大数据实操2 - hadoop集群访问——Hadoop客户端访问、Java API访问
上一篇中介绍了hadoop集群搭建方式,本文介绍集群的访问。集群的访问方式有两种:hadoop客户端访问,Java API访问。
一、集群客户端访问
Hadoop采用C/S架构,可以通过客户端对集群进行操作,其实在前面搭建的集群环境中,每个集群节点都可以作为一个客户端进行集群访问,但是一般场景下,会将集群服务器作为整体,从外部设置客户端对集群进行访问。
为了能从集群服务器外部访问,需要一台与集群服务器在同一网段的主机(可以与集群节点Ping通),安装hadoop作为客户端机器,并将该机器与集群服务器配置到同一集群内。
1、安装JDK
2、安装Hadoop
与集群搭建中一样,需要安装hadopp
3、客户端机器配置core-site.xml

4、客户端机器配置mapred-site.xml
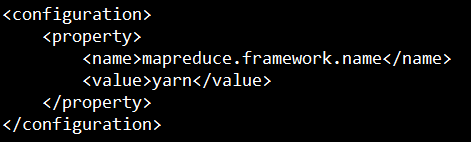
5、客户端机器配置yarn-site.xml

二、网页访问
namenodeIP:50070
sourcemangerIP:8088
三、Java API访问
此种方法通过hadoop提供的API编写客户端程序,从而实现对hadoop的操作。java程序的编写一般是在Windows环境下的,因此需要首先对win环境进行配置。
(一)Win环境配置
1、下载并解压hadoop安装包
这里注意不要放到含有空格的目录下,虽然网上有些解决方案,但是我试了没起作用,放到不含空格的目录下最省事。
2、配置环境变量
- 增加HADOOP_HOME变量,变量值为你的hadoop目录

- 配置Path变量,增加内容:
%HADOOP_HOME%\bin\
%HADOOP_HOME\sbin\

3、配置hadoop中的java home
- 编辑文件,hadoop目录下\etc\hadoop\hadoop-env.cmd
修改其中JAVA_HOME变量,变量值为jdk地址,jdk的地址注意同样不要包含空格,我是把原来的jdk复制一份到了没有空格的目录下。

