初识HDFS原理及框架
目录
1. HDFS是什么
HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目,首先它是一个文件系统,用于存储文件,通过目录树来定位文件位置;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
2.HDFS的优缺点
之所以选择HDFS来存储数据,是具有如下优势:
| No | 优势 | 描述 |
| 1 | 高容错性 |
|
| 2 | 适合批处理 |
|
| 3 | 适合大数据处理 |
|
| 4 | 流式文件访问 |
|
| 5 | 可构建在廉价机器上 |
|
HDFS也有不适合的场景:
| No | 缺点 | 描述 |
| 1 | 低延时数据访问 |
|
| 2 | 小文件存储 |
|
| 3 | 并发写入、文件随机修改 |
|
3. HDFS框架结构
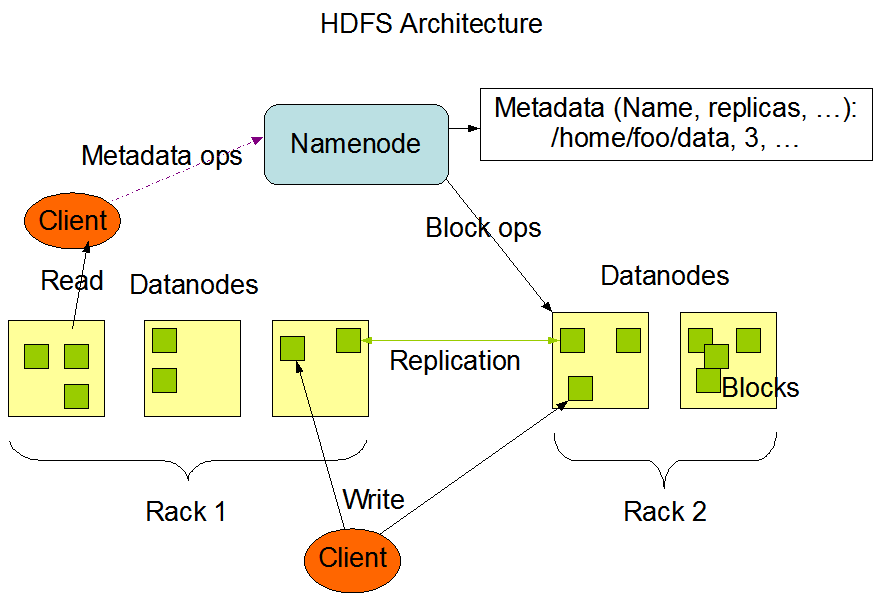
HDFS 采用Master/Slave的架构来存储数据,这种架构主要由四个部分组成,分别为HDFS Client、NameNode、DataNode和Secondary NameNode。下面我们分别介绍这四个组成部分。
| No | 角色 | 功能描述 |
| 1 | Client:就是客户端 |
|
| 2 | NameNode:就是 master,它是一个主管、管理者 |
|
| 3 | DataNode:就是Slave。NameNode 下达命令,DataNode 执行实际的操作 |
|
| 4 | Secondary NameNode:并非 NameNode 的热备。当NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务 |
|
4. HDFS的读写流程
4.1. HDFS的块大小
HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数(dfs.blocksize)来规定,默认大小在hadoop2.x版本中是128M,老版本中是64M
HDFS的块比磁盘的块大,其目的是为了最小化寻址开销。如果块设置得足够大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。因而,传输一个由多个块组成的文件的时间取决于磁盘传输速率。
如果寻址时间约为10ms,而传输速率为100MB/s,为了使寻址时间仅占传输时间的1%,我们要将块大小设置约为100MB。默认的块大小128MB。
块的大小:10ms*100*100M/s = 100M
4.2. HDFS写数据流程
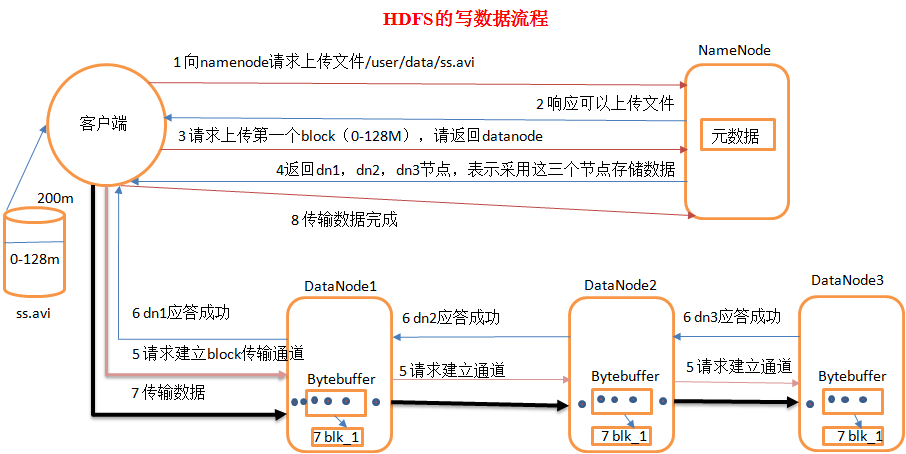
1)客户端向namenode请求上传文件,namenode检查目标文件是否已存在,父目录是否存在。
2)namenode返回是否可以上传。
3)客户端请求第一个 block上传到哪几个datanode服务器上。
4)namenode返回3个datanode节点,分别为dn1、dn2、dn3。
5)客户端请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成
6)dn1、dn2、dn3逐级应答客户端
7)客户端开始往dn1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,dn1收到一个packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答
8)当一个block传输完成之后,客户端再次请求namenode上传第二个block的服务器。(重复执行3-7步)
4.3. HDFS读数据流程
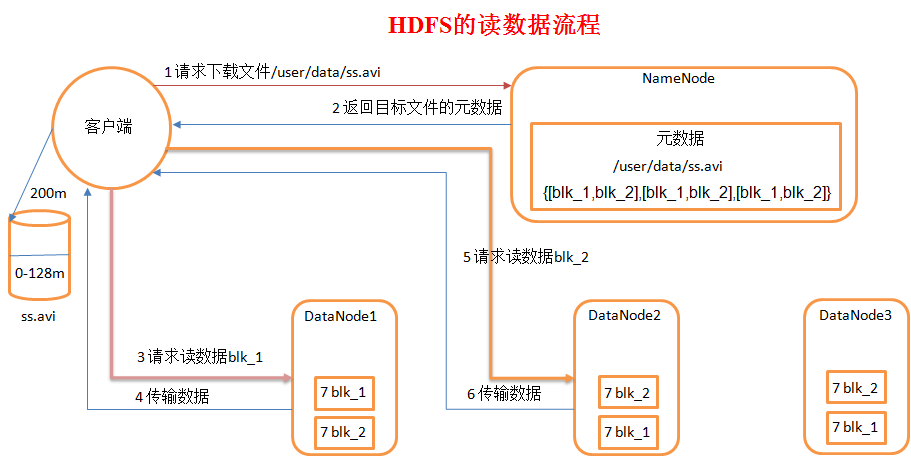
1)客户端向namenode请求下载文件,namenode通过查询元数据,找到文件块所在的datanode地址。
2)挑选一台datanode(就近原则,然后随机)服务器,请求读取数据。
3)datanode开始传输数据给客户端(从磁盘里面读取数据放入流,以packet为单位来做校验)。
4)客户端以packet为单位接收,先在本地缓存,然后写入目标文件。
5.HDFS命令
1)基本语法
bin/hadoop fs 具体命令
2)常用命令实操
(1)-help:输出这个命令参数
bin/hdfs dfs -help rm
(2)-ls: 显示目录信息
hadoop fs -ls /
(3)-mkdir:在hdfs上创建目录
hadoop fs -mkdir -p /aaa/bbb/cc/dd
(4)-moveFromLocal从本地剪切粘贴到hdfs
hadoop fs - moveFromLocal /home/hadoop/a.txt /aaa/bbb/cc/dd
(5)-moveToLocal:从hdfs剪切粘贴到本地(尚未实现)
hadoop fs -help moveToLocal
-moveToLocal <src> <localdst> :
Not implemented yet
(6)--appendToFile :追加一个文件到已经存在的文件末尾
hadoop fs -appendToFile ./hello.txt /hello.txt
(7)-cat :显示文件内容
(8)-tail:显示一个文件的末尾
hadoop fs -tail /weblog/access_log.1
(9)-chgrp 、-chmod、-chown:linux文件系统中的用法一样,修改文件所属权限
hadoop fs -chmod 666 /hello.txt
hadoop fs -chown someuser:somegrp /hello.txt
(10)-copyFromLocal:从本地文件系统中拷贝文件到hdfs路径去
hadoop fs -copyFromLocal ./jdk.tar.gz /aaa/
(11)-copyToLocal:从hdfs拷贝到本地
hadoop fs -copyToLocal /user/hello.txt ./hello.txt
(12)-cp :从hdfs的一个路径拷贝到hdfs的另一个路径
hadoop fs -cp /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2
(13)-mv:在hdfs目录中移动文件
hadoop fs -mv /aaa/jdk.tar.gz /
(14)-get:等同于copyToLocal,就是从hdfs下载文件到本地
hadoop fs -get /user/hello.txt ./
(15)-getmerge :合并下载多个文件,比如hdfs的目录 /aaa/下有多个文件:log.1, log.2,log.3,...
