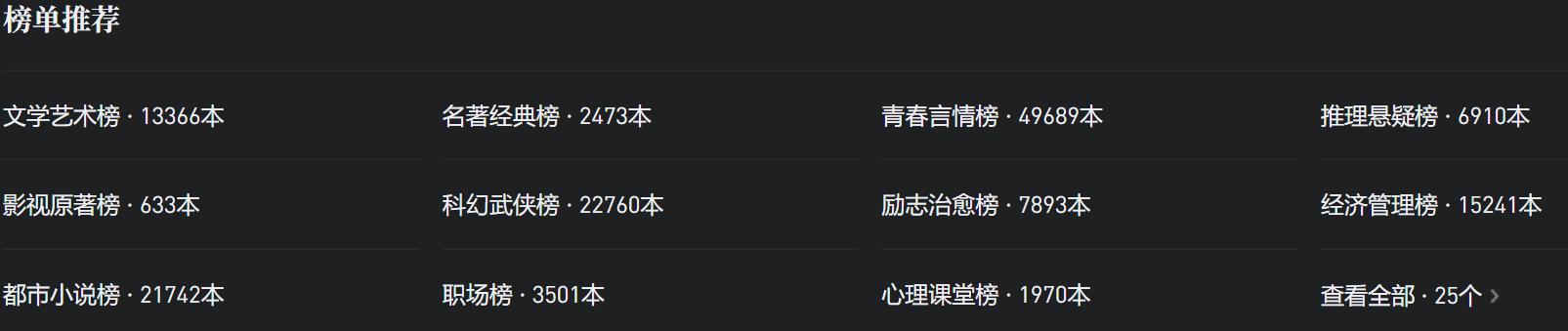
打开“文学艺术榜”,可以看到一页显示了20条书本信息,下拉之后很容易就能发现这些书本信息是通过 AJAX 来加载的。

更关键的是,要获取这些书籍信息,只需要得到分类 ID 和参数 maxIndex。不过测试发现,每个分类只会返回50个页面的内容,也就是最多一千条书本信息。那么,如果只有这25个类别的榜单,能得到的数据还是有点少的,所以要怎么得到更多的数据呢?
细心的人可以发现右侧还能选择类别!如下图:
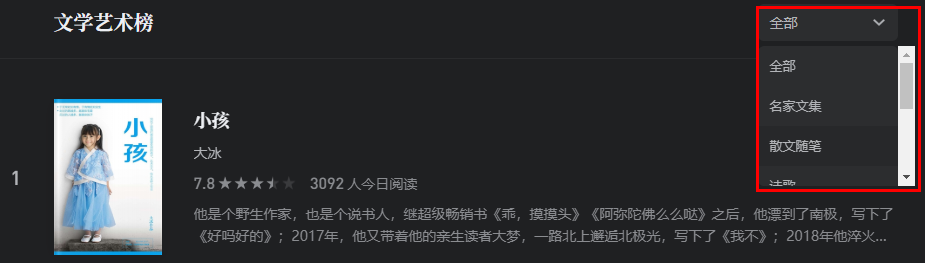
不过,查看这些元素发现里面是没有显示 URL 的,如下图:
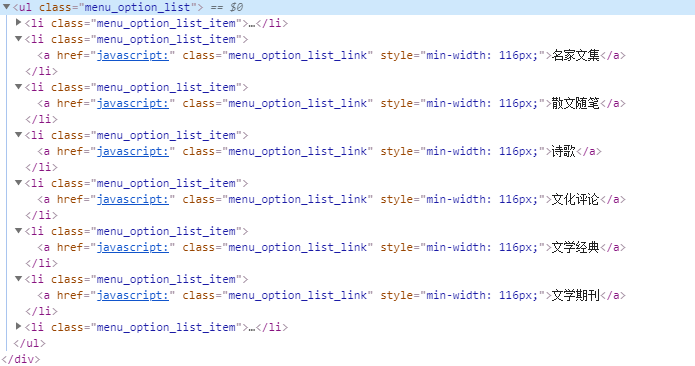
但是这也不表示没有办法了,全局搜索一下就能找到了,如下图:

CategoryId 就是这个分类的 ID,也就是 URL 中“bookListInCategory/”后面的内容。至于 maxIndex,可以先设为0,然后发送请求得到这一分类的书本总数“totalCount”,然后根据这个书本总数是否超过一千来设置页数,就能得到这一分类下能够爬取到的所有 URL 了。
三、爬取步骤
前面经过分析已经知道只要拿到书本分类 ID,就能发送请求得到书本总数,也就能构造该分类下的所有页面的 URL 了。那要怎么得到所有分类呢?前面全局搜索的时候已经搜到了书本分类的 CategoryId 等信息,如下图:
