python3高级编程
1. SMTP发送邮件
internet相关协议:
http:网页访问相关,httplib,urllib,xmlrpclib
ftp:文件传输相关, ftplib, urllib
nntp:新闻和帖子相关, nntplib
smtp:发送邮件相关, smtplib
pop3:接收邮件相关, poplib
imap4:获取邮件相关, imaplib
telnet:命令行相关, telnetlib
gopher:信息查找相关, gopherlib, urllib
使用smtp协议发送文本邮件:
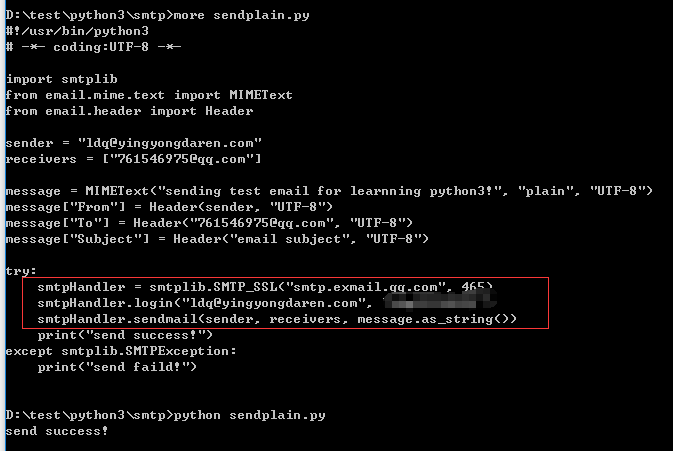
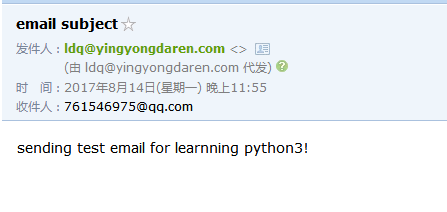
注意:需要配置有奖发送方的授权
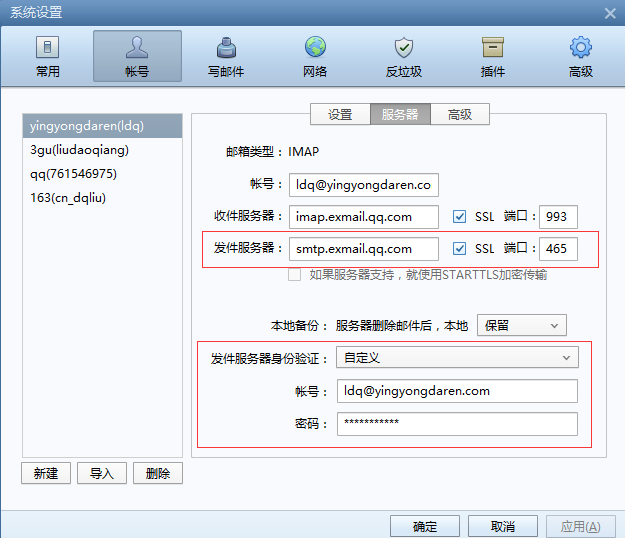
配置使用ssl登录发送方授权
