python 爬虫入门----案例爬取上海租房图片
前言
对于一个net开发这爬虫真真的以前没有写过。这段时间学习python爬虫,今天周末无聊写了一段代码爬取上海租房图片,其实很简短就是利用爬虫的第三方库Requests与BeautifulSoup。python 版本:python3.6 ,IDE :pycharm。其实就几行代码,但希望没有开发基础的人也能一下子看明白,所以大神请绕行。
第三方库
首先安装
我是用的pycharm所以另为的脚本安装我这就不介绍了。
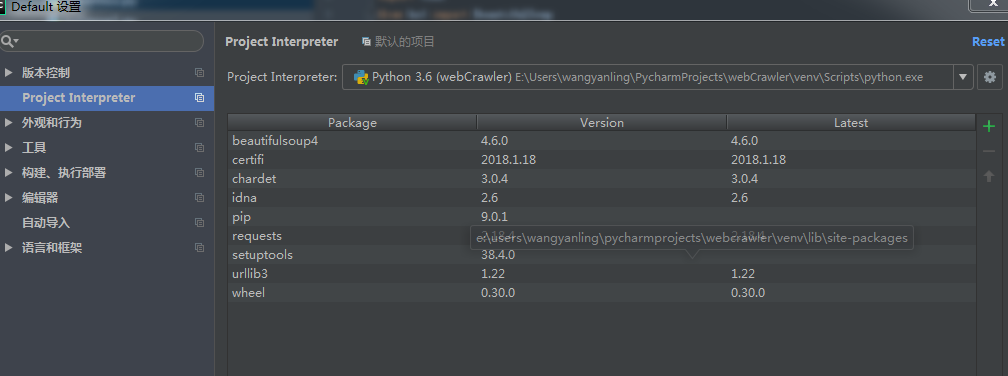
如上图打开默认设置选择Project Interprecter,双击pip或者点击加号,搜索要安装的第三方库。其中如果建立的项目多记得Project Interprecter要选择正确的安装位置不然无法导入。
Requests库
requests库的官方定义:Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用。其实他就是请求网络获取网页数据的。
import requests
header={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
res=requests.get('http://sh.58.com/zufang/',headers=header)
try:
print(res.text);
except ConnectionError:
print('访问被拒绝!!!')
结果如下:

其中Request Headers的参数如下:
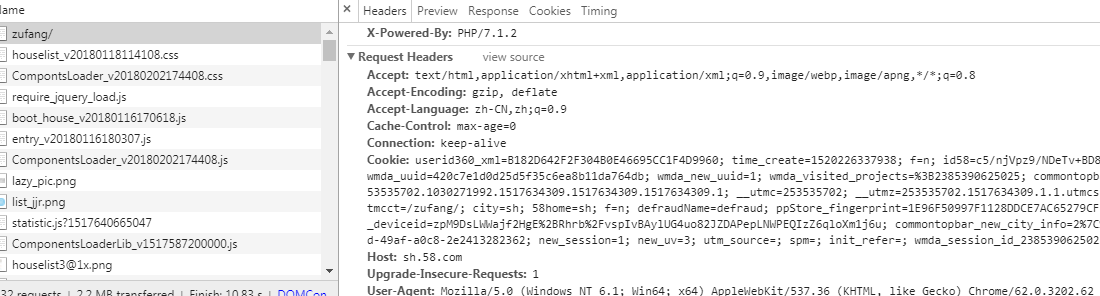
#headers的一些属性: #Accept:指定客户端能够接收的内容类型,内容类型的先后次序表示客户都接收的先后次序 #Accept-Lanuage:指定HTTP客户端浏览器用来展示返回信息优先选择的语言 #Accept-Encoding指定客户端浏览器可以支持的web服务器返回内容压缩编码类型。表示允许服务器在将输出内容发送到客户端以前进行压缩,以节约带宽。而这里设置的就是客户端浏览器所能够支持的返回压缩格式。 #Accept-Charset:HTTP客户端浏览器可以接受的字符编码集 # User-Agent : 有些服务器或 Proxy 会通过该值来判断是否是浏览器发出的请求 # Content-Type : 在使用 REST 接口时,服务器会检查该值,用来确定 HTTP Body 中的内容该怎样解析。 # application/xml : 在 XML RPC,如 RESTful/SOAP 调用时使用 # application/json : 在 JSON RPC 调用时使用 # application/x-www-form-urlencoded : 浏览器提交 Web 表单时使用 # 在使用服务器提供的 RESTful 或 SOAP 服务时, Content-Type 设置错误会导致服务器拒绝服务
BeautifulSoup库
BeautifulSoup可以轻松的解析Requests库请求的页面,并把页面源代码解析为Soup文档,一边过滤提取数据。这是bs4.2的文档。
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它,则 Python 会使用 Python默认的解析器,其中lxml 据说是相对而言比较强大的我下面的暗示是python 标准库的。
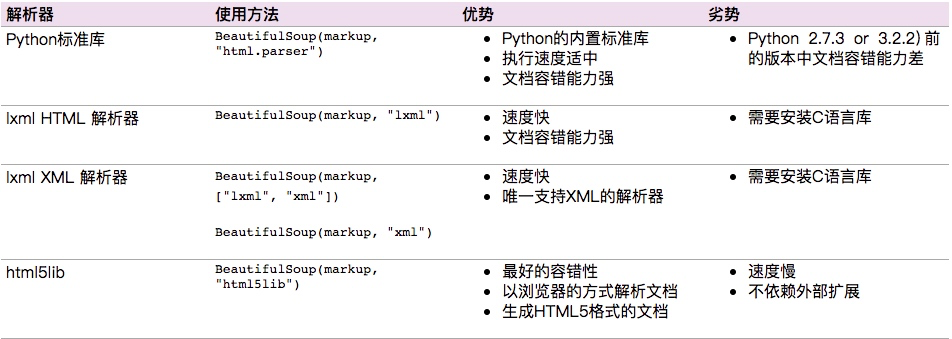
选择器select
# 选择所有div标签
soup.select("div")
# 选择所有p标签中的第三个标签
soup.select("p:nth-of-type(3)")
相当于soup.select(p)[2]
# 选择div标签下的所有img标签
soup.select("div img")
# 选择div标签下的直接a子标签
soup.select("div > a")
# 选择id=link1后的所有兄弟节点标签
soup.select("#link1 ~ .mybro")
# 选择id=link1后的下一个兄弟节点标签
soup.select("#link1 + .mybro")
# 选择a标签,其类属性为className的标签
soup.select("a .className")