所以只需先请求页面然后用正则匹配 CategoryId 就行了!然后对每个分类发送一次请求,用于获取书本总数,并构造这一分类下的所有 URL。这一部分代码如下:
def prepare(base_url="https://weread.qq.com/web/category/1700000") -> list:
"""
prepare for crawler
:param base_url: weread base url
:return: page url list
"""
def request(url) -> list:
"""
request function
:param url: url
:return: page url list
"""
page_urls = []
try:
res = requests.get(url=url, headers=headers)
if res.status_code == 200:
count = res.json()["totalCount"]
cnt = 50 if count >= 1000 else count // 20
page_urls = [url + "?maxIndex={}".format(i * 20) for i in range(cnt)]
else:
logging.error("Error request!")
except Exception as e:
logging.error(e)
finally:
return page_urls resp = requests.get(url=base_url, headers=headers)
# check status code
if resp.status_code == 200:
id_list = re.findall('"CategoryId":"(.+?)"', resp.text)
id_list = list(set([i for i in id_list if i[0].isdigit()]))
href_list = ["https://weread.qq.com/web/bookListInCategory/{}".format(i) for i in id_list]
result = []
for href in href_list:
result += request(href)
logging.info("Url count: {}".format(len(result)))
return result
else:
logging.error("Prepare error!")
exit()
进行到这一步,后面就很简单了,就是获取请求结果并解析即可。程序运行时打印输出如下:
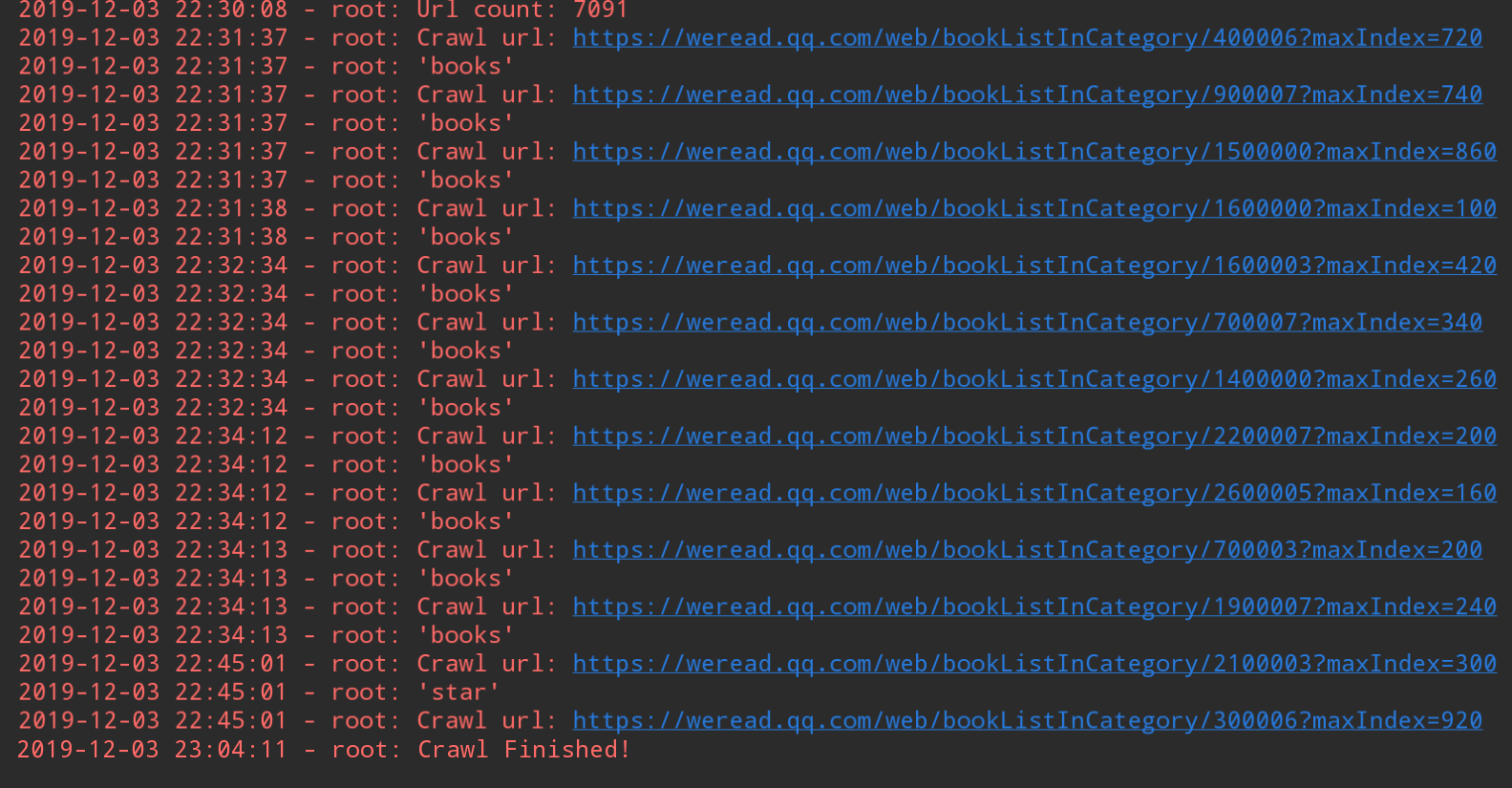
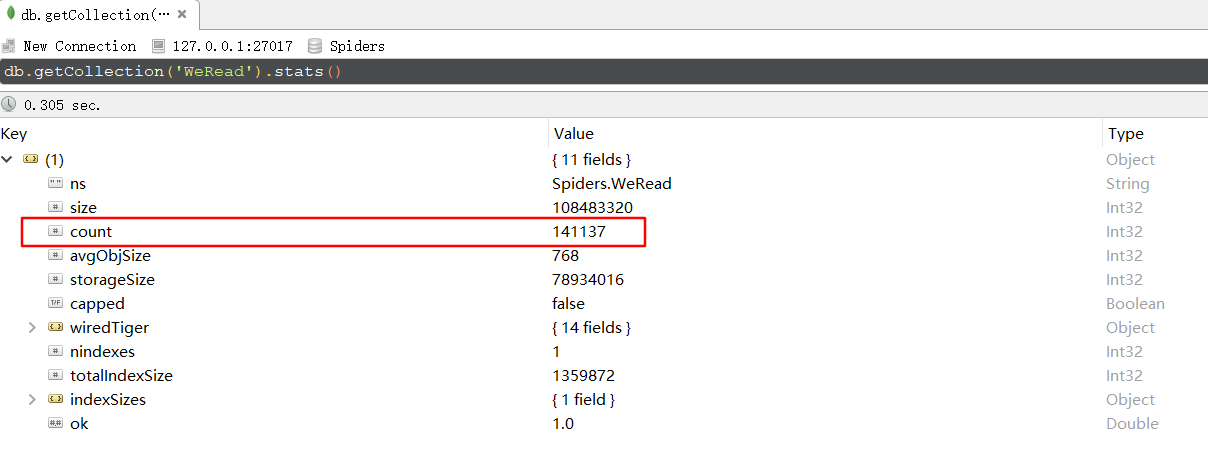
可以看到总链接数有7091条,那么爬到的书本信息有多少条呢?因为我用的是 MongoDB 保存的,所以打开 Robot3T 查看,总共有141137条,结果如下图:
四、绘图分析
熟悉 Python 的都知道,matplotlib 是 Python 中用的最多的 2D 图形绘图库。不过我在这推荐一个好用的第三方库:pyecharts,这是一个用于生成 Echarts 图表的类库,生成的图表更加精巧,可视化效果更好,不过需要注意的是 pyecharts 的0.5版本和1.0版本使用方法是不同的。下面就是使用这个库生成的横向柱状图了,分别表示评分前十的书籍、阅读量前十的书籍和总阅读量前十的作者:
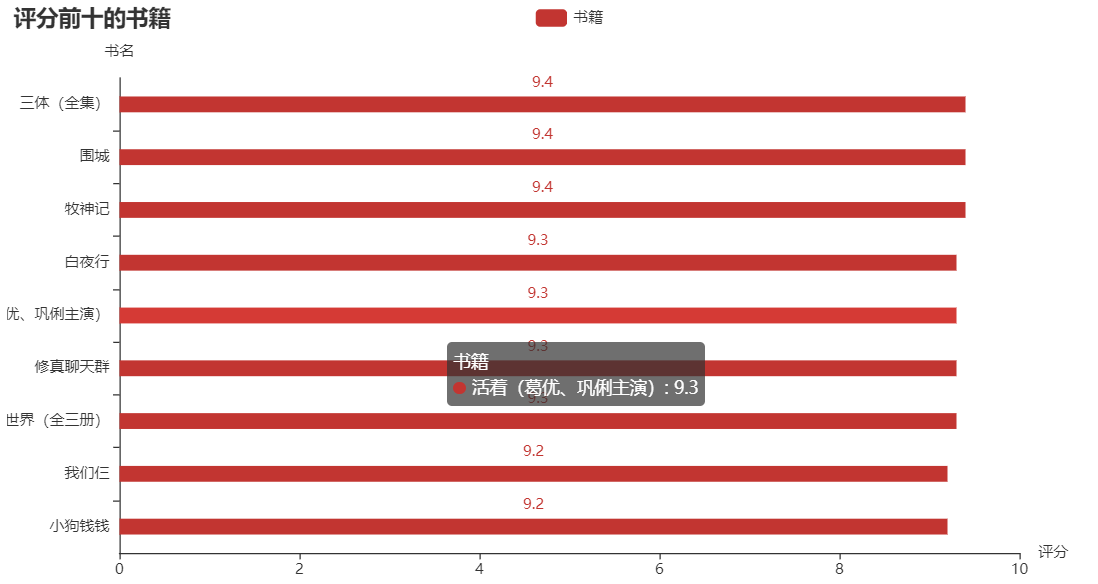
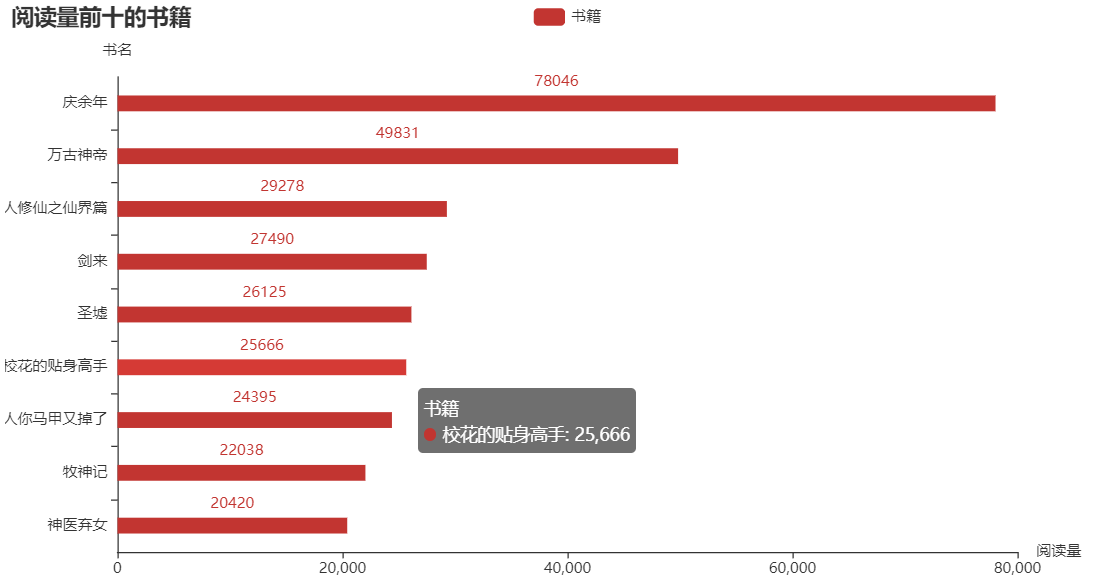
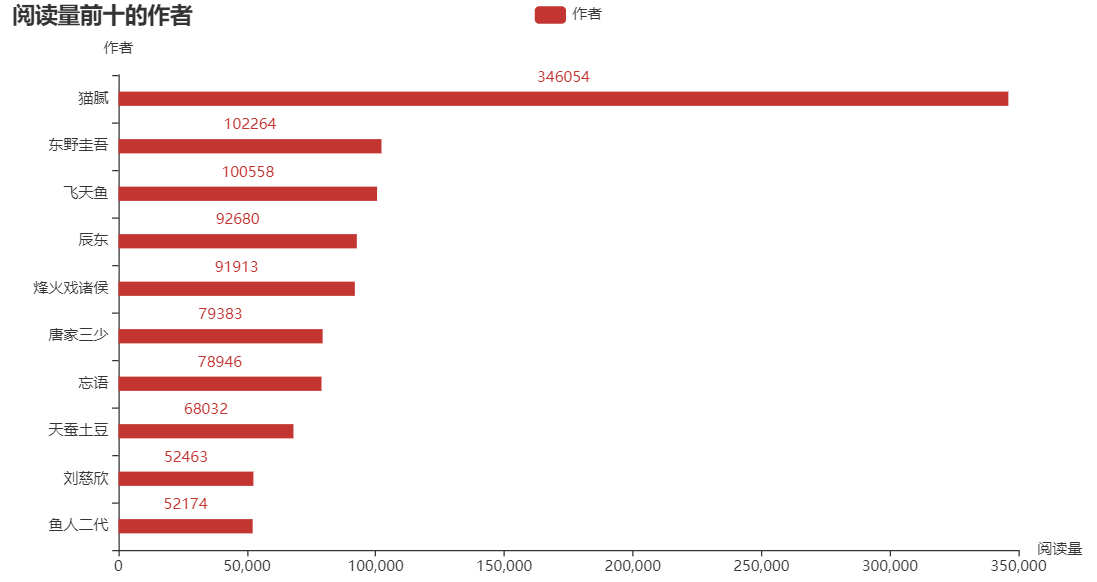
可以发现评分高的书籍阅读量却不一定高,阅读量更多的往往是一些网络小说。为什么好像现在名著都不怎么讨喜,而网络小说却能让更多人着迷呢?个人猜想是小说里的世界可能更加能够满足现在年轻人的幻想吧,现实生活疲惫不堪,就会更加迷恋小说中的“世外桃源”吧。
完整代码已上传到 GitHub!
【Python3爬虫】网络小说更好看?十四万条书籍信息告诉你的更多相关文章
- Python爬取十四万条书籍信息告诉你哪本网络小说更好看
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: TM0831 PS:如有需要Python学习资料的小伙伴可以加点击 ...
- Linux学习总结(十四)—— 查看CPU信息
文章首发于[博客园-陈树义],点击跳转到原文Linux学习总结(十四)-- 查看CPU信息. Linux学习总结(十四)-- 查看CPU信息 商用服务器CPU最常用的是 Intel Xeon 系列,该 ...
- 十几万条数据的表中,基于帝国cms 。自己亲身体验三种批量更新数据的方法,每一种的速度是什么样的
需求是 上传Excel 读取里面的数据.根据Excel中某一个字段,与数据表中的一个字段的唯一性.然后把 Excel表中数据和数据库表中数据一次更改.本次测试一次更新31条数据. 本次测试基于帝国cm ...
- Kubernetes & Docker 容器网络终极之战(十四)
目录 一.单主机 Docker 网络通信 1.1.host 模式 1.2 Bridge 模式 1.3 Container 模式 1.4.None 模式 二.跨主机 Docker 网络通信分类 2.1 ...
