机器学习-聚类(clustering)算法:K-means算法
1. 归类:
聚类(clustering):属于非监督学习(unsupervised learning)
无类别标记(class label)
2. 举例:
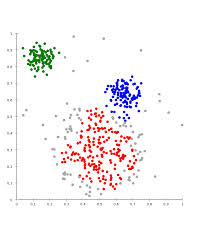
3. Kmeans算法
3.1 clustering中的经典算法,数据挖掘十大经典算法之一
3.2 算法接受参数k;将事先输入的n个数据对象划分为k个类以便使得获得的聚类满足:同一类中对象之间相似度较高,不同类之间对象相似度较小。
3.3 算法思想
以空间中k个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
3.4 算法描述
1) 选择适当的c个类的初始中心;
2) 在第k次迭代中,对任意一个样本,求其到c各中心的距离,将该样本划归到距离最近的中心所在的类。
3) 利用均值的方法更新该类的中心值,即通过求当前类所有点的均值来更新c的中心值
4) 对所有的c个聚类中心,如果利用2),3)的迭代更新后,值仍然保持不变,则迭代结束,否则继续迭代。
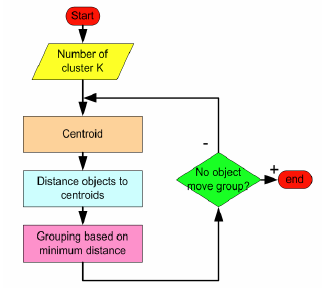
3.5 算法流程
输入:k, data[n]
1) 选择k个初始中心点,例如c[0]=data[0]...c[k-1]=data[k-1]
2) 对于data[0]...data[n],求出分别与c[0]...c[k-1]之间的距离,将其划分到距离最近的中心所属的类,如data[j] 与c[i]距离最近,data[j]就标记为i。
3) 采用均值思想更新类中心,如对于所有标记为i的点,重新计算c[i]={所有标记为i的data[i]之和}/标记为i的个数。
4) 重复2) 3),直到所有的类中心值的变化小于给定阈值。
流程图:
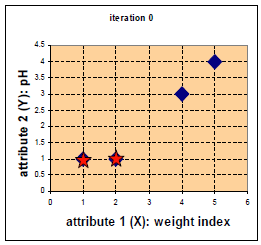
举例:

每个实例对应坐标:
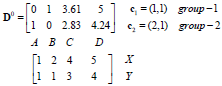 距离
距离
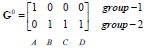 归类
归类
 中心点
中心点
 更新后中心点
更新后中心点
 距离
距离
 归类
归类
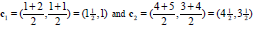 更新中心点
更新中心点
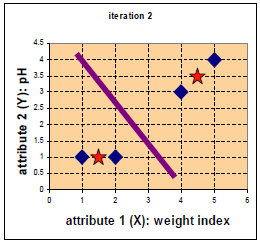 更新后中心点
更新后中心点
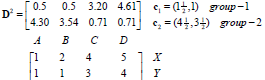 距离
距离
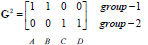 归类
归类
停止!!!

3.5 算法优缺点
优点:速度快、简单
缺点:最终结果和初始点选择有关,容易陷入局部最优,需要知道k值。
# -*- coding:utf-8 -*-
import numpy as np
def kmeans(x, k, maxIt):
numPoints, numDim = x.shape
dataSet = np.zeros((numPoints, numDim + 1))
dataSet[:, : -1] = x #dataSet所有行,从第一列到倒数第二列都等于x
#随机选取中心点 所有数据点 随机选k行
centrods = dataSet[np.random.randint(numPoints, size = k), :]
#中心点的最后一列初始化值(类标签):1到k
centrods[:, -1] = range(1, k+1)
iterations = 0
oldCentrods = None
while not shouldStop(oldCentrods, centrods, iterations, maxIt):
print("iteration: \n", iterations)
print("dataSet: \n", dataSet)
print("centroids: \n", centrods)
#为什么用copy而不是= 因为后面会做修改 oldCentrods和centrods是两部分内容
oldCentrods = np.copy(centrods)
iterations += 1
#更新类标签
updateLabels(dataSet, centrods)
#更新中心点
centrods = getCentroids(dataSet, k)
return dataSet
def shouldStop(oldCentroids, centroids, iterations, maxIt):
if iterations > maxIt:
return True
return np.array_equal(oldCentroids, centroids)
def updateLabels(dataSet, centroids):
numPoints, numDim = dataSet.shape
for i in range(0, numPoints):
dataSet[i, -1] = getLabelFromCosestCentroid(dataSet[i, : -1], centroids)
def getLabelFromCosestCentroid(dataSetRow, centroids):
label = centroids[0, -1]#初始化本条数据类标签为第一个中心点的类标签
minDis = np.linalg.norm(dataSetRow - centroids[0, : -1]) #调用内嵌的方法算距离 一直在更新
for i in range(1, centroids.shape[0]):#求与每个中心点之间的距离
dis = np.linalg.norm(dataSetRow - centroids[i, : -1])
if dis < minDis:
minDis = dis
label = centroids[i, -1]
print("minDist:", minDis)
return label
#更新中心点
def getCentroids(dataSet, k):
result = np.zeros((k, dataSet.shape[1]))
for i in range(1, k + 1):
oneCluster = dataSet[dataSet[:, -1] == i, : -1]#取出标记为i的数据(除最后一列)
result[i - 1, : -1] = np.mean(oneCluster, axis=0)
result[i - 1, -1] = i
return result
x1 = np.array([1, 1])
x2 = np.array([2, 1])
x3 = np.array([4, 3])
x4 = np.array([5, 4])
testX = np.vstack((x1,x2,x3,x4))
result = kmeans(testX, 2 ,10)
print("result:" ,result)
机器学习-聚类(clustering)算法:K-means算法的更多相关文章
- 第4章 最基础的分类算法-k近邻算法
思想极度简单 应用数学知识少 效果好(缺点?) 可以解释机器学习算法使用过程中的很多细节问题 更完整的刻画机器学习应用的流程 distances = [] for x_train in X_train ...
- SIGAI机器学习第七集 k近邻算法
讲授K近邻思想,kNN的预测算法,距离函数,距离度量学习,kNN算法的实际应用. KNN是有监督机器学习算法,K-means是一个聚类算法,都依赖于距离函数.没有训练过程,只有预测过程. 大纲: k近 ...
- 聚类算法:K-means 算法(k均值算法)
k-means算法: 第一步:选$K$个初始聚类中心,$z_1(1),z_2(1),\cdots,z_k(1)$,其中括号内的序号为寻找聚类中心的迭代运算的次序号. 聚类中心的向量值可任意设 ...
- 机器学习(四) 分类算法--K近邻算法 KNN (上)
一.K近邻算法基础 KNN------- K近邻算法--------K-Nearest Neighbors 思想极度简单 应用数学知识少 (近乎为零) 效果好(缺点?) 可以解释机器学习算法使用过程中 ...
- 机器学习(1)——K近邻算法
KNN的函数写法 import numpy as np from math import sqrt from collections import Counter def KNN_classify(k ...
- 机器学习【一】K最近邻算法
K最近邻算法 KNN 基本原理 离哪个类近,就属于该类 [例如:与下方新元素距离最近的三个点中,2个深色,所以新元素分类为深色] K的含义就是最近邻的个数.在sklearn中,KNN的K值是通过n ...
- <机器学习实战>读书笔记--k邻近算法KNN
k邻近算法的伪代码: 对未知类别属性的数据集中的每个点一次执行以下操作: (1)计算已知类别数据集中的点与当前点之间的距离: (2)按照距离递增次序排列 (3)选取与当前点距离最小的k个点 (4)确定 ...
- 机器学习(四) 机器学习(四) 分类算法--K近邻算法 KNN (下)
六.网格搜索与 K 邻近算法中更多的超参数 七.数据归一化 Feature Scaling 解决方案:将所有的数据映射到同一尺度 八.scikit-learn 中的 Scaler preprocess ...
- python 机器学习(二)分类算法-k近邻算法
一.什么是K近邻算法? 定义: 如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别. 来源: KNN算法最早是由Cover和Hart提 ...
随机推荐
- 套接字之 getsockname && getpeername
getsockname-获取本地地址:比如,在绑定的时候设置端口号为0由系统自动选择端口绑定,或者使用了INADDR_ANY通配所有地址的情况下,后面需要用到具体的地址和端口,就可以用getsockn ...
- 七、smarty--缓存的控制
1.建议缓存 $smarty->cacheing = true; //设置为2是给每一个模板设置缓存 $smarty->setCacheDir(“”); 2.处理缓存的生命周期 $smar ...
- 浅谈2-SAT
引入: 相信大家都了解过差分约束系统.差分约束系统的大体意思就是给出一些有某种关系的变量,问你是否有某种赋值使得这些关系全部成立 其实\(2-SAT\)的题目描述和这个很像(虽然解法不一样) 那么\( ...
- sharesdk短信验证码的集成
在ShareSDK官网http://mob.com/注册并创建Android应用.申请APP_key,下载SDK等 根据官网开发文档导入SDK,目录结构如下 将以上文件按需放入Android Stud ...
- Lombok 学习指南
转自:https://segmentfault.com/a/1190000020864572 一.Lombok 简介 Lombok 是一款 Java 开发插件,使得 Java 开发者可以通过其定义的一 ...
- [doker]ubuntu18安装doker
ubuntu安装doker很简单,分4个步骤: Step1:更新资源库并安装apt-transprot-https软件包. 在安装Docker前, 首拉取最新的软件资源库 wangju@wangju- ...
- "Developer tools access" 需控制另一个进程才能继续调试 解决方案
解决方案: 打开终端输入下边命令: DevToolsSecurity --status 查看状态 DevToolsSecurity --enable 输入密码,修改为enable,即可用 DevToo ...
- vim技巧1
在编辑模式或可视模式下输入的命令会另外注明.1. 查找 /xxx(?xxx) 表示在整篇文档中搜索匹配xxx的字符串, / 表示向下查找, ? 表示 ...
- CentOS7 下SaltStack部署
一,概念SaltStack是一个服务器基础架构集中化管理平台,具备配置管理.远程执行.监控等功能,一般可以理解为简化版的puppet和加强版的func.SaltStack基于Python语言实现,结合 ...
- MySQL 数据库下载
地址链接: msi:https://dev.mysql.com/downloads/installer/ zip:https://downloads.mysql.com/archives/commun ...