# 选择a标签,其id属性为idName的标签
soup.select("a #idName")
# 选择a标签,其属性中存在attrName的所有标签
soup.select("a[attrName]")
# 选择a标签,其属性href=http://wangyanling.com的所有标签
soup.select("a[href='http://wangyanling.com']")
# 选择a标签,其href属性以http开头
soup.select('a[href^="http"]')
# 选择a标签,其href属性以lacie结尾
soup.select('a[href$="lacie"]')
# 选择a标签,其href属性包含.com
soup.select('a[href*=".com"]')
# 从html中排除某标签,此时soup中不再有script标签
[s.extract() for s in soup('script')]
# 如果想排除多个呢
[s.extract() for s in soup(['script','fram']
BeautifulSoup库需要学习的知识点,请参考bs4.2的文档。在这不再过多叙述。
import requests
from bs4 import BeautifulSoup
header={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
res=requests.get('http://cd.58.com/zufang/',headers=header)
soup=BeautifulSoup(res.text,'html.parser')
print(soup.prettify())
案例:爬取上海租房图片
import requests
import urllib.request
import os
import time
from bs4 import BeautifulSoup
header={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36'}
url=['http://sh.58.com/zufang/pn{}/?ClickID=2'.format(number) for number in range(1,5)]#分页抓取
adminCout=0
for arurl in url:
adminCout=adminCout+1
time.sleep(5)
res=requests.get(arurl,headers=header)
soup=BeautifulSoup(res.text,'html.parser')
arryImg=soup.select('.img_list img')
print(arryImg)
count = 0;
for img in arryImg:
print(img['lazy_src'])
_url = img['lazy_src']
pathName = "E:\\wyl\\" + str(adminCout)+"_"+str(count) + ".jpg" # 设置路径和文件名
result = urllib.request.urlopen(_url) # 打开链接,和python2.x不同请注意了
data = result.read() # 否则开始下载到本地
with open(pathName, "wb") as code:
code.write(data)
code.close()
count = count + 1 # 计数+1
print("正在下载第:", count)
只是实现功能,至于代码结果如下:

结语:
对于python并非为了从net跳出来,学习python只是感兴趣,但是通过这段时间的学习确实有些思想从net的思路中跳了出来,接下来一年的业余时间应该都会花在学习python上,还希望自己能坚持下去。这应该是2018最后一篇文章,在这给大家拜个早年。
python 爬虫入门----案例爬取上海租房图片的更多相关文章
- python 爬虫入门案例----爬取某站上海租房图片
前言 对于一个net开发这爬虫真真的以前没有写过.这段时间开始学习python爬虫,今天周末无聊写了一段代码爬取上海租房图片,其实很简短就是利用爬虫的第三方库Requests与BeautifulSou ...
