hadoop单机配置
条件:
先下载VMware1.2,然后安装。
下载ubuntu-1.4.05-desktop-amd64.iso。下载地址:http://mirrors.aliyun.com/ubuntu-releases/14.04.5/
下载hadoop2.7。下载地址:http://archive.apache.org/dist/hadoop/core/hadoop-2.7.1/
下载jdk-8u171-linux-x64.tar.gz。到官网下载。参考教程:https://blog.csdn.net/zl007700/article/details/50533675
将ubuntu安装在VMware上。
1.创建hadoop用户
sudo useradd -m hadoop -s /bin/bash
设置密码
sudo passwd hadoop
增加管理员权限
sudo adduser hadoop sudo

最后退出当前用户,然后重新登陆hadoop用户。
2.更新apt
sudo apt-get update

3.安装SSH,配置SSH无密码登录
安装SSH server:
sudo apt-get install openssh-server
安装后,用命令登录:
ssh localhost
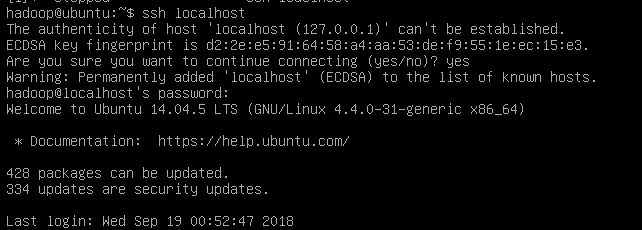
但是这样登陆需要密码。所以首先退出刚才的 ssh,利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
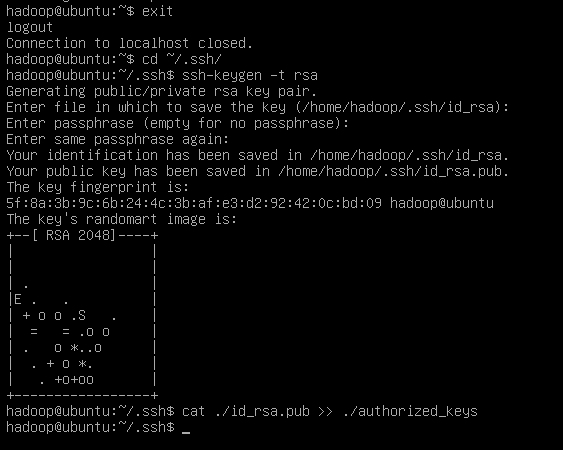
然后就可以无密码登录了

3.免配置环境安装jdk
sudo apt-get install default-jre default-jdk
上述安装过程需要访问网络下载相关文件,请保持联网状态。安装结束以后,需要配置JAVA_HOME环境变量,请在Linux终端中输入下面命令打开当前登录用户的环境变量配置文件.bashrc:
vim ~/.bashrc
在文件最前面添加如下单独一行(注意,等号“=”前后不能有空格),然后保存退出:
export JAVA_HOME=/usr/lib/jvm/default-java
接下来,要让环境变量立即生效,请执行如下代码:
source ~/.bashrc
执行上述命令后,可以检验一下是否设置正确:

4.安装hadoop
将下载好的hapoop解压到/usr/local/
sudo tar -zxf ~/Downloads/hadoop-2.7.6.tar.gz -C /usr/local # 解压到/usr/local中
cd /usr/local/
sudo mv ./hadoop-2.7.6/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R hadoop ./hadoop # 修改文件权限
我在写文件夹名时写错了。所以用来查看当前目录下的文件夹的命令是 Is 文件名
最后查看hadoop的版本:

5.单机配置hadoop
hadoop默认为非分布式模式(本地模式)。无需进行其他配置即可。
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
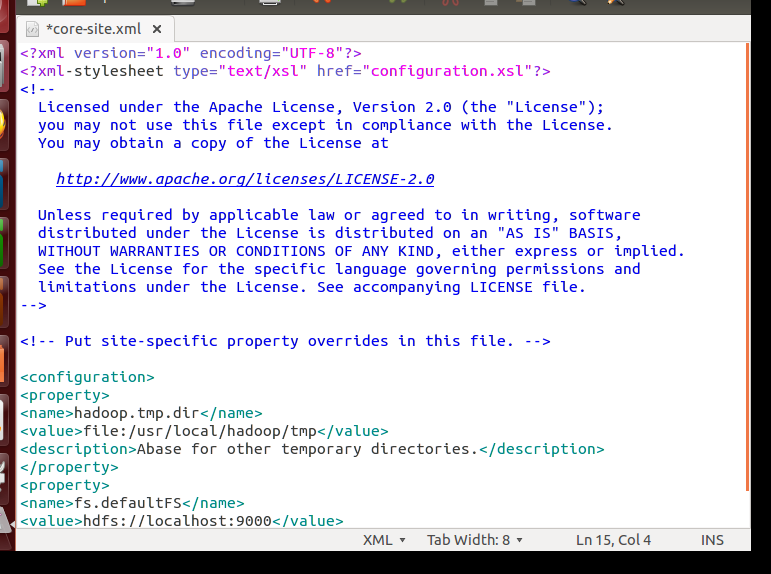
修改配置文件 core-site.xml
修改成:
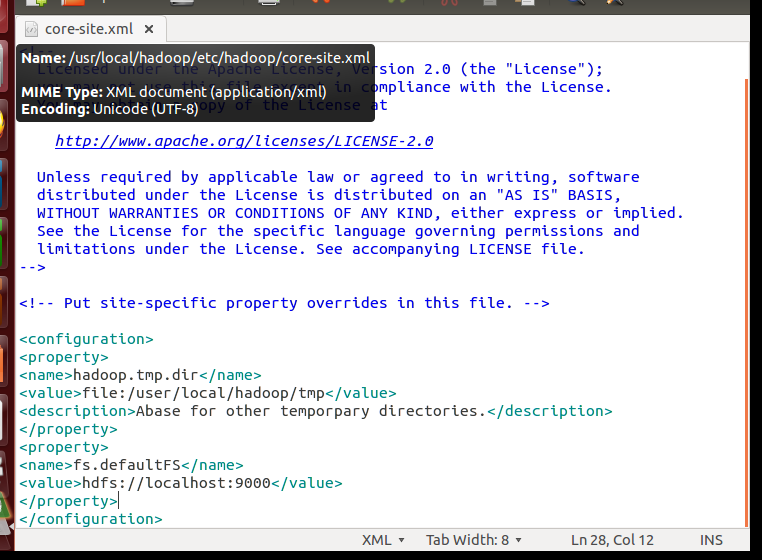
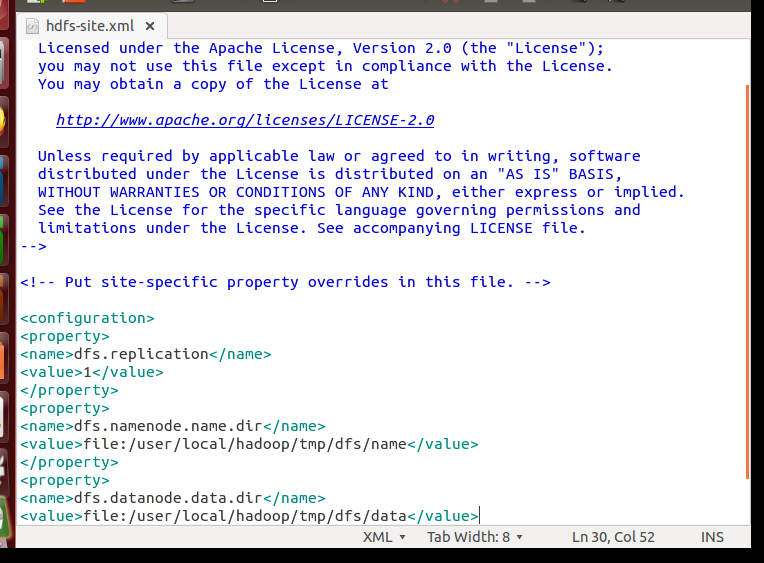
Hadoop 的运行方式是由配置文件决定的(运行 Hadoop 时会读取配置文件),因此如果需要从伪分布式模式切换回非分布式模式,需要删除 core-site.xml 中的配置项。
此外,伪分布式虽然只需要配置 fs.defaultFS 和 dfs.replication 就可以运行(官方教程如此),不过若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行。所以我们进行了设置,同时也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。
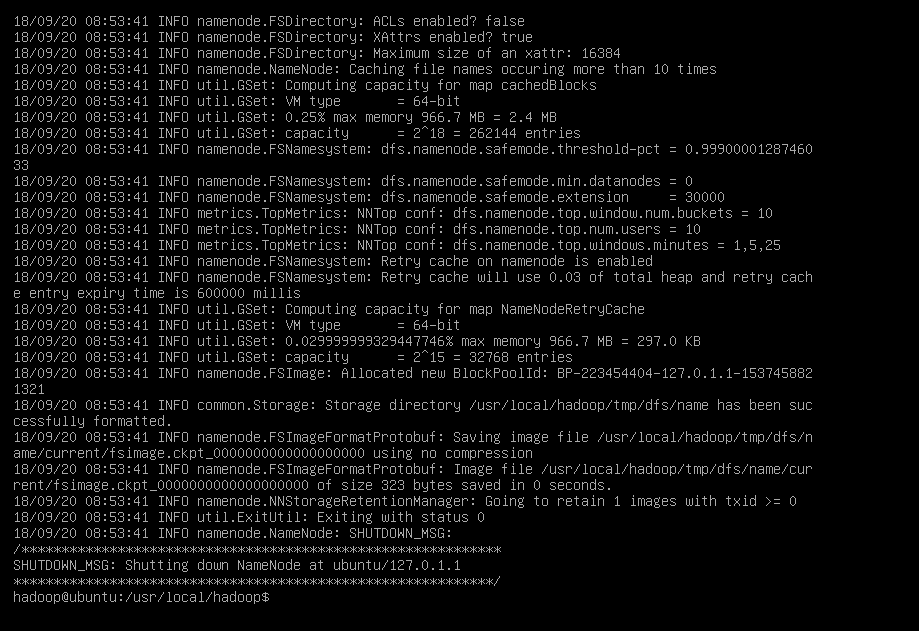
配置完成后,执行 NameNode 的格式化:
./bin/hdfs namenode -format
我执行命令时一直提醒找不到路径,需要先cd到/usr/local/hadoop目录下

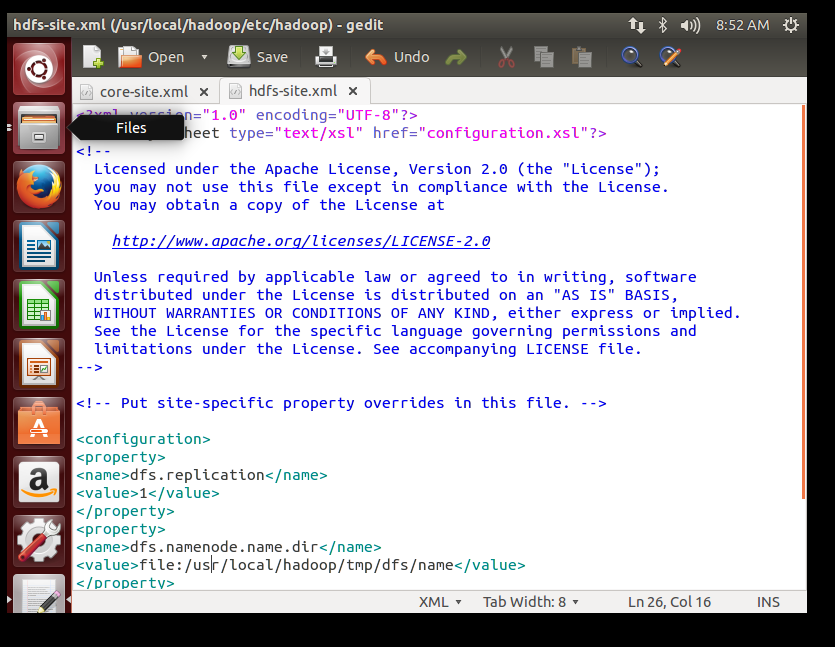
然后发现原来的xml文件写错了,正确的应该写成:
然后再执行:
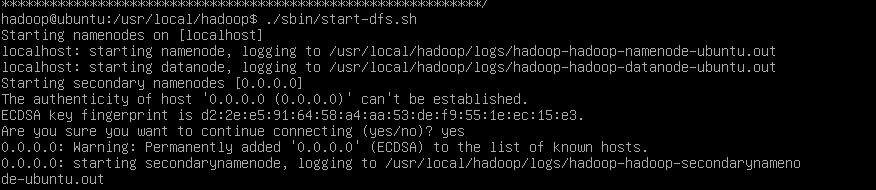
接着开启 NameNode 和 DataNode 守护进程。
./sbin/start-dfs.sh
hadoop单机配置的更多相关文章
- Data - Hadoop单机配置 - 使用Hadoop2.8.0和Ubuntu16.04
系统版本 anliven@Ubuntu1604:~$ uname -a Linux Ubuntu1604 4.8.0-36-generic #36~16.04.1-Ubuntu SMP Sun Feb ...
