毕业论文着急了?Python疫情数据分析,并做数据可视化展示
采集流程
一.、明确需求
采集/确诊人数/新增人数
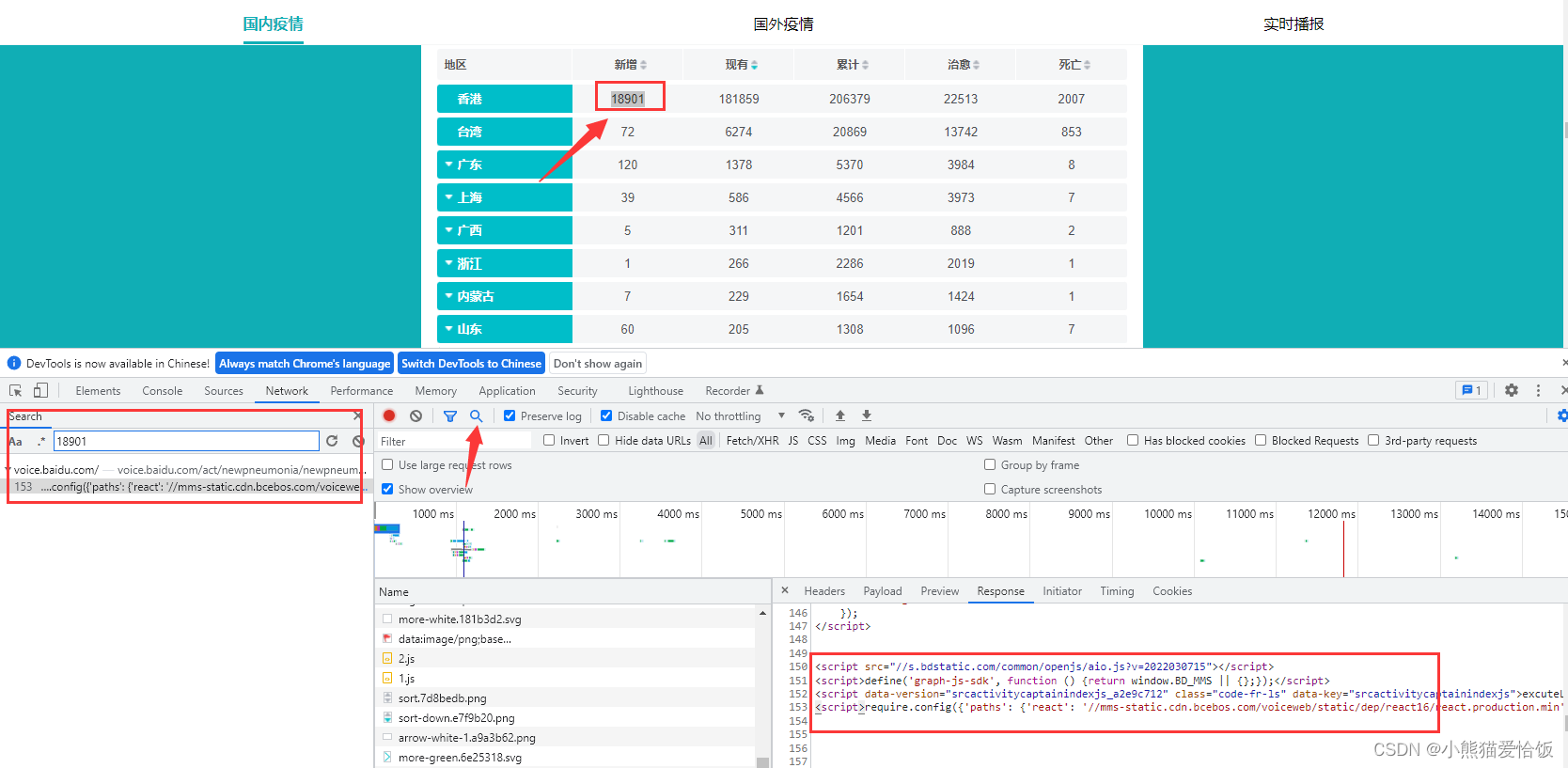
二、代码流程 四大步骤
- 发送请求
- 获取数据 网页源代码
- 解析数据 筛选一些我想用的数据
- 保存数据 保存成表格
- 做数据可视化分析
开始代码
1. 发送请求
import requests # 额外安装: 第三方模块
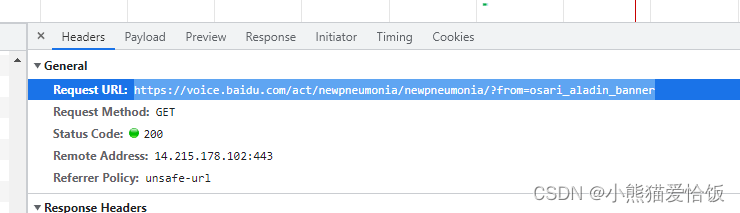
url = 'https://voice.baidu.com/act/newpneumonia/newpneumonia/?from=osari_aladin_banner'
response = requests.get(url)
2. 获取数据 网页源代码
html_data = response.text
# print(response.text)
3. 解析数据
最烦的事情来了,就是提取里面的数据
str_data = re.findall('<script type="application\/json" id="captain-config">\{(.*)\}',html_data)[0]
print(re.findall( '"component":\[(.*)\],',str_data)[0])


用工具去解析一下,在caseList里面就是我们想要的数据了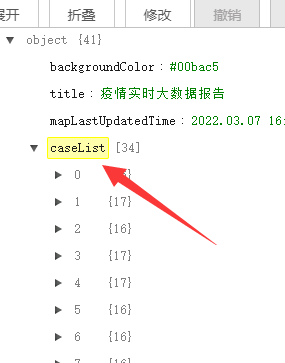

json_str = re.findall('"component":\[(.*)\],', html_data)[0] # 字符串
# 字典类型取值, 转类型
json_dict = eval(json_str)
caseList = json_dict['caseList']
for case in caseList:
area = case['area'] # 城市
curConfirm = case['curConfirm'] # 当前确诊
curConfirmRelative = case['curConfirmRelative'] # 新增人数
confirmed = case['confirmed'] # 累计确诊
crued = case['crued'] # 治愈人数
died = case['died'] # 死亡人数
4. 保存数据
with open('data.csv', mode='a', newline='') as f:
csv_writer = csv.writer(f)
csv_writer.writerow([area, curConfirm, curConfirmRelative, confirmed, crued, died])
运行代码,得到数据
疫情数据可视化
完整源码+数据集
各地区确诊人数
china_map = (
Map()
.add("现有确诊", [list(i) for i in zip(df['area'].values.tolist(),df['curConfirm'].values.tolist())], "china")
.set_global_opts(
title_opts=opts.TitleOpts(title="各地区确诊人数"),
visualmap_opts=opts.VisualMapOpts(max_=200, is_piecewise=True),
)
)
china_map.render_notebook()
新型冠状病毒全国疫情地图
cofirm, currentCofirm, cured, dead = [], [], [], []
tab = Tab()
_map = (
Map(init_opts=opts.InitOpts(theme='dark', width='1000px'))
.add("累计确诊人数", [list(i) for i in zip(df['area'].values.tolist(),df['confirmed'].values.tolist())], "china", is_map_symbol_show=False, is_roam=False)
.set_series_opts(label_opts=opts.LabelOpts(is_show=True))
.set_global_opts(
title_opts=opts.TitleOpts(title="新型冠状病毒全国疫情地图",
),
legend_opts=opts.LegendOpts(is_show=False),
visualmap_opts=opts.VisualMapOpts(is_show=True, max_=1000,
is_piecewise=False,
range_color=['#FFFFE0', '#FFA07A', '#CD5C5C', '#8B0000'])