hadoop fs -getmerge /aaa/log.* ./log.sum
(16)-put:等同于copyFromLocal
hadoop fs -put /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2
(17)-rm:删除文件或文件夹
hadoop fs -rm -r /aaa/bbb/
(18)-rmdir:删除空目录
hadoop fs -rmdir /aaa/bbb/ccc
(19)-df :统计文件系统的可用空间信息
hadoop fs -df -h /
(20)-du统计文件夹的大小信息
hadoop fs -du -s -h /user/data/wcinput
188.5 M /user/data/wcinput
hadoop fs -du -h /user/data/wcinput
188.5 M /user/data/wcinput/hadoop-2.7.2.tar.gz
97 /user/data/wcinput/wc.input
(21)-count:统计一个指定目录下的文件节点数量
hadoop fs -count /aaa/
hadoop fs -count /user/data/wcinput
1 2 197657784 /user/data/wcinput
嵌套文件层级; 包含文件的总数
(22)-setrep:设置hdfs中文件的副本数量
hadoop fs -setrep 3 /aaa/jdk.tar.gz
这里设置的副本数只是记录在namenode的元数据中,是否真的会有这么多副本,还得看datanode的数量。如果只有3台设备,最多也就3个副本,只有节点数的增加到10台时,副本数才能达到10。
6.HDFS相关参数
| No | 参数名称 | 默认值 | 所属参数文件 | 描述 |
| 1 |
dfs.block.size, dfs.blocksize |
134217728 | hdfs-site.xml | 以字节计算的新建 HDFS 文件默认块大小。请注意该值也用作 HBase 区域服务器 HLog 块大小。 |
| 2 | dfs.replication | 3 | hdfs-site.xml | HDFS文件的数据块复制份数。 |
| 3 | dfs.webhdfs.enabled | TRUE | hdfs-site.xml | 启用 WebHDFS 界面,启动50070端口。 |
| 4 | dfs.permissions | TRUE | hdfs-site.xml | HDFS文件权限检查。 |
| 5 | dfs.datanode.failed.volumes.tolerated | 0 | hdfs-site.xml | 能够导致DN挂掉的坏硬盘最大数,默认0就是只要有1个硬盘坏了,DN就会shutdown。 |
| 6 |
dfs.data.dir, dfs.datanode.data.dir |
xxx,xxx | hdfs-site.xml | DataNode数据保存路径,可以写多块硬盘,逗号分隔 |
| 7 |
dfs.name.dir, dfs.namenode.name.dir |
xxx,xxx | hdfs-site.xml | NameNode本地元数据存储目录,可以写多块硬盘,逗号分隔 |
| 8 | fs.trash.interval | 1 | core-site.xml | 垃圾桶检查频度(分钟)。要禁用垃圾桶功能,请输入0。 |
| 9 | dfs.safemode.min.datanodes | 0 | hdfs-site.xml | 指定在名称节点存在 safemode 前必须活动的 DataNodes 数量。输入小于或等于 0 的值,以在决定启动期间是否保留 safemode 时将活动的 DataNodes 数量考虑在内。值大于群集中 DataNodes 的数量时将永久保留 safemode。 |
| 10 | dfs.client.read.shortcircuit | TRUE | hdfs-site.xml | 启用 HDFS short circuit read。该操作允许客户端直接利用 DataNode 读取 HDFS 文件块。这样可以提升本地化的分布式客户端的性能 |
| 11 | dfs.datanode.handler.count | 3 | hdfs-site.xml | DataNode 服务器线程数。默认为3,较大集群,可适当调大些,比如8。 |
| 12 | dfs.datanode.max.xcievers, dfs.datanode.max.transfer.threads | 256 | hdfs-site.xml | 指定在 DataNode 内外传输数据使用的最大线程数,datanode在进行文件传输时最大线程数 |
| 13 | dfs.balance.bandwidthPerSec, dfs.datanode.balance.bandwidthPerSec | 1048576 | hdfs-site.xml | 每个 DataNode 可用于平衡的最大带宽。单位为字节/秒 |
以上参数中可能有2个名称,前面一个是老版本1.x的后面的是新版本2.x的。
以上资料都是从网络上复制汇总过来的,如介意请告知
初识HDFS原理及框架的更多相关文章
- 读Hadoop3.2源码,深入了解java调用HDFS的常用操作和HDFS原理
本文将通过一个演示工程来快速上手java调用HDFS的常见操作.接下来以创建文件为例,通过阅读HDFS的源码,一步步展开HDFS相关原理.理论知识的说明. 说明:本文档基于最新版本Hadoop3.2. ...