- Hadoop - 操作练习之单机配置 - Hadoop2.8.0/Ubuntu16.04
系统版本 anliven@Ubuntu1604:~$ uname -a Linux Ubuntu1604 4.8.0-36-generic #36~16.04.1-Ubuntu SMP Sun Feb ...
- 在Linux(Centos7)系统上对进行Hadoop分布式配置以及运行Hadoop伪分布式实例
在Linux(Centos7)系统上对进行Hadoop分布式配置以及运行Hadoop伪分布式实例 ...
- Hadoop单机模式安装-(3)安装和配置Hadoop
网络上关于如何单机模式安装Hadoop的文章很多,按照其步骤走下来多数都失败,按照其操作弯路走过了不少但终究还是把问题都解决了,所以顺便自己详细记录下完整的安装过程. 此篇主要介绍在Ubuntu安装完 ...
- 沉淀,再出发——在Ubuntu Kylin15.04中配置Hadoop单机/伪分布式系统经验分享
在Ubuntu Kylin15.04中配置Hadoop单机/伪分布式系统经验分享 一.工作准备 首先,明确工作的重心,在Ubuntu Kylin15.04中配置Hadoop集群,这里我是用的双系统中的 ...
- Hadoop:Hadoop单机伪分布式的安装和配置
http://blog.csdn.net/pipisorry/article/details/51623195 因为lz的linux系统已经安装好了很多开发环境,可能下面的步骤有遗漏. 之前是在doc ...
- Hadoop单机模式的配置与安装
Hadoop单机模式的配置与安装 单机hadoop集群正常启动后进程情况 ResourceManager NodeManager SecondaryNameNode NameNode DataNode ...
- Hadoop单机安装配置过程:
1. 首先安装JDK,必须是sun公司的jdk,最好1.6版本以上. 最后java –version 查看成功与否. 注意配置/etc/profile文件,在其后面加上下面几句: export JAV ...
- ubuntu 单机配置hadoop
前言 因为是课程要求,所以在自己电脑上安装了hadoop,由于没有使用虚拟机,所以使用单机模拟hadoop的使用,可以上传文件,下载文件. 1.安装配置JDK Ubuntu18.04是自带Java1. ...
随机推荐
- Windows中lib和DLL区别和使用
本文转载自:http://www.cppblog.com/amazon/archive/2009/09/04/95318.html 共有两种库:一种是LIB包含了函数所在的DLL文件和文件中函数位置的 ...
- 算法Sedgewick第四版-第1章基础-1.4 Analysis of Algorithms-005计测试算法
1. package algorithms.analysis14; import algorithms.util.StdOut; import algorithms.util.StdRandom; / ...
- loj10241 取石子游戏1
传送门 分析 我们发现如果在某个人取完之后还剩k+1个石子,则这个人必胜.所以我们可以将n个石子转化为n-k-1个,然后不断递归的转化下去.最后我们可以得到对于n个石子的胜负只与谁先取到n%(k+1) ...
- ipmitool查询服务器功耗
通过ipmitool查看服务器功耗 ipmitool -H $ip -I lanplus -U $user -P $password sdr elist | grep "Pwr Consum ...
- 读取txt文件的简易算法
网友在问,从一个文本文件(txt)读取数据,并做简易算法.网友的原问题大约如下, 网友的问题,虽然说是全部是数字,但没有说明是否只有一行.因此Insus.NET在实现算法时,处理文本文件是否多行,是否 ...
- java 乱码问题解决方案
java 乱码问题解决方案 一.tomcat: <Connector port="8080" maxThreads="150&qu ...
- 【探讨】linux环境,执行重启了php后php.ini依然不生效
背景: 一个linux环境配置了多个php版本的环境,同时修改了多个php.ini,执行service php-fpm restart 之后,依然不生效 原因: 没有设置好启动php.ini 参考链接 ...
- day06.1-磁盘管理
1. 添加磁盘 打开虚拟机,依次点击"编辑虚拟机设置" |—> "添加" |—> "硬盘" |—> "选择硬盘类 ...
- 安装Scrapy报错 error: Microsoft Visual C++ 14.0 is required解决方法
[问题背景]:在Windows 10系统,pip install Scrapy,报错error: Microsoft Visual C++ 14.0 is required,还有提示Twisted需要 ...
- P4841 城市规划 FFT+生成函数
\(\color{#0066ff}{ 题目描述 }\) 刚刚解决完电力网络的问题, 阿狸又被领导的任务给难住了. 刚才说过, 阿狸的国家有n个城市, 现在国家需要在某些城市对之间建立一些贸易路线, 使 ...