- 《UNIX环境网络编程》第十四章第14.9小结(bug)
1.源代码中的<sys/devpoll.h>头文件在我的CentOS7系统下的urs/include/sys/目录下没有找到. 而且我的CentOS7也不存在这个/dev/poll文件. ...
- python3 练习题100例 (二十四)打印完数
完数:一个数如果恰好等于它的因子之和,这个数就称为"完数".例如 6 = 1+2+3. 题目内容: 输入一个正整数n(n<1000),输出1到n之间的所有完数(包括n). 输 ...
- 网络爬虫:使用Scrapy框架编写一个抓取书籍信息的爬虫服务
上周学习了BeautifulSoup的基础知识并用它完成了一个网络爬虫( 使用Beautiful Soup编写一个爬虫 系列随笔汇总 ), BeautifulSoup是一个非常流行的Python网 ...
- 爬虫技术 -- 进阶学习(十)网易新闻页面信息抓取(htmlagilitypack搭配scrapysharp)
最近在弄网页爬虫这方面的,上网看到关于htmlagilitypack搭配scrapysharp的文章,于是决定试一试~ 于是到https://www.nuget.org/packages/Scrapy ...
- python3爬虫-爬取58同城上所有城市的租房信息
from fake_useragent import UserAgent from lxml import etree import requests, os import time, re, dat ...
随机推荐
- 【原创】从零开始搭建Electron+Vue+Webpack项目框架,一套代码,同时构建客户端、web端(二)
摘要:上篇文章说到了如何新建工程,并启动一个最简单的Electron应用.“跑起来”了Electron,那就接着把Vue“跑起来”吧.有一点需要说明的是,webpack是贯穿这个系列始终的,我也是本着 ...
- C语言知识体系
吾尝终日而思矣,不如须臾之所学也: 吾尝跂而望矣,不如登高之博见也. 登高而招,臂非加长也,而见者远: 顺风而呼,声非加疾也,而闻者彰. 假舆马者,非利足也,而致千里: 假舟楫者,非能水也,而绝江河. ...
- 《JavaScript设计模式与开发实践》-- 策略模式
详情个人博客:https://shengchangwei.github.io/js-shejimoshi-celue/ 策略模式 1.定义 策略模式:定义一系列的算法,把它们一个个封装起来,并且使它们 ...
- 27 个问题突破所有重难点,BroadcastReceiver 、ContentProvider 知多少?「建议收藏」
前言 距离上次更新过去一周多了,打破了之前两到三天一更的惯例,主要还是这部分内容太多了. 原先想把 BroadcastReceiver .ContentProvider 分两篇来总结,但的确,这两大组 ...
- Windows下内网渗透常用命令总结
域内信息收集常用命令 net group /domain //获得所有域用户组列表 net group zzh /domain //显示域中zzh组的成员 net group zzh /del /do ...
- pymssql连接Azure SQL Database
使用pymssql访问Azure SQL Database时遇到"DB-Lib error message 20002, severity 9:\nAdaptive Server conne ...
- [考试反思]0725NOIP模拟测试8
看清你是个什么东西了么? 现在看清了么?rank#15?垃圾玩意? 你什么也不是.你没有骄傲,偷懒的资格! 节节败退,永无止境,你想掉到什么样子? 你还在为了成功拿到送分的T1而沾沾自喜?只不过是勉强 ...
- NOIP模拟 39
考的嘛也不是. 伤心(怎么可能) T1稍想想组合数,然后牢记: 取模题随时取模,包括刚刚读入的数据 T2想到了基环树,然而不会打QAQ.. 非常简洁但非常大神的做法:随便断掉环上的一条边 利用“这条 ...
- ASP.NET Core 3.0 gRPC 拦截器
目录 ASP.NET Core 3.0 使用gRPC ASP.NET Core 3.0 gRPC 双向流 ASP.NET Core 3.0 gRPC 拦截器 一. 前言 前面两篇文章给大家介绍了使用g ...
- python经典面试算法题1.1:如何实现链表的逆序
本题目摘自<Python程序员面试算法宝典>,我会每天做一道这本书上的题目,并分享出来,统一放在我博客内,收集在一个分类中. 1.1 如何实现链表的逆序 [腾讯笔试题] 难度系数:⭐⭐⭐ ...