elasticsearch-cluster shards
elasticsearch-cluster:
Windows下本地测试用
创建集群就要给集群起名,修改 elasticsearch.yml文件。
cluster.name: es_test //集群名 node.name: node-1 //节点名多个节点名设置不一样node.master: true //是否可为主节点,多个为true时,第一个启动的就为主节点,当主节点宕机时,其它的会自动升级为主节点。network.host: 192.168.201.105 //可通过访问的ip名 http.port: 9200 //http 端口 对外 transport.tcp.port: 9300 //tcp 端口 对内 discovery.zen.ping.unicast.hosts: ["192.168.201.105:9300", "192.168.201.105:9600"] //集群tcp ip:port discovery.zen.minimum_master_nodes: 2 //集群master 节点
修改内存文件jvm.options
-Xms2g -Xmx2g
修改另一个elasticsearch的yml文件,依照上面的格式,cluster名一致。node名往下排。
注意:yml文件中 [name]: [value] 一定要有一个空格在冒号之后,不然不被识别。
这时候启动两个elasticsearch.bat 就形成了集群。
集群操作:
集群
GET _nodes/[nodeId] //获取节点信息GET _nodes/_local //本地节点信息GET _nodes/[ip] //指定ip节点信息
GET /_nodes/stats // 节点统计get /_nodes/hot_threads //节点热线程
GET _cluster/health //查看集群GET _cluster/state //详细集群状况信息GET _cluster/stats //集群统计信息
GET _cluster/pending_tasks //正在等待的任务(新建索引,分配碎片,刷新等)
POST /_cluster/reroute // 重新路由分配分片位置
POST /_cluster/reroute
{
"commands" : [
{
"move" : {
"index" : "myindex2", "shard" : 1,
"from_node" : "node-2", "to_node" : "node-1"
}
},
{
"allocate_replica" : {
"index" : "myindex2", "shard" : 1,
"node" : "node-2"
}
}
]
}
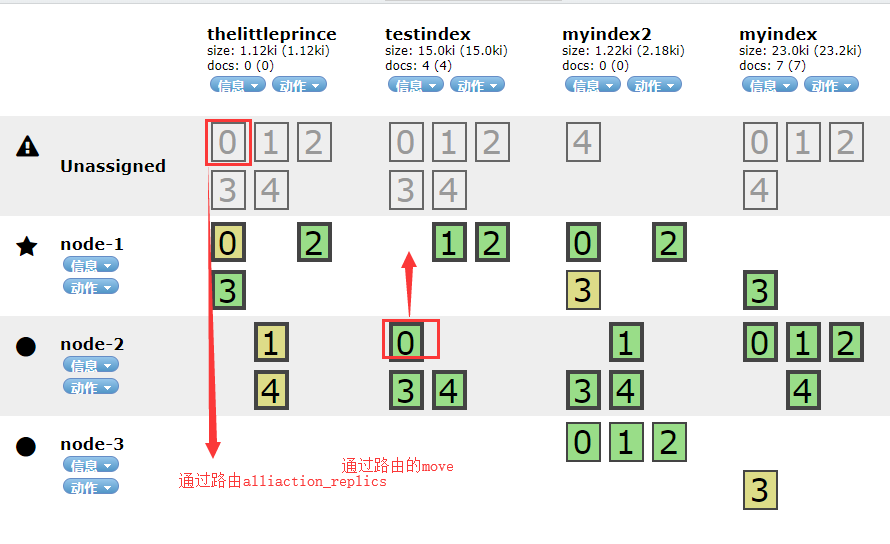
集群后,我们在查找nodes和sharp时会变的很难。不过用_cat可以让我们轻易的看懂这些。
GET _cat/shards/[myindex2] //查看分片 GET /_cat/master?v //查看主数据 GET /_cat/master?help //查看主数据帮助 GET /_cat/nodes?h=ip,port,heapPercent,name //查看节点 GET /_cat/indices //查看index GET /_cat/templates //查看模板