)
)
tab.add(_map, '累计确诊')
_map = (
Map(init_opts=opts.InitOpts(theme='dark', width='1000px'))
.add("当前确诊人数", [list(i) for i in zip(df['area'].values.tolist(),df['curConfirm'].values.tolist())], "china", is_map_symbol_show=False, is_roam=False)
.set_series_opts(label_opts=opts.LabelOpts(is_show=True))
.set_global_opts(
title_opts=opts.TitleOpts(title="新型冠状病毒全国疫情地图",
),
legend_opts=opts.LegendOpts(is_show=False),
visualmap_opts=opts.VisualMapOpts(is_show=True, max_=100,
is_piecewise=False,
range_color=['#FFFFE0', '#FFA07A', '#CD5C5C', '#8B0000'])
)
)
tab.add(_map, '当前确诊')
_map = (
Map(init_opts=opts.InitOpts(theme='dark', width='1000px'))
.add("治愈人数", [list(i) for i in zip(df['area'].values.tolist(),df['crued'].values.tolist())], "china", is_map_symbol_show=False, is_roam=False)
.set_series_opts(label_opts=opts.LabelOpts(is_show=True))
.set_global_opts(
title_opts=opts.TitleOpts(title="新型冠状病毒全国疫情地图",
),
legend_opts=opts.LegendOpts(is_show=False),
visualmap_opts=opts.VisualMapOpts(is_show=True, max_=1000,
is_piecewise=False,
range_color=['#FFFFE0', 'green'])
)
)
tab.add(_map, '治愈')
_map = (
Map(init_opts=opts.InitOpts(theme='dark', width='1000px'))
.add("死亡人数", [list(i) for i in zip(df['area'].values.tolist(),df['died'].values.tolist())], "china", is_map_symbol_show=False, is_roam=False)
.set_series_opts(label_opts=opts.LabelOpts(is_show=True))
.set_global_opts(
title_opts=opts.TitleOpts(title="新型冠状病毒全国疫情地图",
),
legend_opts=opts.LegendOpts(is_show=False),
visualmap_opts=opts.VisualMapOpts(is_show=True, max_=50,
is_piecewise=False,
range_color=['#FFFFE0', '#FFA07A', '#CD5C5C', '#8B0000'])
)
)
tab.add(_map, '死亡')
tab.render_notebook()
各地区确诊人数与死亡人数情况
\bar = (
Bar()
.add_xaxis(list(df['area'].values)[:6])
.add_yaxis("死亡", df['died'].values.tolist()[:6])
.add_yaxis("治愈", df['crued'].values.tolist()[:6])
.set_global_opts(
title_opts=opts.TitleOpts(title="各地区确诊人数与死亡人数情况"),
datazoom_opts=[opts.DataZoomOpts()],
)
)
bar.render_notebook()
## 采集流程
## **一.、明确需求**
> 采集/确诊人数/新增人数> 

## 二、代码流程 四大步骤
1. 发送请求2. 获取数据 网页源代码3. 解析数据 筛选一些我想用的数据4. 保存数据 保存成表格5. 做数据可视化分析