- HDFS原理介绍
HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.是根据google发表的论文翻版的.论文为GFS(Google File System)Googl ...
- 初识轻量级Java开源框架 --- Spring
初识轻量级Java开源框架 --- Spring 作者:egg 微博:http://weibo.com/xtfggef 出处:http://blog.csdn.net/zhangerqing spri ...
- HDFS 原理、架构与特性介绍--转载
原文地址:http://www.uml.org.cn/sjjm/201309044.asp 本文主要讲述 HDFS原理-架构.副本机制.HDFS负载均衡.机架感知.健壮性.文件删除恢复机制 1:当前H ...
- Hadoop之HDFS原理及文件上传下载源码分析(上)
HDFS原理 首先说明下,hadoop的各种搭建方式不再介绍,相信各位玩hadoop的同学随便都能搭出来. 楼主的环境: 操作系统:Ubuntu 15.10 hadoop版本:2.7.3 HA:否(随 ...
- Hadoop之HDFS原理及文件上传下载源码分析(下)
上篇Hadoop之HDFS原理及文件上传下载源码分析(上)楼主主要介绍了hdfs原理及FileSystem的初始化源码解析, Client如何与NameNode建立RPC通信.本篇将继续介绍hdfs文 ...
- atitit.http get post的原理以及框架实现java php
atitit.http get post的原理以及框架实现java php 1. 相关的设置 1 1.1. urlencode 1 1.2. 输出流的编码 1 1.3. 图片,文件的post 1 2. ...
- 【Hadoop】HDFS原理、元数据管理
1.HDFS原理 2.元数据管理原理
- HDFS 原理、架构与特性介绍
本文主要讲述 HDFS原理-架构.副本机制.HDFS负载均衡.机架感知.健壮性.文件删除恢复机制 1:当前HDFS架构详尽分析 HDFS架构 •NameNode •DataNode •Senc ...
随机推荐
- resin发布spring-boot项目报错“java.lang.NoSuchMethodError: org.jboss.logging.Logger.getMessageLogger”
说白了还是jar包冲突问题,直接说解决方式: 首先将resin/lib下的validation-api-1.0.0.GA.jar替换成项目中的包validation-api-2.0.1.Final.j ...
- 自动化测试全套流程(一)-搭建Jenkins环境
前提 既然要做自动化测试,那我们就做得彻底一些,将整套系统部署在Linux服务器上,在搭建Jenkins环境之前,我已经通过VirtualBox安装了一个CentOS的服务器,搭建Jenkins是基于 ...
- php测试工具
如果是测压力有apache的ab如果要看性能则有xdebug和xhprof.还有linux的strace命令来跟踪程序的执行时的系统调用
- 深入浅出SharePoint——Caml快速开发
适用于Visual Studio 2010的Caml智能感知工具 http://visualstudiogallery.msdn.microsoft.com/15055544-fda0-42db-a6 ...
- linux下的线程学习(二)
#include <iostream> #include <pthread.h> void cleanup(void *arg) { printf("cleanup: ...
- 怎么在Linux环境下通过VS Code调试Python 3+?
今天突然想写一写Python了,于是就开始弄.使用源码包安装好Python3.6.6之后,发现Linux下只能通过python3来调用python 3.6.6.如果直接使用python的话,调用的是系 ...
- Requests中文乱码解决方案
分析: r = requests.get(“http://www.baidu.com“) **r.text返回的是Unicode型的数据. 使用r.content返回的是bytes型的数据. 也就是说 ...
- leetcode shell
leetcode 195. 第十行 # | | 第一种是先取出前10行,然后取出最后一行.(但是不足10行,也可以取出最后一行) 正解: tail -n +K :从第K行取出所有 然后取出第一行 le ...
- D、CSL 的字符串 【栈+贪心】 (“新智认知”杯上海高校程序设计竞赛暨第十七届上海大学程序设计春季联赛)
题目传送门:https://ac.nowcoder.com/acm/contest/551#question 题目描述 CSL 以前不会字符串算法,经过一年的训练,他还是不会……于是他打算向你求助. ...
- 3、Spring Cloud - Eureka(构建服务端/客户端)
3.1.Eureka简介 3.1.1.什么是 Eureka 和Consul.Zookeeper 类似, Eureka 是一个用于服务注册和发现的组件,最开始主要应用 于亚马逊公司旗下的云计算服务平台 ...