4、放置文件
下载https://github.com/steveloughran/winutils
其中对应版本bin目录下的winutil.exe放置到你的hadoop目录的bin目录下
hadoop.dll文件放置到C:Windows\System32下
(二)Java程序开发
1、导入jar包
hadoop安装文件夹/share/hadoop路径下为hadoop提供的jar包,按需导入。
2、编程
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Before;
import org.junit.Test; import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException; public class HdfsClient { FileSystem fs = null; public static void main(String[] args){
//创建一个配置对象,用于设置集群上的块大小,副本数量等。
Configuration conf = new Configuration();
conf.set("dfs.replication", "2");
conf.set("dfs.blocksize", "64m"); //uri,
//root:指定用户,如果不填写,会默认当前win用户 try {
// 构造一个访问指定HDFS的客户端对象,
// 参数一:HDFS系统的URI,
// 参数二:客户端要配置参数。
// 参数三:客户端用户名
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.1.237:9000/"), conf, "root");
fs.copyFromLocalFile(new Path("I:/[neubt]Friends_搜狐原画版.torrent"), new Path("/home/"));
fs.close(); } catch (URISyntaxException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} } @Before
public void inint() throws Exception {
URI uri = new URI("hdfs://192.168.1.237:9000/"); Configuration conf = new Configuration();
conf.set("dfs.replication", "2");
conf.set("dfs.blocksize", "64m");
fs = FileSystem.get(new URI("hdfs://192.168.1.237:9000/"), conf, "root"); } /*
从hdfs下载文件
*/
@Test
public void testDownLoad() throws IOException {
Path localPath = new Path("I:/hdfstest/Friends_搜狐原画版.torrent");
System.out.println(localPath); fs.copyToLocalFile(new Path("/home/[neubt]Friends_搜狐原画版.torrent"), localPath);
// fs.copyToLocalFile(new Path("/home/log4j-1.2.17.zip"), new Path("/hdfstest"));
fs.close(); } }
文件的上传未涉及访问本地磁盘,文件下载时则需要调用本地方法来实现对本地磁盘库的访问,本地磁盘库的访问需要调用hadoop提供的C语言库,该库在hadoop的安装文件中提供,因此需要将hadoop安装包中的本地方法添加到环境变量中。
大数据实操2 - hadoop集群访问——Hadoop客户端访问、Java API访问的更多相关文章
- Hadoop集群(四) Hadoop升级
Hadoop前面安装的集群是2.6版本,现在升级到2.7版本. 注意,这个集群上有运行Hbase,所以,升级前后,需要启停Hbase. 更多安装步骤,请参考: Hadoop集群(一) Zookeepe ...
- 在windows远程提交任务给Hadoop集群(Hadoop 2.6)
我使用3台Centos虚拟机搭建了一个Hadoop2.6的集群.希望在windows7上面使用IDEA开发mapreduce程序,然后提交的远程的Hadoop集群上执行.经过不懈的google终于搞定 ...
- hadoop集群启动报错: java.io.IOException: Incompatible clusterIDs
java.io.IOException: Incompatible clusterIDs in /export/hadoop-2.7.5/hadoopDatas/datanodeDatas2: nam ...
- Hadoop集群部署-Hadoop 运行集群后Live Nodes显示0
可以尝试以下步骤解决: 1 ,分别删除:主节点从节点的 /usr/local/hadoop-2.6.2/etc/tmp 下得所有文件; 2: 编辑cd usr/local/hadoop-2.6. ...
- 【hadoop】——window下elicpse连接hadoop集群基础超详细版
1.Hadoop开发环境简介 1.1 Hadoop集群简介 Java版本:jdk-6u31-linux-i586.bin Linux系统:CentOS6.0 Hadoop版本:hadoop-1.0.0 ...
- Ganglia监控Hadoop集群的安装部署[转]
Ganglia监控Hadoop集群的安装部署 一. 安装环境 Ubuntu server 12.04 安装gmetad的机器:192.168.52.105 安装gmond的机 器:192.168.52 ...
- Hadoop集群(第7期)_Eclipse开发环境设置
1.Hadoop开发环境简介 1.1 Hadoop集群简介 Java版本:jdk-6u31-linux-i586.bin Linux系统:CentOS6.0 Hadoop版本:hadoop-1.0.0 ...
- hadoop系列一:hadoop集群安装
转载请在页首明显处注明作者与出处 http://www.cnblogs.com/zhuxiaojie/p/6384393.html 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据 ...
- 配置两个Hadoop集群Kerberos认证跨域互信
两个Hadoop集群开启Kerberos验证后,集群间不能够相互访问,需要实现Kerberos之间的互信,使用Hadoop集群A的客户端访问Hadoop集群B的服务(实质上是使用Kerberos Re ...
- Hadoop集群(三) Hbase搭建
前面已经完成Zookeeper和HDFS的安装,本文会详细介绍Hbase的安装步骤.以及安装过程中遇到问题的汇总. 系列文章: Hadoop集群(一) Zookeeper搭建 Hadoop集群(二 ...
随机推荐
- awk 正则匹配指定字段次数统计
1. 文本数据 head 12315_industry_business.csv name,business,label,label_name 沧州光松房屋拆迁有限公司,旧房拆迁.改造:物业服务(依法 ...
- Ajax异步请求阻塞情况的解决办法(asp.net MVC Session锁的问题)
讨论今天这个问题之前,我们先来看下浏览器公布的资源并发数限制个数,如下图 不难看出,目前主流浏览器支持都是最多6个并发 需要注意的是,浏览器的并发请求数目限制是针对同一域名的 意即,同一时间针对同一域 ...
- spark2.1源码分析4:spark-network-common模块的设计原理
spark-network-common模块底层使用netty作为通讯框架,可以实现rpc消息.数据块和数据流的传输. Message类图: 所有request消息都是RequestMessage的子 ...
- 记一次深度系统安装至windows系统盘提示挂载为只读模式问题
记一次深度系统安装至windows系统盘提示挂载为只读模式问题 来到新公司新电脑自己要安装deepin,安装的时候没考虑双系统直接装至默认win系统盘,导致deepin启动后提示如下: 提示多个挂载分 ...
- java——collection总结
Collection 来源于Java.util包,是非常实用常用的数据结构!!!!!字面意思就是容器.具体的继承实现关系如下图,先整体有个印象,再依次介绍各个部分的方法,注意事项,以及应用场景. ...
- 数据库中id为自增
使用find_and_modify函数可以设置mongo的id为自增 且可以支持原有的高并发操作,find_and_modify函数完成更新查找两个操作其是原子性的操作 代码:(auto_id.py) ...
- 关于ueditor插入不了动态地图
1. 打开编辑器根目录下面的ueditor.all.js文件,找到: table.setAttribute("data-sort", cmd == "enablesort ...
- 在c#中利用keep-alive处理socket网络异常断开的方法
本文摘自 http://www.z6688.com/info/57987-1.htm 最近我负责一个IM项目的开发,服务端和客户端采用TCP协议连接.服务端采用C#开发,客户端采用Delphi开发.在 ...
- spring命名空间
作为一名入门级菜鸟的我,在刚开始学spring框架的时候,对于命名空间不是很理解,只是在跟着老师敲代码.随着后来学习的深入,慢慢了解到命名空间的意义.如果你没有引入相应的命名空间,就不能引用相应的标签 ...
- Centos7的防火墙关闭
第一步.centos7安装service 第二步. 或者可以不用service,有另一个办法.