- Python 爬虫入门之爬取妹子图
Python 爬虫入门之爬取妹子图 来源:李英杰 链接: https://segmentfault.com/a/1190000015798452 听说你写代码没动力?本文就给你动力,爬取妹子图.如果 ...
- Python 爬虫入门(二)——爬取妹子图
Python 爬虫入门 听说你写代码没动力?本文就给你动力,爬取妹子图.如果这也没动力那就没救了. GitHub 地址: https://github.com/injetlee/Python/blob ...
- Python 爬虫入门(一)——爬取糗百
爬取糗百内容 GitHub 代码地址https://github.com/injetlee/Python/blob/master/qiubai_crawer.py 微信公众号:[智能制造专栏],欢迎关 ...
- Python爬虫入门:爬取豆瓣电影TOP250
一个很简单的爬虫. 从这里学习的,解释的挺好的:https://xlzd.me/2015/12/16/python-crawler-03 分享写这个代码用到了的学习的链接: BeautifulSoup ...
- [python爬虫] Selenium定向爬取海量精美图片及搜索引擎杂谈
我自认为这是自己写过博客中一篇比较优秀的文章,同时也是在深夜凌晨2点满怀着激情和愉悦之心完成的.首先通过这篇文章,你能学到以下几点: 1.可以了解Python简单爬取图片的一些思路和方法 ...
- Python爬虫入门:爬取pixiv
终于想开始爬自己想爬的网站了.于是就试着爬P站试试手. 我爬的图的目标网址是: http://www.pixiv.net/search.php?word=%E5%9B%9B%E6%9C%88%E3%8 ...
- python 爬虫入门1 爬取代理服务器网址
刚学,只会一点正则,还只能爬1页..以后还会加入测试 #coding:utf-8 import urllib import urllib2 import re #抓取代理服务器地址 Key = 1 u ...
- python - 爬虫入门练习 爬取链家网二手房信息
import requests from bs4 import BeautifulSoup import sqlite3 conn = sqlite3.connect("test.db&qu ...
随机推荐
- js 跨域问题 汇总
前言 相信每一个前端er对于跨域这两个字都不会陌生,在实际项目中应用也是比较多的.但跨域方法的多种多样实在让人目不暇接.老规矩,碰到这种情况,就只能自己总结一篇博客,作为记录. 正文 1. 什么是跨域 ...
- 支付宝pc网页支付
本文讲解如何在pc网页上完成支付宝的支付功能, 详细讲解了支付宝的配置信息,项目如何使用配置信息等, 本项目中代码可以直接运行, 也可以将代码迁移至你自己的项目中直接使用. 注意: 下面讲解的功能只能 ...
- EXP导出aud$报错EXP-00008,ORA-00904 解决
主题:EXP导出aud$报错EXP-00008,ORA-00904 解决 环境:Oracle 11.2.0.4 问题:在自己的测试环境,导出sys用户下的aud$表报错. 1.故障现场 2.跟踪处理 ...
- spring使用之旅(一) ---- bean的装配
基础配置 启用组件扫描配置 Java类配置文件方式 package com.springapp.mvc.application; import ...
- beef配合ettercap批量劫持内网的浏览器
先更改首先先打开ettercap的DNS文件进行编辑,在kali linux2.0下的文件路径为/etc/ettercap/etter.dns 在对应的位置添加对应的 标识和IP地址 * 代表所有域名 ...
- Phabricator API Go 创建task/提交文件到Phabricator
Go Phabricator API 代码/程序创建task/提交文件到Phabricator Creat Task or upload file to phabricator with code i ...
- 学习笔记-echarts点击数据添加跳转链接
原链接:http://echarts.baidu.com/demo.html#pie-rich-text 这个一段官方提供的实例. var weatherIcons = { 'Sunny': './d ...
- Java面向对象接口的应用实例练习
interface USB { public void open(); public void close(); } class Upan implements USB { public void o ...
- [bzoj2594][Wc2006]水管局长数据加强版 (lct)
论蒟蒻的自我修养T_T.. 和noi2014魔法森林基本一样...然而数据范围大得sxbk...UPD:这题如果用lct判联通的话可能会被卡到O(mlogm)..所以最好还是用并查集吧 一开始数组开太 ...
- UESTC1599-wtmsb-优先队列
wtmsb Time Limit: 1000/100MS (Java/Others) Memory Limit: 131072/131072KB (Java/Others) 这天,AutSky_Jad ...