python 爬取bilibili 视频信息
抓包时发现子菜单请求数据时一般需要rid,但的确存在一些如游戏->游戏赛事不使用rid,对于这种未进行处理,此外rid一般在主菜单的响应中,但有的如番剧这种,rid在子菜单的url中,此外返回的data中含有页数相关信息,可以据此定义爬取的页面数量
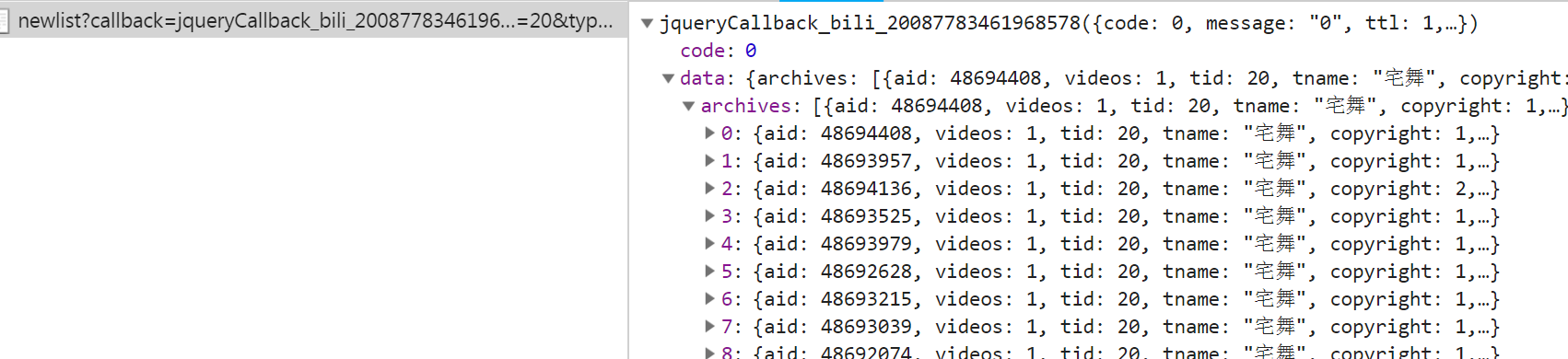
# -*- coding: utf-8 -*-
# @author: Tele
# @Time : 2019/04/08 下午 1:01
import requests
import json
import os
import re
import shutil
from lxml import etree # 爬取每个菜单的前5页内容
class BiliSplider:
def __init__(self, save_dir, menu_list):
self.target = menu_list
self.url_temp = "https://www.bilibili.com/"
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36",
# "Cookie": "LIVE_BUVID=AUTO6715546997211617; buvid3=07192BD6-2288-4BA5-9259-8E0BF6381C9347193infoc; stardustvideo=1; CURRENT_FNVAL=16; sid=l0fnfa5e; rpdid=bfAHHkDF:cq6flbmZ:Ohzhw:1Hdog8",
}
self.proxies = {
"http": "http://61.190.102.50:15845"
}
self.father_dir = save_dir def get_menu_list(self):
regex = re.compile("//")
response = requests.get(self.url_temp, headers=self.headers)
html_element = etree.HTML(response.content)
nav_menu_list = html_element.xpath("//div[@id='primary_menu']/ul[@class='nav-menu']/li/a") menu_list = list()
for item in nav_menu_list:
menu = dict()
title = item.xpath("./*/text()")
menu["title"] = title[0] if len(title) > 0 else None
href = item.xpath("./@href")
menu["href"] = "https://" + regex.sub("", href[0]) if len(href) > 0 else None # 子菜单
submenu_list = list()
sub_nav_list = item.xpath("./../ul[@class='sub-nav']/li")
if len(sub_nav_list) > 0:
for sub in sub_nav_list:
submenu = dict()
sub_title = sub.xpath("./a/span/text()")
submenu["title"] = sub_title[0] if len(sub_title) > 0 else None
sub_href = sub.xpath("./a/@href")
submenu["href"] = "https://" + regex.sub("", sub_href[0]) if len(sub_href) > 0 else None
submenu_list.append(submenu)