详情如下
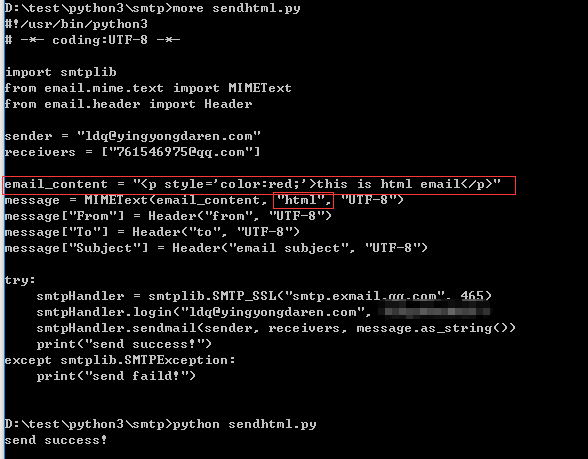
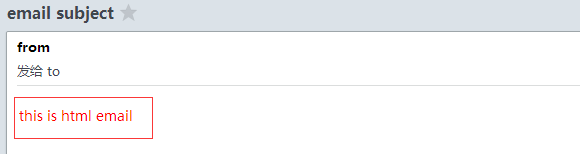
使用smtp发送html格式邮件:
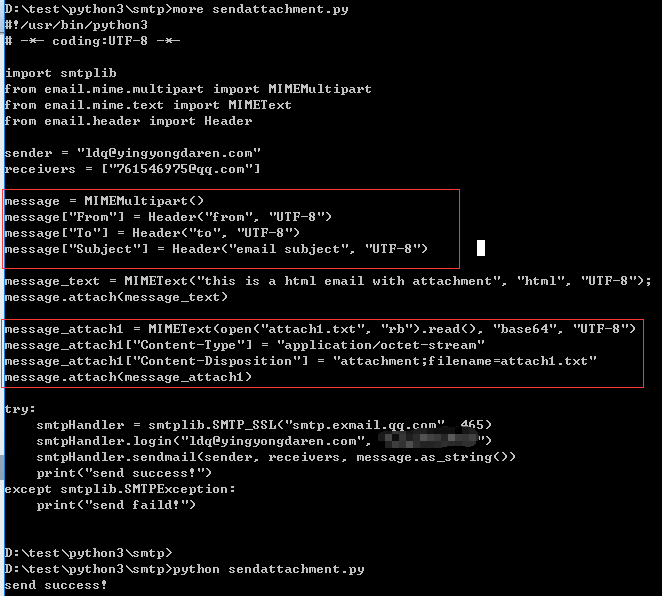
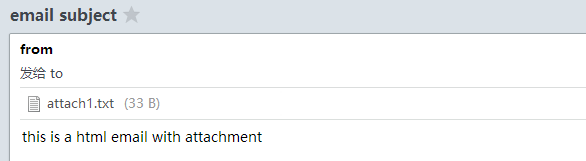
使用smtp发送附件邮件:
2.python3高级编程之socket
socket是用于在计算机进程之间通过套接字进行通信。
例:
socket
server.py
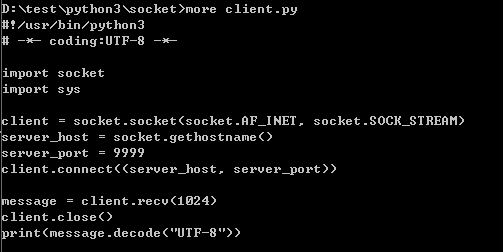
client.py
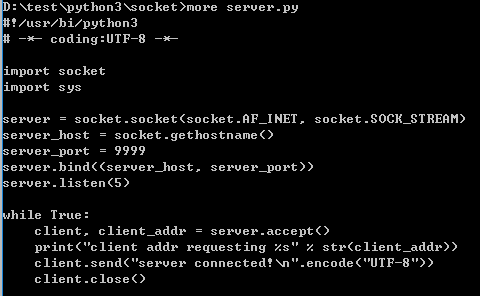
服务端server.py的代码如下:
客户端client.py的代码如下:
开启服务端:

这时服务端以守护进程的方式等待客户端网络请求
开启客户端:

结果如下:
服务端收到了客户端的请求,客户端链接服务器成功

3.python3高级编程之使用PyMySQL操作数据库
PyMySQL的下载安装:
在python3根目录下使用pip install PyMySQL安装最新版的PyMySQL
如下:

编码测试pymysql是否安装成功:
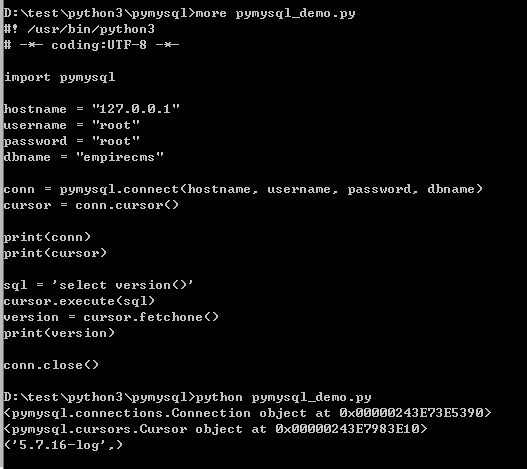
注意:文件不能命名为pymysql.py,如果该文件中使用了import pymysql则永远找不到pymysql模块
例:使用pymysql创建数据表
#!/usr/bin/python3
# -*- coding:UTF-8 -*-
import pymysql
conn = pymysql.connect('127.0.0.1', 'root', 'root', 'empirecms')
cursor = conn.cursor()
sql = 'create table if not exists test_python(' + \
'id int(8) primary key auto_increment,' + \
'name varchar(32) not null comment "username",' + \
'created_at int(10) not null default 0' + \
')engine=innoDB'
cursor.execute(sql)
conn.close()
注意:字符串拆分成多行书写时应在行末尾添加+ \
例:使用pymysql插入数据
#!/usr/bin/python3
# -*- coding:UTF-8 -*-
import pymysql
import time
conn = pymysql.connect('127.0.0.1', 'root', 'root', 'empirecms')
cursor = conn.cursor()
now = time.time()
sql = "insert into test_python(name, created_at) values('liudaoqiang', '%s')" % (now)
try:
cursor.execute(sql)
conn.commit()
except:
conn.rollback()
conn.close()
例:使用pymysql查询数据表
#!/usr/bin/python3
# -*- coding:UTF-8 -*-
import pymysql
conn = pymysql.connect('127.0.0.1', 'root', 'root', 'empirecms')
cursor = conn.cursor()
sql = "select * from test_python"
cursor.execute(sql)
data = cursor.fetchall()
for row in data:
name = row[1]
created_at = row[2]
print("name=%s and created_at=%d" % (name, created_at))
conn.close()
注意:使用fetchall()和fetchone()得到结果每一行数据都是元组而不是字典,所有取值用切片或数字下表
4.python3高级编程之cgi程序
对于python的cgi程序,首先应该配置python与web服务器的通信;以nginx为例,需要通过uwsgi完成
安装uwsgi:
pip install uwsgi
或安装最新版:
pip install https://projects.unbit.it/downloads/uwsgi-lts.tar.gz
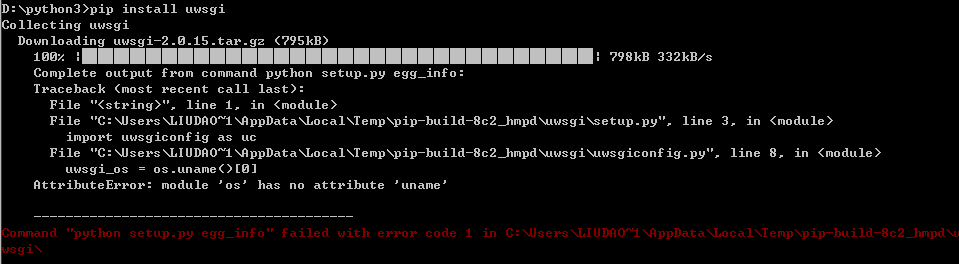
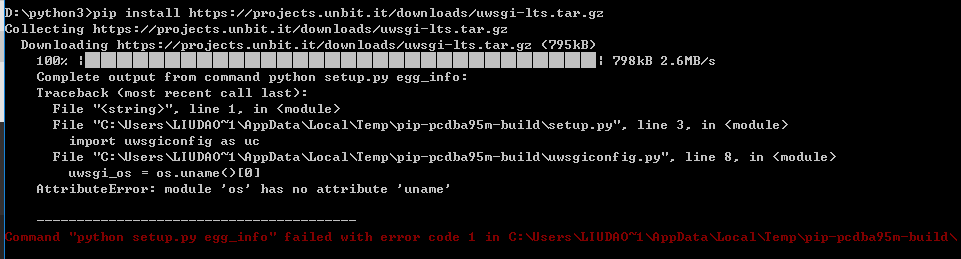
安装失败提示 AttributeError: module 'os' has no attribute 'uname'
5. python高级编程之网络爬虫scrapy框架
在windows上基于python3.6安装scrapy
pip install scrapy

发现报错,提示需要安装Microsoft Visual C++ 14.0即Microsoft Visual 2015,后台还带上了下载地址
http://landinghub.visualstudio.com/visual-cpp-build-tools
通过该下载地址下载运行库文件并安装
Microsoft Visual C++ 14.0安装成功后,再次运行pip install Scrapy安装scrapy,安装成功

