Solr4.8.0源码分析(21)之SolrCloud的Recovery策略(二)
Solr4.8.0源码分析(21)之SolrCloud的Recovery策略(二)
题记: 前文<Solr4.8.0源码分析(20)之SolrCloud的Recovery策略(一)>中提到Recovery有两种策略,一是PeerSync和Replication。本节将具体介绍下PeerSync策略。
PeeySync是Solr的优先选择策略,每当需要进行recovery了,Solr总是会先去判断是否需要进入PeerSync,只有当PeerSync被设置为跳过或者PeerSync时候发现没符合条件才会进入到Replication。这是由PeeySync的特性决定的,PeeySync是面向中断时间短,需要recovery的document个数较少时使用的策略,因此它Recovery的速度较快,对Solr的影响较小。而Replication则是对中断时间长,需要recovery数量多的情况下进行的,耗时较长。
前文已经介绍了Recovery的总体流程,那么本文就直接来介绍PeerSync的流程了,请看下图所示:
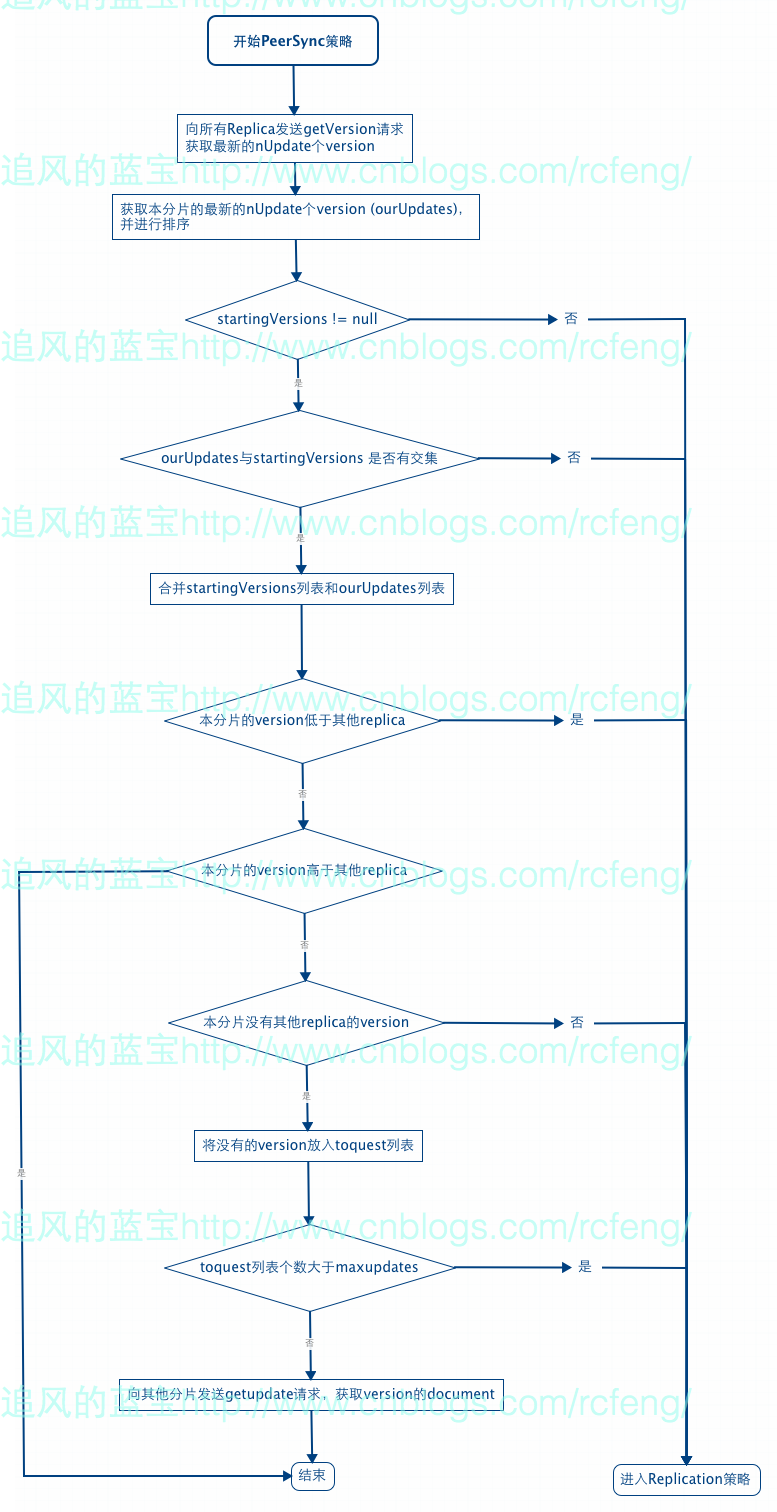
- 首先 Solr会向所有Replica发送getversion的请求,来获取最新的nupdate个version(默认是100个)。
// Fire off the requests before getting our own recent updates (for better concurrency)
// This also allows us to avoid getting updates we don't need... if we got our updates and then got their updates, they would
// have newer stuff that we also had (assuming updates are going on and are being forwarded).