我们用head时可以看到有时我们的集群状况为 yellow,说明不健康。
用命令 get /cluster/health 也可以看到状况。
问题一般是有碎片有问题。我们可通过查找这些indices发现到底是哪个出的问题
get _cat/indices

然后再查看index的哪个碎片有问题。
GET _cat/shards/myindex2
参考文章
https://blog.csdn.net/laoyang360/article/details/78443006
https://www.cnblogs.com/o-andy-o/p/5067184.html
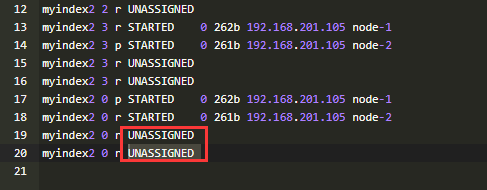
GET _cat/shards?h=index,shard,prirep,state,unassigned.reason
)INDEX_CREATED:由于创建索引的API导致未分配。 )CLUSTER_RECOVERED :由于完全集群恢复导致未分配。 )INDEX_REOPENED :由于打开open或关闭close一个索引导致未分配。 )DANGLING_INDEX_IMPORTED :由于导入dangling索引的结果导致未分配。 )NEW_INDEX_RESTORED :由于恢复到新索引导致未分配。 )EXISTING_INDEX_RESTORED :由于恢复到已关闭的索引导致未分配。 )REPLICA_ADDED:由于显式添加副本分片导致未分配。 )ALLOCATION_FAILED :由于分片分配失败导致未分配。 )NODE_LEFT :由于承载该分片的节点离开集群导致未分配。 )REINITIALIZED :由于当分片从开始移动到初始化时导致未分配(例如,使用影子shadow副本分片)。 )REROUTE_CANCELLED :作为显式取消重新路由命令的结果取消分配。 )REALLOCATED_REPLICA :确定更好的副本位置被标定使用,导致现有的副本分配被取消,出现未分配。
GET /_cluster/allocation/explain //可快速查找未分配的分片的原因
2)CLUSTER_RECOVERED的原因是副分片的数量过多,没法分配到别的地方。如下图所示
myindex2 除非再添加两个从节点,这样就可以分配这些多余的节点。
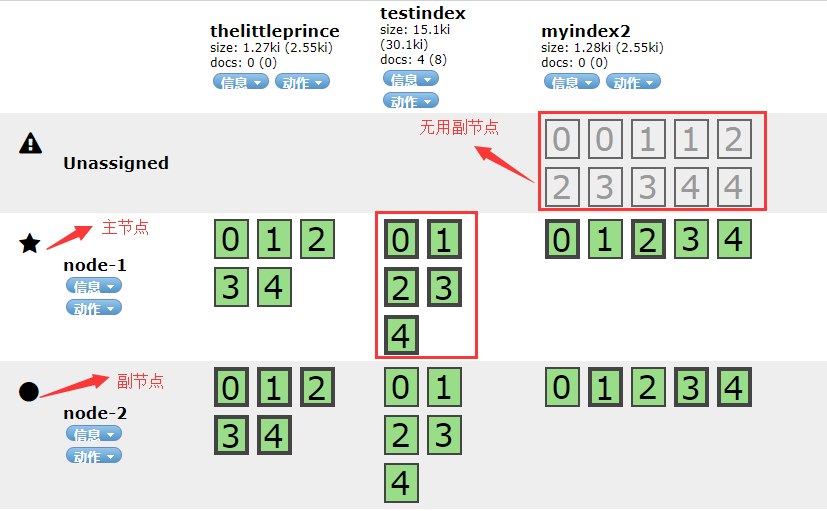
对于多余的节点我们可以清除掉,也可以扩张副节点。
PUT /myindex2/_settings
{
"number_of_replicas" : 1
}
参考文章: https://blog.csdn.net/qq_34021712/article/details/79330028
elasticsearch-cluster shards的更多相关文章
- Elasticsearch cluster health: yellow unassigned shards
查看ES各个分片的状态 $ curl -XGET http://127.0.0.1:9200/_cluster/health?pretty { "cluster_name" : & ...
- elasticsearch cluster 概述
在源码概述中我们分析过,elasticsearch源码从功能上可以分为分布式功能和数据功能,接下来这几篇会就分布式功能展开.这里首先会对cluster作简单概述,然后对cluster所涉及的主要功能详 ...
