ubuntu 单机配置hadoop
前言
因为是课程要求,所以在自己电脑上安装了hadoop,由于没有使用虚拟机,所以使用单机模拟hadoop的使用,可以上传文件,下载文件。
1.安装配置JDK
Ubuntu18.04是自带Java1.8的,你可以在命令行输入
java -version查看,如果你想重新配置的话清查看以下的教程。
下载JDK
单击下载地址进行下载
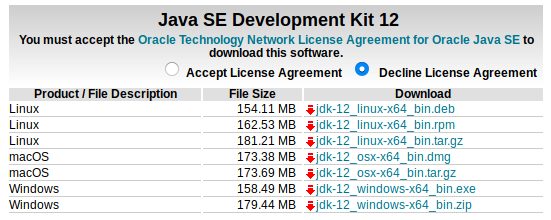
下载之前点击 Accept License Agreement, 然后下载 jdk-12_linux-64_bin.tar.gz
解压JDK
进行下载目录,打开terminal,输入
tar zxvf jdk-12_linux-64_bin.tar.gz
将解压后的文件夹移动到 /usr/local 文件夹中,在命令行中输入如下命令
sudo mv jdk-12_linux-64_bin /usr/local
jdk-12_linux-64_bin 为你解压后得到的文件夹,如果和你的不一样,清按实际情况进行修改。
配置Java环境
在terminal中输入如下命令
sudo gedit ~/.bashrc
在文件末尾写入如下内容
export JAVA_HOME=/usr/local/jdk-12_linux-64_bin
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
然后在terminal中输入如下命令
source ~/.bashrc
测试Java安装是否成功
在terminal中输入如下命令
java -version
如果配置成功的话会显示出java 的版本,再继续输入如下命令
javac
配置成功的话会显示出可以使用的命令
2.下载hadoop
请单击下载地址进行下载
下载 hadoop-2.7.6.tar.gz 这个版本,有需要可以下载其他版本
3.解压到 /opt 目录(如果有需要可以改为其他目录,后面的操作也要陆续修改)
打开terminal进入下载目录,执行命令
tar -zxvf hadoop-2.7.6.tar.gz -C /opt/
4.配置hadoop环境变量
打开命令行,输入如下命令
sudo gedit /etc/profile
在文件中添加如下代码
export HADOOP_HOME=/opt/hadoop-2.7.6
export PATH=$PATH:$HADOOP_HOME/bin
在命令行中执行如下命令
source /etc/profile
5.配置hadoop
5.1配置hadoop-env.sh
在命令行中执行如下命令
sudo gedit /opt/hadoop-2.7.6/etc/hadoop/hadoop-env.sh
找到# The java implementation to use.将其下面的一行改为:
export JAVA_HOME=/usr/local/jdk-12_linux-64_bin
如果你没有按照我上面的步骤安装java,清填写你自己的java路径
5.2 配置core-site.xml (5.2和5.3中配置文件里的文件路径和端口随自己习惯配置)
其中的IP:192.168.44.128为虚拟机ip,不能设置为localhost,如果用localhost,后面windows上用saprk连接服务器(虚拟机)上的hive会报异常
在命令行输入 ifconfig查看自己的ip地址,在下面的代码中将 192.168.44.128 改为你自己的ip就可以了
在命令行中输入如下命令
sudo gedit /opt/hadoop-2.7.6/etc/hadoop/core-site.xml
在打开的文件中添加如下内容
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:///opt/hadoop-2.7.6</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.44.128:8888</value>
</property>
</configuration>
保存并关闭文件,然后在命令行中输入以下命令
sudo gedit /opt/hadoop-2.7.6/etc/hadoop/hdfs-site.xml
在打开的文件中修改如下内容
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///opt/hadoop-2.7.6/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///opt/hadoop-2.7.6/tmp/dfs/data</value>
</property>
</configuration>
6.SSH免密登陆
在命令行中输入如下内容
sudo apt-get install openssh-server
cd ~/.ssh/
ssh localhost ssh-keygen -t rsa
/* 这个过程中持续按回车就可以了 */
cat id_rsa.pub >> authorized_keys
7.启动与停止
第一次启动hdfs需要格式化,在命令行中输入如下命令(出现询问输入Y or N,全部输Y即可)
cd /opt/hadoop-2.7.6
./bin/hdfs namenode -format
启动
./sbin/start-dfs.sh
停止
./sbin/stop-dfs.sh
验证,浏览器输入:http://192.168.44.128:50070
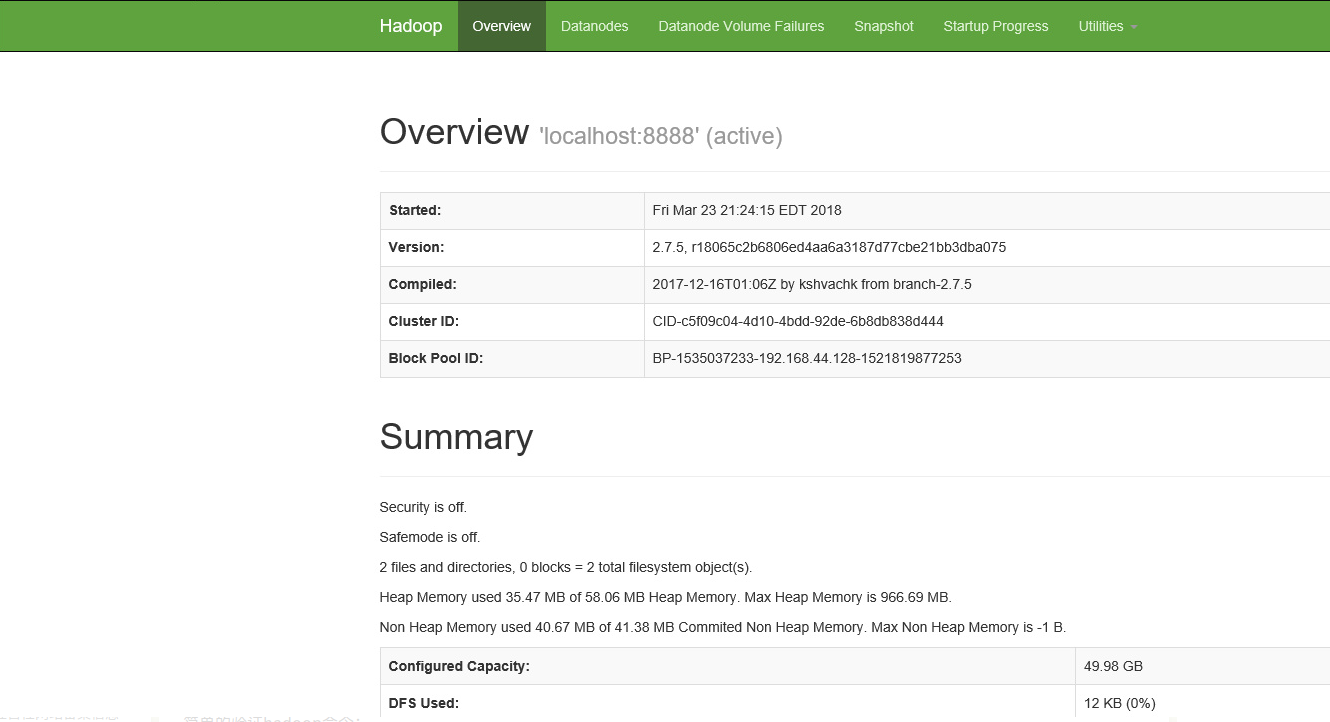
简单的验证hadoop命令:
hadoop fs -mkdir /test
在浏览器查看,出现如下图所示,即为成功
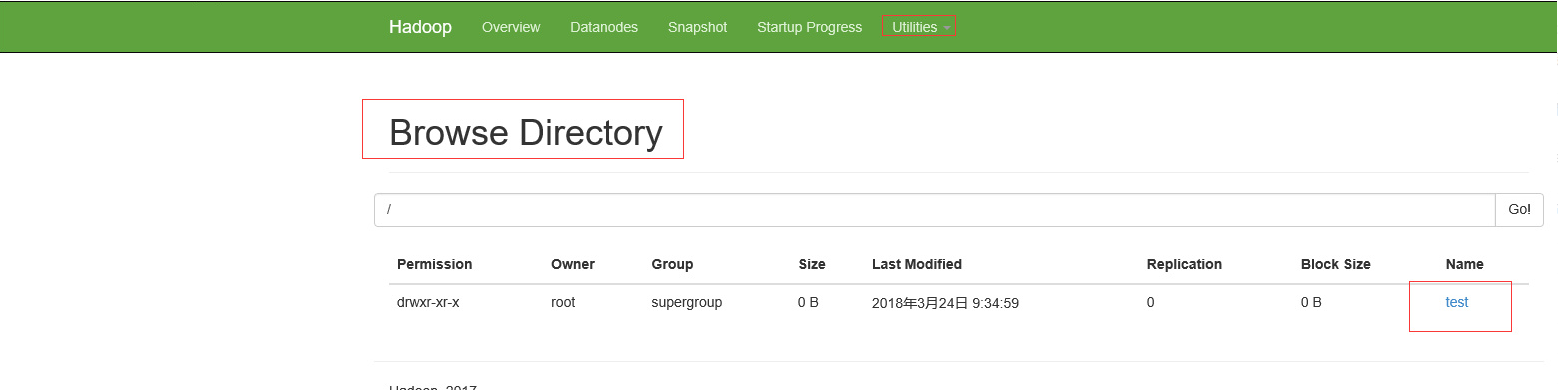
你也可以输入以下命令上传文件到hadoop
hadoop fs -put /test 1.txt /test
8.配置yarn
8.1 配置mapred-site.xml
命令行中输入如下命令:
cd /opt/hadoop-2.7.6/etc/hadoop/
cp mapred-site.xml.template mapred-site.xml
sudo gedit mapred-site.xml
在文件中添加内容
<configuration>
<!-- 通知框架MR使用YARN -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
8.2 配置yarn-site.xml
命令行中输入如下命令:
sudo gedit yarn-site.xml
在文件中添加内容
<configuration>
<!-- reducer取数据的方式是mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
8.3 yarn启动与停止
启动
cd /opt/hadoop-2.7.5
./sbin/start-yarn.sh
停止
./sbin/stop-yarn.sh
浏览器查看:http://192.168.44.128:8088
jps查看进程

输出如下所示,则表示hadoop单机模式配置成功
ubuntu 单机配置hadoop的更多相关文章
- hadoop单机配置
条件: 先下载VMware1.2,然后安装. 下载ubuntu-1.4.05-desktop-amd64.iso.下载地址:http://mirrors.aliyun.com/ubuntu-relea ...
- 沉淀,再出发——在Ubuntu Kylin15.04中配置Hadoop单机/伪分布式系统经验分享
在Ubuntu Kylin15.04中配置Hadoop单机/伪分布式系统经验分享 一.工作准备 首先,明确工作的重心,在Ubuntu Kylin15.04中配置Hadoop集群,这里我是用的双系统中的 ...
- Hadoop单机模式安装-(3)安装和配置Hadoop
网络上关于如何单机模式安装Hadoop的文章很多,按照其步骤走下来多数都失败,按照其操作弯路走过了不少但终究还是把问题都解决了,所以顺便自己详细记录下完整的安装过程. 此篇主要介绍在Ubuntu安装完 ...
- (转)单机上配置hadoop
哈哈,几天连续收到百度两次电话,均是利好消息,于是乎不知不觉的自己的工作效率也提高了,几天折腾了好久终于在单机上配置好了hadoop,然后也成功的运行了一个用例,耶耶耶耶耶耶. 转自:http://w ...