for (String replica : replicas) {
requestVersions(replica);
} private void requestVersions(String replica) {
SyncShardRequest sreq = new SyncShardRequest();
sreq.purpose = 1;
sreq.shards = new String[]{replica};
sreq.actualShards = sreq.shards;
sreq.params = new ModifiableSolrParams();
sreq.params.set("qt","/get");
sreq.params.set("distrib",false);
sreq.params.set("getVersions",nUpdates);
shardHandler.submit(sreq, replica, sreq.params);
}
- 获取本分片最新的nupdate个version(默认是100个),并对这些version进行排序。
recentUpdates = ulog.getRecentUpdates();
try {
ourUpdates = recentUpdates.getVersions(nUpdates);
} finally {
recentUpdates.close();
} Collections.sort(ourUpdates, absComparator);
- 获取recovery之前的version信息startingversions。通过比较startingversions与ourUpdates可以来比较recovery期间是否有索引更新。
- 检查ourUpdates和startingversions是否有交集,由于ourUpdates和startingversions的version个数是限制为nUpdates的,也就是判断索引更新的个数是否大于nUpdate。如果需要更新的索引太多即ourUpdates和startingversions无交集,则进入Replication。
// now make sure that the starting updates overlap our updates
// there shouldn't be reorders, so any overlap will do. long smallestNewUpdate = Math.abs(ourUpdates.get(ourUpdates.size()-1)); if (Math.abs(startingVersions.get(0)) < smallestNewUpdate) {
log.warn(msg() + "too many updates received since start - startingUpdates no longer overlaps with our currentUpdates");
return false;
}
- 如果ourUpdates和startingversions有交集,则合并两个列表,即求并集。
// let's merge the lists
List<Long> newList = new ArrayList<>(ourUpdates);
for (Long ver : startingVersions) {
if (Math.abs(ver) < smallestNewUpdate) {
newList.add(ver);
}
} ourUpdates = newList;
- 本分片的version比别的分片低,则进入Replication策略。这里进行分片version的比较,并没有按version的最大或者最小值,而是比较0.8和0.2比例处的version。
long otherHigh = percentile(otherVersions, .2f);
long otherLow = percentile(otherVersions, .8f); if (ourHighThreshold < otherLow) {
// Small overlap between version windows and ours is older
// This means that we might miss updates if we attempted to use this method.
// Since there exists just one replica that is so much newer, we must
// fail the sync.
log.info(msg() + " Our versions are too old. ourHighThreshold="+ourHighThreshold + " otherLowThreshold="+otherLow);
return false;
}
- 如果本分片的version比其他分片高,则说明不需要进行recovery直接退出peersync。
if (ourLowThreshold > otherHigh) {
// Small overlap between windows and ours is newer.
// Using this list to sync would result in requesting/replaying results we don't need
// and possibly bringing deleted docs back to life.
log.info(msg() + " Our versions are newer. ourLowThreshold="+ourLowThreshold + " otherHigh="+otherHigh);
return true;
}
- 对本分片的version和其他分片的version求差,获取本分片缺少的version。
for (Long otherVersion : otherVersions) {
// stop when the entries get old enough that reorders may lead us to see updates we don't need
if (!completeList && Math.abs(otherVersion) < ourLowThreshold) break;
if (ourUpdateSet.contains(otherVersion) || requestedUpdateSet.contains(otherVersion)) {
// we either have this update, or already requested it
// TODO: what if the shard we previously requested this from returns failure (because it goes
// down)
continue;
}
toRequest.add(otherVersion);
requestedUpdateSet.add(otherVersion);
}
- 最后向其他分片发送getupdate命令,根据处理后的version获取相应的document,至此完成peersync过程
private boolean requestUpdates(ShardResponse srsp, List<Long> toRequest) {
String replica = srsp.getShardRequest().shards[0];
log.info(msg() + "Requesting updates from " + replica + "n=" + toRequest.size() + " versions=" + toRequest);
// reuse our original request object
ShardRequest sreq = srsp.getShardRequest();
sreq.purpose = 0;
sreq.params = new ModifiableSolrParams();
sreq.params.set("qt", "/get");
sreq.params.set("distrib", false);
sreq.params.set("getUpdates", StrUtils.join(toRequest, ','));
sreq.params.set("onlyIfActive", onlyIfActive);
sreq.responses.clear(); // needs to be zeroed for correct correlation to occur
shardHandler.submit(sreq, sreq.shards[0], sreq.params);
return true;
}
总结:
本文具体介绍PeerSync的过程,由此可见PeerSync策略的recovery过程还是比较简单的,下一节将具体介绍Replication策略,这个较PeerSync复杂。
Solr4.8.0源码分析(21)之SolrCloud的Recovery策略(二)的更多相关文章
- Solr4.8.0源码分析(24)之SolrCloud的Recovery策略(五)
Solr4.8.0源码分析(24)之SolrCloud的Recovery策略(五) 题记:关于SolrCloud的Recovery策略已经写了四篇了,这篇应该是系统介绍Recovery策略的最后一篇了 ...
