bert中的分词
直接把自己的工作文档导入的,由于是在外企工作,所以都是英文写的
chinese and english tokens result
input: "我爱中国",tokens:["我","爱","中","国"]
input: "I love china habih", tokens:["I","love","china","ha","##bi","##h"] (here "##bi","##h" are all in vocabulary)
Implementation
chinese and english text would call two tokens,one is basic_tokenizer and other one is wordpiece_tokenizer as you can see from the the code below.

basic_tokenizer
if the input is chinese, the _tokenize_chinese_chars would add whitespace between chinese charater, and then call whitespace_tokenizer which separate text with whitespace,so
if the input is the query "我爱中国",would return ["我","爱","中","国"],if the input is the english query "I love china", would return ["I","love","china"]

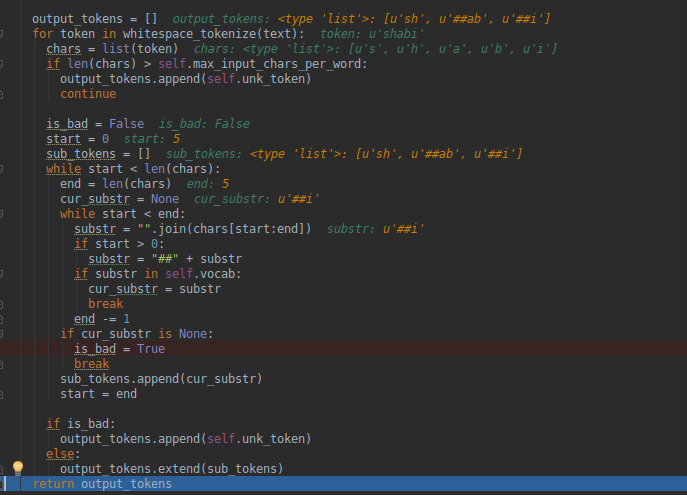
wordpiece_tokenizer
if the input is chinese ,if would iterate tokens from basic_tokenizer result, if the character is in vocabulary, just keep the same character ,otherwise append unk_token.
if the input is english, we would iterate over one word ,for example: the word is "shabi", while it is not in vocabulary,so the end index would rollback until it found "sh" in vocabulary,
in the following process, once it found a substr in vocabulary ,it would append "##" then append it to output tokens, so we can get ["sh","##ab","##i"] finally.
#65 How are out of vocabulary words handled for Chinese?
The top 8000 characters are character-tokenized, other characters are mapped to [UNK]. I should've commented this section better but it's here
Basically that's saying if it tries to apply WordPiece tokenization (the character tokenization happens previously), and it gets to a single character that it can't find, it maps it to unk_token.
#62 Why Chinese vocab contains ##word?
This is the character used to denote WordPieces, it's just an artifact of the WordPiece vocabulary generator that we use, but most of those words were never actually used during training (for Chinese). So you can just ignore those tokens. Note that for the English characters that appear in Chinese text they are actually used.
bert中的分词的更多相关文章
- 一文读懂BERT中的WordPiece
1. 前言 2018年最火的论文要属google的BERT,不过今天我们不介绍BERT的模型,而是要介绍BERT中的一个小模块WordPiece. 2. WordPiece原理 现在基本性能好一些的N ...
- 广告行业中那些趣事系列8:详解BERT中分类器源码
最新最全的文章请关注我的微信公众号:数据拾光者. 摘要:BERT是近几年NLP领域中具有里程碑意义的存在.因为效果好和应用范围广所以被广泛应用于科学研究和工程项目中.广告系列中前几篇文章有从理论的方面 ...
- Python中结巴分词使用手记
手记实用系列文章: 1 结巴分词和自然语言处理HanLP处理手记 2 Python中文语料批量预处理手记 3 自然语言处理手记 4 Python中调用自然语言处理工具HanLP手记 5 Python中 ...