使用scrapy创建一个scrapy项目
scrapy startproject scrapy_test

创建后的scrapy项目结构如下:
scrapy_test(项目跟目录)
scrapy.cfg(项目配置文件)
scrapy_test(项目的主模块)
__init__.py
items.py
middlewares.py
pipelines.py
settings.py(项目主模块配置文件)
spiders(爬虫模块)
__init__.py
紧接着,准备在新创建的scrapy项目中编写spider程序:
修改items.py如下
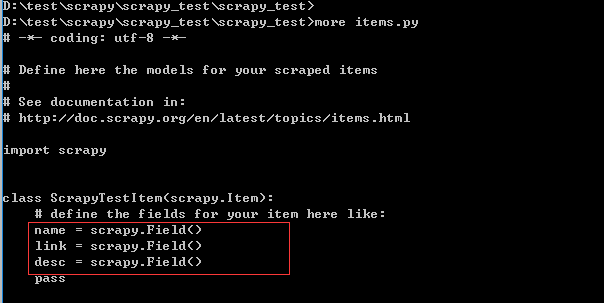
在spider目录中编写自己想要的spider
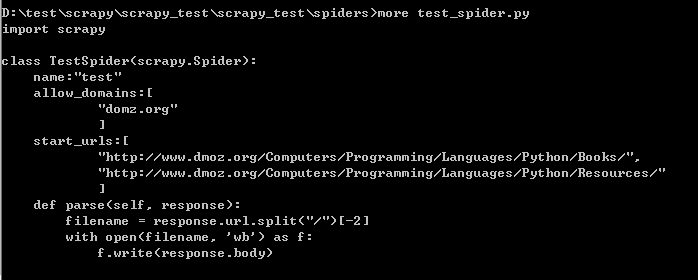
好了,现在要运行我们的spider程序了
scrapy crawl dmoz
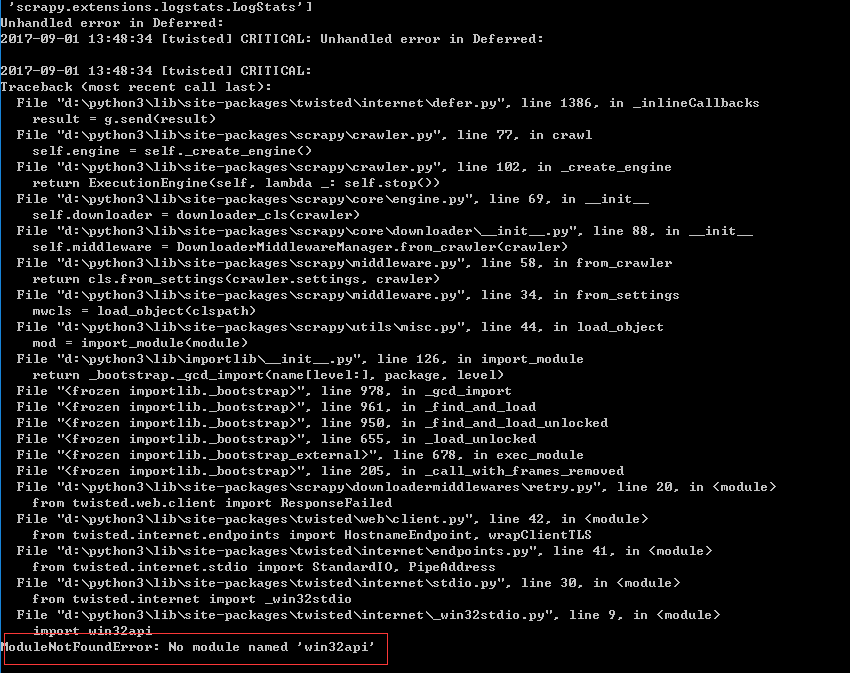
发现提示我们win32api模块没有安装,使用pip install pypiwin32 安装pypiwin32模块