- Solr4.8.0源码分析(23)之SolrCloud的Recovery策略(四)
Solr4.8.0源码分析(23)之SolrCloud的Recovery策略(四) 题记:本来计划的SolrCloud的Recovery策略的文章是3篇的,但是没想到Recovery的内容蛮多的,前面 ...
- Solr4.8.0源码分析(22)之SolrCloud的Recovery策略(三)
Solr4.8.0源码分析(22)之SolrCloud的Recovery策略(三) 本文是SolrCloud的Recovery策略系列的第三篇文章,前面两篇主要介绍了Recovery的总体流程,以及P ...
- Solr4.8.0源码分析(20)之SolrCloud的Recovery策略(一)
Solr4.8.0源码分析(20)之SolrCloud的Recovery策略(一) 题记: 我们在使用SolrCloud中会经常发现会有备份的shard出现状态Recoverying,这就表明Solr ...
- Solr4.8.0源码分析(25)之SolrCloud的Split流程
Solr4.8.0源码分析(25)之SolrCloud的Split流程(一) 题记:昨天有位网友问我SolrCloud的split的机制是如何的,这个还真不知道,所以今天抽空去看了Split的原理,大 ...
- Solr4.8.0源码分析(14)之SolrCloud索引深入(1)
Solr4.8.0源码分析(14) 之 SolrCloud索引深入(1) 上一章节<Solr In Action 笔记(4) 之 SolrCloud分布式索引基础>简要学习了SolrClo ...
- Solr4.8.0源码分析(15) 之 SolrCloud索引深入(2)
Solr4.8.0源码分析(15) 之 SolrCloud索引深入(2) 上一节主要介绍了SolrCloud分布式索引的整体流程图以及索引链的实现,那么本节开始将分别介绍三个索引过程即LogUpdat ...
- Solr4.8.0源码分析(17)之SolrCloud索引深入(4)
Solr4.8.0源码分析(17)之SolrCloud索引深入(4) 前面几节以add为例已经介绍了solrcloud索引链建索引的三步过程,delete以及deletebyquery跟add过程大同 ...
- Solr4.8.0源码分析(16)之SolrCloud索引深入(3)
Solr4.8.0源码分析(16)之SolrCloud索引深入(3) 前面两节学习了SolrCloud索引过程以及索引链的前两步,LogUpdateProcessorFactory和Distribut ...
随机推荐
- appium api
AppiumDriver getAppStrings() 默认系统语言对应的Strings.xml文件内的数据.iOS driver.getAppStrings(Stringlanguage ...
- C# Timer执行方法
private void button3_Click(object sender, EventArgs e) { System.Timers.Timer t = new System.Timers.T ...
- Unity UGUI——Rect Transform组件(基础属性)
基础属性:Width.Height.Pivot图示 watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvTXJfQUhhbw==/font/5a6L5L2T/fo ...
- SwipeListView 具体解释 实现微信,QQ等滑动删除效果
转载请标明出处:http://blog.csdn.net/lmj623565791/article/details/28508769 今天看别人项目,看到别人使用了SwipeListView,Goog ...
- history对象back()、forward()、go()
history对象back().forward().go()方法history.back() 功能:加载历史列表中的前一个URL(后退). 语法:history.back() 调用该方法的效果等价于点 ...
- 独立博客怎样申请谷歌Adsense
谷歌Adsense广告是眼下个人站长的主要赚钱途径之中的一个,首先是它相对诱人的单位价格,尽管谷歌中文广告相比英文广告单位价格有所折扣,但我的经验是仅仅要你的网页内容和广告keyword有较高的匹配性 ...
- hdu 4622 Reincarnation(后缀数组)
hdu 4622 Reincarnation 题意:还是比较容易理解,给出一个字符串,最长2000,q个询问,每次询问[l,r]区间内有多少个不同的字串. (为了与论文解释统一,这里解题思路里sa数组 ...
- Android内存优化之——static使用篇(使用MAT工具进行分析)
这篇文章主要配套与Android内存优化之——static使用篇向大家介绍MAT工具的使用,我们分析的内存泄漏程序是上一篇文章中static的使用内存泄漏的比较不容易发现泄漏的第二情况和第三种情况—— ...
- Restart-ServiceEx.psm1
详细描述 利用WMI的Win32_Service类重启指定计算机上的服务. Restart-ServiceEx cmdlet 通过WMI的Win32_Service类向指定计算机(ComputerNa ...
- CentOS 6.7编译安装MySQL 5.6
1.安装前准备 yum install make gcc gcc-c++ ncurses-devel perl bison-devel yum groupinstall "Developme ...