- elasticsearch基本概念理解+elasticsearch 的shards unassigned处理方法 -- 最佳运维实践 - 集群规划
1.es与MySQL的概念对比 2.概念理解 2.1 Index : 一个索引即是文档的集合 2.2 Document : 一个文档即是一个可被索引的基础单元信息,一条记录: 2.3 Replicas ...
- SearchServer Elasticsearch Cluster / kibana
S 使用nginx代理kibana并设置身份验证 https://blog.csdn.net/wyl9527/article/details/72598112 使用nginx代理kibana并设置身份 ...
- elasticsearch 分片(Shards)的理解
分片重要性 Es中所有数据均衡的存储在集群中各个节点的分片中,会影响ES的性能.安全和稳定性, 所以很有必要了解一下它. 分片是什么? 简单来讲就是咱们在ES中所有数据的文件块,也是数据的最小单元块, ...
- elasticsearch cluster 详解
上一篇通过clusterservice对cluster做了一个简单的概述, 应该能够给大家一个初步认识.本篇将对cluster的代码组成进行详细分析,力求能够对cluster做一个更清晰的描述.clu ...
- elasticsearch unassigned shards 导致RED解决
先通过命令查看节点的shard分配整体情况 curl -X GET "ip:9200/_cat/allocation?v" 说明:有16个索引未分片 2.查看未分片的索引 curl ...
- 【ElasticSearch】shards,replica,index之间的关系
1.index 包含多个shard ,在创建index的时候可以自定义shards和replica的数量 例如: 新增一个index,手动指定shard和replica的数量 PUT demo_ind ...
- Recovering unassigned shards on elasticsearch 2.x——副本shard可以设置replica为0在设置回来
Recovering unassigned shards on elasticsearch 2.x 摘自:https://z0z0.me/recovering-unassigned-shards-on ...
- Elasticsearch Configuration 中文版
##################### Elasticsearch Configuration Example ##################### # This file contains ...
随机推荐
- 学习笔记之pandas Foundations | DataCamp
pandas Foundations | DataCamp https://www.datacamp.com/courses/pandas-foundations Many real-world da ...
- JS的正则表达式简介
1.JS的正则表达式 1.1 简介 JS的正则表达式比较简单,总体上只分为两个功能:一个是test——用于匹配字符串是否符合规定的正则表达式规则:另外一个是exec——用于获取匹配到的数据. 1.2 ...
- http、TCP/IP协议与socket之间的区别(转载)
http.TCP/IP协议与socket之间的区别 https://www.cnblogs.com/iOS-mt/p/4264675.html http.TCP/IP协议与socket之间的区别 ...
- react mobx webpack 使用案例
1.package.json: { "name": "wtest", "version": "1.0.0", " ...
- 通过mapreduce把mysql的数据读取到hdfs
前面讲过了怎么通过mapreduce把mysql的一张表的数据放到另外一张表中,这次讲的是把mysql的数据读取到hdfs里面去 具体怎么搭建环境我这里就不多说了.参考 通过mapreduce把mys ...
- mysql 取整数或小数或精确位数
select cast(3.1415926 as decimal(9,2))精确到几位 select round(1024.5); 四舍五入 select floor(1024.5);取整数部分 se ...
- 搭建(WSTMart)php电商环境时缺少fileinfo函数
搭建WSTMart环境步骤: 第一步:安装phpstudy,一键安装即可 第二步:把下好的系统源码,放到一个文件夹中,并放到刚刚安装好的phpstudy下WWW文件夹下,如WWW>WSTMart ...
- element-ui 带单选框的表格
效果:不只是带单选框,点击当前行单选框选中状态网上查了一些发现很多都是只能点击当前radio选中当前行,配合element-ui的单选table时发现两个的选择状态是不一致的,所以调整了一下效果 提供 ...
- 图算法之——dijkstra算法
一.算法特点 目标:找出加权图中前往X的最短路径 适用于:无环有向加权图,且各边的权值为正 二.算法思路 三.算法示例演示 如下图,请找出结点v1到其他各个结点的最短路径: 首先创建一个字典(散列表) ...
- c# 后台AJAX
public class BackA { #region 后台 AJAX public static string GetPage(string posturl) { Stream outstream ...