安装pypiwin32成功,再次运行scrapy crawl dmoz 开始爬虫程序
D:\test\scrapy\scrapy_test>scrapy crawl dmoz
2017-09-01 14:20:01 [scrapy.utils.log] INFO: Scrapy 1.4.0 started (bot: scrapy_test)
2017-09-01 14:20:01 [scrapy.utils.log] INFO: Overridden settings: {'BOT_NAME': 'scrapy_test', 'NEWSPIDER_MODULE': 'scrap
y_test.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['scrapy_test.spiders']}
2017-09-01 14:20:01 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2017-09-01 14:20:02 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2017-09-01 14:20:02 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2017-09-01 14:20:02 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2017-09-01 14:20:02 [scrapy.core.engine] INFO: Spider opened
2017-09-01 14:20:02 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min
)
2017-09-01 14:20:02 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2017-09-01 14:20:03 [scrapy.core.engine] DEBUG: Crawled (403) <GET http://www.dmoz.org/robots.txt> (referer: None)
2017-09-01 14:20:03 [scrapy.core.engine] DEBUG: Crawled (403) <GET http://www.dmoz.org/Computers/Programming/Languages/P
ython/Books/> (referer: None)
2017-09-01 14:20:03 [scrapy.spidermiddlewares.httperror] INFO: Ignoring response <403 http://www.dmoz.org/Computers/Prog
ramming/Languages/Python/Books/>: HTTP status code is not handled or not allowed
2017-09-01 14:20:03 [scrapy.core.engine] DEBUG: Crawled (403) <GET http://www.dmoz.org/Computers/Programming/Languages/P
ython/Resources/> (referer: None)
2017-09-01 14:20:03 [scrapy.spidermiddlewares.httperror] INFO: Ignoring response <403 http://www.dmoz.org/Computers/Prog
ramming/Languages/Python/Resources/>: HTTP status code is not handled or not allowed
2017-09-01 14:20:03 [scrapy.core.engine] INFO: Closing spider (finished)
2017-09-01 14:20:03 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 734,
'downloader/request_count': 3,
'downloader/request_method_count/GET': 3,
'downloader/response_bytes': 3525,
'downloader/response_count': 3,
'downloader/response_status_count/403': 3,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2017, 9, 1, 6, 20, 3, 937597),
'httperror/response_ignored_count': 2,
'httperror/response_ignored_status_count/403': 2,
'log_count/DEBUG': 4,
'log_count/INFO': 9,
'response_received_count': 3,
'scheduler/dequeued': 2,
'scheduler/dequeued/memory': 2,
'scheduler/enqueued': 2,
'scheduler/enqueued/memory': 2,
'start_time': datetime.datetime(2017, 9, 1, 6, 20, 2, 456542)}
2017-09-01 14:20:03 [scrapy.core.engine] INFO: Spider closed (finished)
到此,ok,scrapy运行成功!!!
现在,做一个简单的案例,使用scrapy抓取京东首页的SBI图片列表区域数据并将数据保存到json文件中
创建scrapy项目:
scrapy startproject jdsbi

定义scrapy数据模型:
在items.py中定义三个字段,分别为title, promo, image
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class JdsbiItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
promo = scrapy.Field()
image = scrapy.Field()
pass
生成spider程序:
scrapy genspider jdsbispider www.jd.com

编写spider程序处理逻辑:
# -*- coding: utf-8 -*-
import scrapy
from jdsbi.items import JdsbiItem
class JdsbispiderSpider(scrapy.Spider):
name = 'jdsbispider'
allowed_domains = ['www.jd.com']
start_urls = ['http://www.jd.com/']
def parse(self, response):
node_list = response.xpath("//div[@class='pt_bi_4']/a")
print(node_list)
for node in node_list:
title = node.xpath("./p[@class='pt_bi_tit']/text()").extract()
promo = node.xpath("./p[@class='pt_bi_promo']/text()").extract()
image = node.xpath("./img/@src").extract()
item = JdsbiItem()
item["title"] = title[0]
item["promo"] = promo[0]
item["image"] = image[0]
yield item
pass
修改settings.py配置spider程序不遵从网站的robot.txt