- Elasticsearch中的分词器比较及使用方法
Elasticsearch 默认分词器和中分分词器之间的比较及使用方法 https://segmentfault.com/a/1190000012553894 介绍:ElasticSearch 是一个 ...
- ES中的分词器
基本概念: 全文搜索引擎会用某种算法对要建索引的文档进行分析, 从文档中提取出若干Token(词元), 这些算法称为Tokenizer(分词器), 这些Token会被进一步处理, 比如转成小写等, 这 ...
- 开源自然语言处理工具包hanlp中CRF分词实现详解
CRF简介 CRF是序列标注场景中常用的模型,比HMM能利用更多的特征,比MEMM更能抵抗标记偏置的问题. [gerative-discriminative.png] CRF训练 这类耗时的任务,还 ...
- sklearn中的分词函数countVectorizer()的改动--保留长度为1的字符串
1简述问题 使用countVectorizer()将文本向量化时发现,文本中长度唯一的字符串会被自动过滤掉,这对于我在做的情感分析来讲,一些表较重要的表达情感倾向的词汇被过滤掉,比如文本'没用的东西, ...
- nlp任务中的传统分词器和Bert系列伴生的新分词器tokenizers介绍
layout: blog title: Bert系列伴生的新分词器 date: 2020-04-29 09:31:52 tags: 5 categories: nlp mathjax: true ty ...
- 中文分词中的战斗机-jieba库
英文分词的第三方库NLTK不错,中文分词工具也有很多(盘古分词.Yaha分词.Jieba分词等).但是从加载自定义字典.多线程.自动匹配新词等方面来看. 大jieba确实是中文分词中的战斗机. 请随意 ...
随机推荐
- 理解for循环
先给大家出一个小题目,看看最终我们的i的值是多少? for(var i=0;i<10;i+=2){ if(i<=5){ i++; continue; }else{ i--; break; ...
- 一次完整的 HTTP 请求过程
一次完整的HTTP请求过程从TCP三次握手建立连接成功后开始,客户端按照指定的格式开始向服务端发送HTTP请求,服务端接收请求后,解析HTTP请求,处理完业务逻辑,最后返回一个HTTP的响应给客户端, ...
- checkbox用图片替换原始样式,并实现同样的功能
1.结构: <div class="box1"> <input/> <div class="box2"> <img / ...
- jdbc url写法(集群)
mysql集群,jdbc url写法:jdbc:mysql://[host:port],[host:port].../[database][?propertyName1][=propertyValue ...
- 安装使用hibernate tools
help-Eclipse marketplace-hibernate(搜索)-jboss tools(安装)
- 网络编程基础【day09】:socket编程入门(一)
本节内容 1.OSI七层模型 2.概述 3.关系图 4.代码逻辑图 5.socket概念 一.OSI七层模型 二.概述 socket通常也称作"套接字",用于描述IP地址和端口,是 ...
- xgboost应用
在业务中,我们经常需要对数据建模并预测.简单的情况下,我们采用 if else 判断(一棵树)即可.但如果预测结果与众多因素有关,而每一个特征的权重又不尽相同. 所以我们如何把这些特征的权重合理的找出 ...
- CM记录-Hadoop 分布式文件系统HDFS(登录、配置、监控)
1.登录(浏览器输入ip地址:7180,登录用户名和登录密码即可) 2.CM主界面(各个组件,监控图表,绿色代表运行正常.黄色代表运行不良,需要关注根据实际情况调整,红色代表故障,需要排查问题) 3. ...
- PHP7 学习笔记(三)关于PHP7如何安装调试工具Xdebug扩展以及Zephir的问题
前言: 1.自己摸索安装 2.快速安装 安装这个扩展是由于Zephir 编译不能始终通过,迫不得已啊,使用Zephir写扩展,总是出现以下错误: www@ubuntu1:~/phalcon-zephi ...
- python 小程序,猜年龄
要求如下: