关键词抽取:pagerank,textrank
摘抄自微信公众号:AI学习与实践
TextRank,它利用图模型来提取文章中的关键词。由 Google 著名的网页排序算法 PageRank 改编而来的算法。
PageRank
PageRank 是一种通过网页之间的超链接来计算网页重要性的技术,以 Google 创办人 Larry Page 之姓来命名,Google 用它来体现网页的相关性和重要性。
PageRank 通过网络浩瀚的超链接关系来确定一个页面的等级,把从 A 页面到 B 页面的链接解释为 A 页面给 B 页面投票,Google 根据 A 页面(甚至链接到 A的页面)的 等级和投票 目标的等级来决定 B 的等级。
简单的说,一个高等级的页面可以使其他低等级页面的等级提升。
整个互联网可以看作是一张有向图图,网页是图中的节点,网页之间的链接就是图中的边。如果网页 A 存在到网页 B 的链接,那么就有一条从网页 A 指向网页 B 的有向边。
构造完图后,使用下面的公式来计算网页 i的重要性(PR值):

TextRank
TextRank 公式在 PageRank 公式的基础上,为图中的边引入了权值的概念:

用
TextRank 算法计算图中各节点的得分时,同样需要给图中的节点指定任意的初值,通常都设为1。然后递归计算直到收敛,即图中任意一点的误差率小于给定的极限值时就可以达到收敛,一般该极限值取 0.0001。
使用 TextRank 提取关键词
现在是要提取关键词,如果把单词视作图中的节点(即把单词看成句子),那么所有边的权值都为 0(两个单词没有相似性),所以通常简单地把所有的权值都设为 1。
此时算法退化为 PageRank,因而把关键字提取算法称为 PageRank 也不为过。
我们把文本拆分为单词,过滤掉停用词(可选),并只保留指定词性的单词(可选),就得到了单词的集合。假设一段文本依次由下面的单词组成:
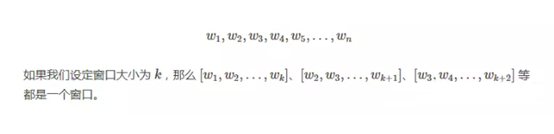
现在将每个单词作为图中的一个节点,同一个窗口中的任意两个单词对应的节点之间存在着一条边。然后利用投票的原理,将边看成是单词之间的互相投票,经过不断迭代,每个单词的得票数都会趋于稳定。
一个单词的得票数越多,就认为这个单词越重要。
使用 TextRank 提取摘要
自动摘要,就是从文章中自动抽取关键句。人类对关键句的理解通常是能够概括文章中心的句子,而机器只能模拟人类的理解,即拟定一个权重的评分标准,给每个句子打分,之后给出排名靠前的几个句子。
基于 TextRank 的自动文摘属于自动摘录,通过选取文本中重要度较高的句子形成文摘。
依然使用 TextRank 公式:

关键词抽取:pagerank,textrank的更多相关文章
- 数据挖掘:基于Spark+HanLP实现影视评论关键词抽取(1)
1. 背景 近日项目要求基于爬取的影视评论信息,抽取影视的关键字信息.考虑到影视评论数据量较大,因此采用Spark处理框架.关键词提取的处理主要包含分词+算法抽取两部分.目前分词工具包较为主流的,包括 ...
- 关键词提取算法TextRank
很久以前,我用过TFIDF做过行业关键词提取.TFIDF仅仅从词的统计信息出发,而没有充分考虑词之间的语义信息.现在本文将介绍一种考虑了相邻词的语义关系.基于图排序的关键词提取算法TextRank. ...
- 自然语言处理工具hanlp关键词提取图解TextRank算法
看一个博主(亚当-adam)的关于hanlp关键词提取算法TextRank的文章,还是非常好的一篇实操经验分享,分享一下给各位需要的朋友一起学习一下! TextRank是在Google的PageRan ...
- 关键词提取算法-TextRank
今天要介绍的TextRank是一种用来做关键词提取的算法,也可以用于提取短语和自动摘要.因为TextRank是基于PageRank的,所以首先简要介绍下PageRank算法. 1.PageRank算法 ...
- 【API进阶之路】逆袭!用关键词抽取API搞定用户需求洞察
摘要: 老大说,我这份用关键词抽取API搞定的用户需求洞察报告,简直比比市场调研的科班人士做得还好. 最近这半个月的午饭,那可是相当不错,市场老大天天请吃饭,不是外面下馆子,就是从家带饺子.说是感谢我 ...
- 使用 Node.js 对文本内容分词和关键词抽取
npm install nodejieba var nodejieba = require("nodejieba"); var result = nodejieba.cut(&qu ...
- python 结巴分词简介以及操作
中文分词库:结巴分词 文档地址:https://github.com/fxsjy/jieba 代码对 Python 2/3 均兼容 全自动安装:easy_install jieba 或者 pip in ...
- Spark项目应用-电子商务大数据分析总结
一. 数据采集(要求至少爬取三千条记录,时间跨度超过一星期)数据采集到本地文件内容 爬取详见:python爬取京东评论 爬取了将近20000条数据,156个商品种类,用时2个多小时,期间中断数 ...
- TextRank:关键词提取算法中的PageRank
很久以前,我用过TFIDF做过行业关键词提取.TFIDF仅仅从词的统计信息出发,而没有充分考虑词之间的语义信息.现在本文将介绍一种考虑了相邻词的语义关系.基于图排序的关键词提取算法TextRank [ ...
随机推荐
- soa---java 多线程的---锁
如今soa 与分布式计算已经成为互联网公司技术的标配 那他包括的知识点应该熟悉了解.并以此为基础,去应用,调优各种soa的框架. 包括例如以下的四点.是分布式的基础. a java 多 ...
- ios中GDataXML解析XML文档
参考文章 http://blog.csdn.net/ryantang03/article/details/7868246 适合解析一个节点多个属性要用GDataXml 格式如下 <?xml ve ...
- HttpClient库设置超时
HttpClient库API跟Lucene一样,每个版本的API都变化很大,这有点让人头疼.就好比创建一个HttpClient对象吧,每一个版本的都不一样. 3.X是正常的Java语法 HttpCli ...
- [转]webMethods公司简介
原文链接 webMethods公司简介 webMethods,Inc.(美国纳斯达克股市上市代号:WEBM)为著名业务整合软件供应商之一.公司于1996年创立,总部位于美国佛吉尼亚州(Virginia ...
- select收数据
之前写的服务器端 表示都无法收到client发的数据,找不到原因,原来是有个socket接收数据缓冲木有设置,现在设置后就可以正常收到数据啦! server端: #include <winsoc ...
- 【LeetCode】235. Lowest Common Ancestor of a Binary Search Tree (2 solutions)
Lowest Common Ancestor of a Binary Search Tree Given a binary search tree (BST), find the lowest com ...
- Tensorflow 相关概念
一.概述 人工智能:artificial intelligence 权重: weights 偏差:biases 图中包含输入( input).塑形( reshape). Relu 层( Relulay ...
- 【IL】IL指令详解
名称 说明 Add 将两个值相加并将结果推送到计算堆栈上. Add.Ovf 将两个整数相加,执行溢出检查,并且将结果推送到计算堆栈上. Add.Ovf.Un 将两个无符号整数值相加,执行溢出检查,并且 ...
- linux文件系统 - 初始化(一)
术语表: struct task:进程 struct mnt_namespace:命名空间 struct mount:挂载点 struct vfsmount:挂载项 struct file:文件 st ...
- Markdown 使用教程
前言 以前经常在 github 中看到 .md 格式的文件,一直没有注意,也不明白为什么文本文档的后缀不是 .txt ,后来无意中看到了 Markdown,看到了用这个东西写得一些web界面等特别的规 ...