menu["submenu_list"] = submenu_list if len(submenu_list) > 0 else None
menu_list.append(menu)
return menu_list # rid=tid
def parse_index_url(self, url):
result_list = list()
# 正则匹配
regex = re.compile("<script>window.__INITIAL_STATE__=(.*)</script>")
response = requests.get(url, headers=self.headers)
result = regex.findall(response.content.decode())
temp = re.compile("(.*);\(function").findall(result[0]) if len(result) > 0 else None
sub_list = json.loads(temp[0])["config"]["sub"] if temp else list()
if len(sub_list) > 0:
for sub in sub_list:
# 一些子菜单没有rid,需要请求不同的url,暂不处理
if "tid" in sub:
if sub["tid"]:
sub_menu = dict()
sub_menu["rid"] = sub["tid"] if sub["tid"] else None
sub_menu["title"] = sub["name"] if sub["name"] else None
result_list.append(sub_menu)
else:
pass return result_list # 最新动态 region?callback
# 数据 newlist?callback
def parse_sub_url(self, item):
self.headers["Referer"] = item["referer"]
url_pattern = "https://api.bilibili.com/x/web-interface/newlist?rid={}&type=0&pn={}&ps=20" # 每个菜单爬取前5页
for i in range(1, 6):
data = dict()
url = url_pattern.format(item["rid"], i)
print(url)
try:
response = requests.get(url, headers=self.headers, proxies=self.proxies, timeout=10)
except:
return
if response.status_code == 200:
data["content"] = json.loads(response.content.decode())["data"]
data["title"] = item["title"]
data["index"] = i
data["menu"] = item["menu"]
# 保存数据
self.save_data(data)
else:
print("请求超时") # 一般是403,被封IP了 def save_data(self, data):
if len(data["content"]) == 0:
return
parent_path = self.father_dir + "/" + data["menu"] + "/" + data["title"]
if not os.path.exists(parent_path):
os.makedirs(parent_path)
file_dir = parent_path + "/" + "第" + str(data["index"]) + "页.txt" # 保存
with open(file_dir, "w", encoding="utf-8") as file:
file.write(json.dumps(data["content"], ensure_ascii=False, indent=2)) def run(self):
# 清除之前保存的数据
if os.path.exists(self.father_dir):
shutil.rmtree(self.father_dir) menu_list = self.get_menu_list()
menu_info = list()
# 获得目标菜单信息
# 特殊列表,一些菜单的rid必须从子菜单的url中获得
special_list = list()
for menu in menu_list:
for t in self.target:
if menu["title"] == t:
if menu["title"] == "番剧" or menu["title"] == "国创" or menu["title"] == "影视":
special_list.append(menu)
menu_info.append(menu)
break # 目标菜单的主页
if len(menu_info) > 0:
for info in menu_info:
menu_index_url = info["href"]
# 处理特殊列表
if info in special_list:
menu_index_url = info["submenu_list"][0]["href"]
# 获得rid
result_list = self.parse_index_url(menu_index_url)
print(result_list)
if len(result_list) > 0:
for item in result_list:
# 大菜单
item["menu"] = info["title"]
item["referer"] = menu_index_url
# 爬取子菜单
self.parse_sub_url(item) def main():
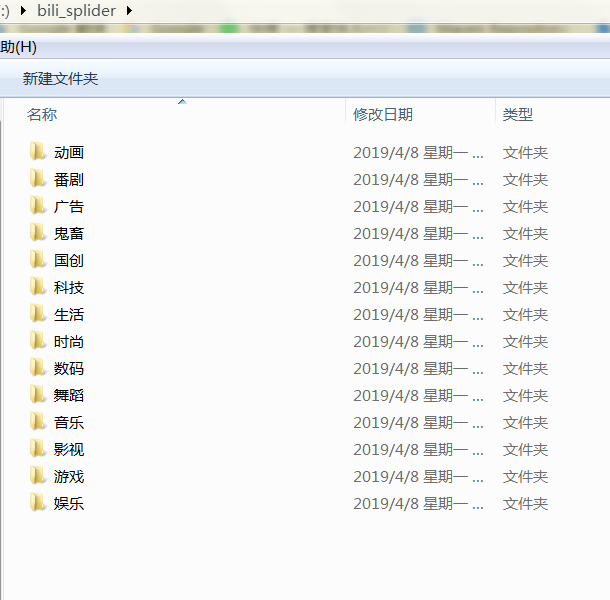
target = ["动画", "番剧", "国创", "音乐", "舞蹈", "游戏", "科技", "数码", "生活", "鬼畜", "时尚", "广告", "娱乐", "影视"]
splider = BiliSplider("f:/bili_splider", target)
splider.run() if __name__ == '__main__':
main()
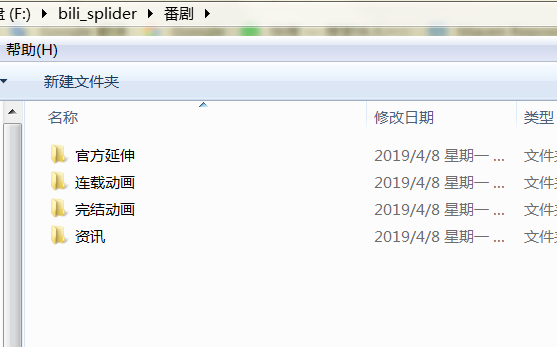
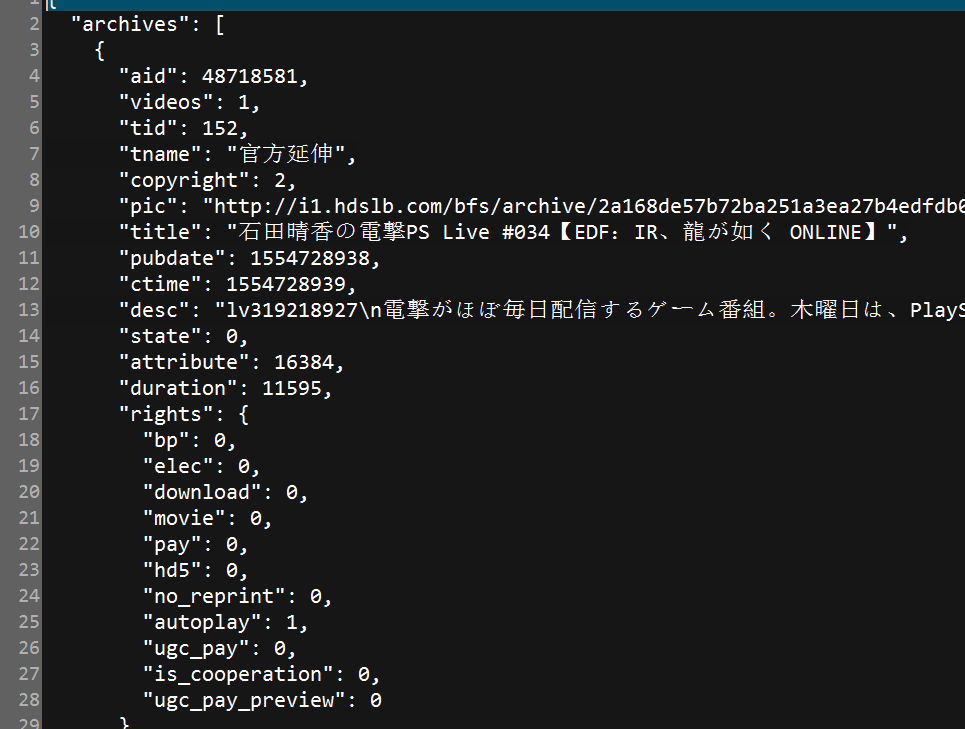
可以看到番剧少了新番时间表与番剧索引,因为这两个请求不遵循https://api.bilibili.com/x/web-interface/newlist?rid={}&type=0&pn={}&ps=20的格式,类似的不再赘述
python 爬取bilibili 视频信息的更多相关文章
- python爬取豆瓣视频信息代码
目录 一:代码 二:结果如下(部分例子) 这里是爬取豆瓣视频信息,用pyquery库(jquery的python库). 一:代码 from urllib.request import quote ...
- python 爬取bilibili 视频弹幕
# -*- coding: utf-8 -*- # @author: Tele # @Time : 2019/04/09 下午 4:50 # 爬取弹幕 import requests import j ...
- Python爬取拉勾网招聘信息并写入Excel
这个是我想爬取的链接:http://www.lagou.com/zhaopin/Python/?labelWords=label 页面显示如下: 在Chrome浏览器中审查元素,找到对应的链接: 然后 ...