- Hadoop - 操作练习之单机配置 - Hadoop2.8.0/Ubuntu16.04
系统版本 anliven@Ubuntu1604:~$ uname -a Linux Ubuntu1604 4.8.0-36-generic #36~16.04.1-Ubuntu SMP Sun Feb ...
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)
首先要了解一下Hadoop的运行模式: 单机模式(standalone) 单机模式是Hadoop的默认模式.当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守地选 ...
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式) (转载)
Hadoop在处理海量数据分析方面具有独天优势.今天花了在自己的Linux上搭建了伪分布模式,期间经历很多曲折,现在将经验总结如下. 首先,了解Hadoop的三种安装模式: 1. 单机模式. 单机模式 ...
- Data - Hadoop单机配置 - 使用Hadoop2.8.0和Ubuntu16.04
系统版本 anliven@Ubuntu1604:~$ uname -a Linux Ubuntu1604 4.8.0-36-generic #36~16.04.1-Ubuntu SMP Sun Feb ...
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)【转】
[转自:]http://blog.csdn.net/hitwengqi/article/details/8008203 最近一直在自学Hadoop,今天花点时间搭建一个开发环境,并整理成文. 首先要了 ...
随机推荐
- Python基础(六) 函数
.函数 函数是对动作的封装 2.1函数的基本结构 #函数的定义 def 函数名(): #函数提 pass #函数的执行 函数名() 2.2参数初识 #形参 def hanshu(aaa): #参数相当 ...
- OpenProj打开不了或者提示”Failed to load Java VM Library”的错误的解决方案
一.双击打开OpenProj.exe没反应的解决方案: 1) 修改OpenProj1.4.0.ini,将Maximum Version=any改为Maximum Version=1.7,保存. 2)这 ...
- AcWing 164. 可达性统计
给定一张N个点M条边的有向无环图,分别统计从每个点出发能够到达的点的数量. 输入格式 第一行两个整数N,M,接下来M行每行两个整数x,y,表示从x到y的一条有向边. 输出格式 输出共N行,表示每个点能 ...
- Laravel ---【转】PhpStorm下Laravel代码智能提示
[转]http://blog.csdn.net/pangchengyong0724/article/details/54706775 第一步:在项目的composer.json中添加如下一行 &quo ...
- 参数传递机制之JWT
1. 什么是 JWT JWT 其全称为:JSON Web Token,简单地说就是 JSON 在 Web 上的一种带签名的标记形式.官方的定义如下: JSON Web Tokens are an op ...
- Mysql常用的查询语句,记录一下,好东西大家共享
一查询数值型数据: SELECT * FROM tb_name WHERE sum > 100; 查询谓词:>,=,<,<>,!=,!>,!<,=>,= ...
- Design Principles (设计原则)
这是我在2018年4月写的英语演讲稿,可惜没人听得懂(实际上就没几个人在听). 文章的内容是我从此前做过的项目中总结出来的经验,从我们的寝室铃声入手,介绍了可扩展性.兼容性与可复用性等概念,最后提出良 ...
- Spring Boot2(十二):手摸手教你搭建Shiro安全框架
一.前言 SpringBoot+Shiro+Mybatis完成的. 之前看了一位小伙伴的Shiro教程,跟着做了,遇到蛮多坑的(´இ皿இ`) 修改整理了一下,成功跑起来了.可以通过postman进行测 ...
- MySQL 8.0 information_schema系统库的改进
目录 information_schema有何用? mysql8.0 之前的查询方式 mysql8.0 开始的查询方式 测试5.7和8.0不同版本访问I_S库的性能 结论 information_sc ...
- plot3d网格读取写入与可视化
目录 说明 对于程序的说明 源码 说明 plot3d格式是NASA制定并大量使用的CFD网格文件格式,在CFD编程过程中经常涉及到.本文利用Python语言编写一个读取plot3d文件,写入plot3 ...