使用scrapy crawl jdsbispider运行spider程序:
发现共抓取到0个item,原因是这些元素是ajax加载,所有没有抓取到!
python3高级编程的更多相关文章
- python3 高级编程(三) 使用@property
@property装饰器就是负责把一个方法变成属性调用的. @property广泛应用在类的定义中,可以让调用者写出简短的代码,同时保证对参数进行必要的检查,这样,程序运行时就减少了出错的可能性 cl ...
- python3 高级编程(二) 动态给类添加方法功能
class Student(object): pass 给实例绑定一个属性: >>> s = Student() >>> s.name = 'Michael' # ...
- python3 高级编程(一) 使用__slots__
使用__slots__的目的:限制实例的属性 用法:定义class的时候,定义一个特殊的__solts__变量,来限制实例能添加的属性. class Student(object): __slots_ ...
- Python3 高级编程技巧(部分)
目录: 在列表.字典.集合中筛选数据 为元组元素命名 通过列表.元组创建字典 字典排序 寻找字典的公共键 让字典保持有序 生成器函数 yield协程 同时遍历值与下标 在列表.字典.集合中筛选数据 很 ...
- python高级编程读书笔记(一)
python高级编程读书笔记(一) python 高级编程读书笔记,记录一下基础和高级用法 python2和python3兼容处理 使用sys模块使程序python2和python3兼容 import ...
- Python Flask高级编程
第1章 课程导语介绍课程的内容1-1 开宗明义 试看1-2 课程维护与提问 第2章 Flask的基本原理与核心知识本章我们首先介绍Python官方推荐的最佳包与虚拟环境管理工具:Pipenv.接着我们 ...
- Python高级编程-Python一切皆对象
Python高级编程-Python一切皆对象 Python3高级核心技术97讲 笔记 1. Python一切皆对象 1.1 函数和类也是对象,属于Python的一等公民 ""&qu ...
- 第三章:Python高级编程-深入类和对象
第三章:Python高级编程-深入类和对象 Python3高级核心技术97讲 笔记 3.1 鸭子类型和多态 """ 当看到一直鸟走起来像鸭子.游泳起来像鸭子.叫起来像鸭子 ...
- 第九章:Python高级编程-Python socket编程
第九章:Python高级编程-Python socket编程 Python3高级核心技术97讲 笔记 9.1 弄懂HTTP.Socket.TCP这几个概念 Socket为我们封装好了协议 9.2 cl ...
随机推荐
- wxWidgets与其它GUI工具库比较
WxWidgets Compared To Other Toolkits Some general notes: wxWidgets not only works for C++, but als ...
- 使用 ctypes 进行 Python 和 C 的混合编程
Python 和 C 的混合编程工具有很多,这里介绍 Python 标准库自带的 ctypes 模块的使用方法. 初识 Python 的 ctypes 要使用 C 函数,需要先将 C 编译成动态链接库 ...
- 4-STM32物联网开发WIFI(ESP8266)+GPRS(Air202)系统方案数据篇(云端电脑(Windows)安装配置数据库,使用本地Navicat for MySQL和手机APP 远程连接测试)
3-STM32物联网开发WIFI(ESP8266)+GPRS(Air202)系统方案数据篇(安装配置数据库,使用Navicat for MySQL和手机APP 连接测试) 根据前面的教程把软件复制到云 ...
- Bing.com在.NET Core 2.1上运行!
Bing.com在.NET Core 2.1上运行! 相关知识请参考.netCore开发团队博客(https://blogs.msdn.microsoft.com/dotnet/) Bing.com是 ...
- 配置Nginx虚拟主机
实验环境 一台最小化安装的CentOS 7.3虚拟机 配置基本环境 1. 安装nginx yum install -y epel-* yum isntall -y nginx vim 2. 建立虚机主 ...
- 单链表的python实现
首先说下线性表,线性表是一种最基本,最简单的数据结构,通俗点讲就是一维的存储数据的结构. 线性表分为顺序表和链接表: 顺序表示指的是用一组地址连续的存储单元依次存储线性表的数据元素,称为线性表的顺序存 ...
- Westore 1.0 正式发布 - 小程序框架一个就够
世界上最小却强大的小程序框架 - 100多行代码搞定全局状态管理和跨页通讯 Github: https://github.com/dntzhang/westore 众所周知,小程序通过页面或组件各自的 ...
- Python全栈开发之路 【第二篇】:Python基础之数据类型
本节内容 一.字符串 记住: 有序类型:列表,元组,字符串 ---> 都可迭代: 无序类型:字典,集合 ---> 不可迭代: 特性:不可修改 class str(object): &quo ...
- 剑指offer--2.替换空格
题目: 请实现一个函数,将一个字符串中的每个空格替换成“%20”.例如,当字符串为We Are Happy.则经过替换之后的字符串为We%20Are%20Happy. 思路:可以使用replace或者 ...
- nginx Location 语法基础知识
URL地址匹配是Nginx配置中最灵活的部分 Location 支持正则表达式匹配,也支持条件匹配,用户可以通过location指令实现Nginx对动丶静态网页的过滤处理. Nginx locatio ...