- python爬取快手视频 多线程下载
就是为了兴趣才搞的这个,ok 废话不多说 直接开始. 环境: python 2.7 + win10 工具:fiddler postman 安卓模拟器 首先,打开fiddler,fiddler作为htt ...
- Python 爬取美团酒店信息
事由:近期和朋友聊天,聊到黄山酒店事情,需要了解一下黄山的酒店情况,然后就想着用python 爬一些数据出来,做个参考 主要思路:通过查找,基本思路清晰,目标明确,仅仅爬取美团莫一地区的酒店信息,不过 ...
- python 爬取豆瓣书籍信息
继爬取 猫眼电影TOP100榜单 之后,再来爬一下豆瓣的书籍信息(主要是书的信息,评分及占比,评论并未爬取).原创,转载请联系我. 需求:爬取豆瓣某类型标签下的所有书籍的详细信息及评分 语言:pyth ...
- python爬取梦幻西游召唤兽资质信息(不包含变异)
一.分析 1.爬取网站:https://xyq.163.com/chongwu/ 2.获取网页源码: request.get("https://xyq.163.com/chongwu/&qu ...
- python爬取youtube视频 多线程 非中文自动翻译
声明:我写的所有文章都是发在博客园的,我看到其他复制粘贴过去的 连个出处也不写,直接打上自己的水印...真是没的说了. 前言:前段时间搞了一些爬视频的项目,代码都写好了,这里写文章那就在来重新分析一遍 ...
- python爬取百思不得姐视频
# _*_ coding:utf-8 _*_ from Tkinter import * from ScrolledText import ScrolledText import urllib #im ...
随机推荐
- wap.css
wap.css 一.总结 1.官方有教程:英语的 http://www.developershome.com/wap/wcss/ 2.wap.css :就是控制页面在手机端样式的 3.DOCTYPE ...
- 深拷贝&浅拷贝
1.区别 浅拷贝:只拷贝了基本数据类型,引用数据类型只复制了引用,没有复制实体. 深拷贝:拷贝所有的层级属性 2.浅拷贝 (1) 直接赋值 拷贝之后,所有层级属性仍然公用了地址,会被影响 var a ...
- 查看网站使用何种框架或者技术的插件——Wappalyzer
Wappalyzer这款插件很强大,可以查看任何网站使用的技术,包括后端语言框架和前端语言框架.还有服务器是何种类型.甚至各种版本... 插件官网:https://wappalyzer.com/
- 日历控件input框默认显示当日日期
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <script sr ...
- sql server中新增一条数据后返回该数据的ID
开发中遇到的问题:在新增一条数据后往往不需要返回该数据的ID,但是有的时候可能需要返回该数据的ID以便后面的编程使用. 在这里介绍两种方法: 其一:使用存储过程: create procedure a ...
- 三星Galaxy Tab S2上市,压制苹果之心凸显
平板市场正在迎来史上最为关键的一次PK,众所周知,平板市场的苹果和三星一直是行业的领头羊,而在激烈的竞争中.三星平板似乎后劲更足.众多性能优异的产品频频推出.平板之王的称谓呼之欲出. 去年三星 ...
- springboot 使用FreeMarker模板(转)
在spring boot中使用FreeMarker模板非常简单方便,只需要简单几步就行: 1.引入依赖: <dependency> <groupId>org.springfra ...
- 大战C100K之-Linux内核调优篇--转载
原文地址:http://joyexpr.com/2013/11/22/c100k-4-kernel-tuning/ 早期的系统,系统资源包括CPU.内存等都是非常有限的,系统为了保持公平,默认要限制进 ...
- EL表达式.md
操作符 描述 . 访问一个Bean属性或者一个映射条目 [] 访问一个数组或者链表的元素 ( ) 组织一个子表达式以改变优先级 + 加 - 减或负 * 乘 / or div 除 % or mod 取模 ...
- ZOJ 1489 2^x mod n = 1 数论
http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemId=489 题目大意: 给你正整数n,求最小的x使得2^x mod n = 1. 思路 ...