## 开始代码**1. 发送请求**~~~import requests # 额外安装: 第三方模块
url = 'https://voice.baidu.com/act/newpneumonia/newpneumonia/?from=osari_aladin_banner'response = requests.get(url)~~~**2. 获取数据 网页源代码**~~~html_data = response.text# print(response.text)~~~**3. 解析数据**最烦的事情来了,就是提取里面的数据~~~str_data = re.findall('<script type="application\/json" id="captain-config">\{(.*)\}',html_data)[0]print(re.findall( '"component":\[(.*)\],',str_data)[0])~~~用工具去解析一下,在caseList里面就是我们想要的数据了~~~json_str = re.findall('"component":\[(.*)\],', html_data)[0] # 字符串# 字典类型取值, 转类型json_dict = eval(json_str)caseList = json_dict['caseList']for case in caseList: area = case['area'] # 城市 curConfirm = case['curConfirm'] # 当前确诊 curConfirmRelative = case['curConfirmRelative'] # 新增人数 confirmed = case['confirmed'] # 累计确诊 crued = case['crued'] # 治愈人数 died = case['died'] # 死亡人数~~~**4. 保存数据**~~~with open('data.csv', mode='a', newline='') as f: csv_writer = csv.writer(f) csv_writer.writerow([area, curConfirm, curConfirmRelative, confirmed, crued, died])~~~**运行代码,得到数据**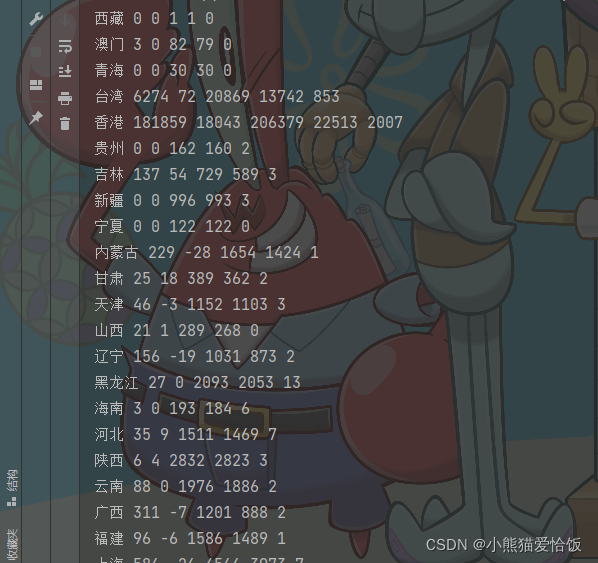
## 疫情数据可视化[完整源码+数据集](https://jq.qq.com/?_wv=1027&k=H7fKJd2B)**各地区确诊人数**~~~china_map = ( Map() .add("现有确诊", [list(i) for i in zip(df['area'].values.tolist(),df['curConfirm'].values.tolist())], "china") .set_global_opts( title_opts=opts.TitleOpts(title="各地区确诊人数"), visualmap_opts=opts.VisualMapOpts(max_=200, is_piecewise=True), ))china_map.render_notebook()~~~**新型冠状病毒全国疫情地图**~~~cofirm, currentCofirm, cured, dead = [], [], [], []
tab = Tab()
_map = ( Map(init_opts=opts.InitOpts(theme='dark', width='1000px')) .add("累计确诊人数", [list(i) for i in zip(df['area'].values.tolist(),df['confirmed'].values.tolist())], "china", is_map_symbol_show=False, is_roam=False) .set_series_opts(label_opts=opts.LabelOpts(is_show=True)) .set_global_opts( title_opts=opts.TitleOpts(title="新型冠状病毒全国疫情地图", ), legend_opts=opts.LegendOpts(is_show=False), visualmap_opts=opts.VisualMapOpts(is_show=True, max_=1000, is_piecewise=False, range_color=['#FFFFE0', '#FFA07A', '#CD5C5C', '#8B0000']) ))tab.add(_map, '累计确诊')
_map = ( Map(init_opts=opts.InitOpts(theme='dark', width='1000px')) .add("当前确诊人数", [list(i) for i in zip(df['area'].values.tolist(),df['curConfirm'].values.tolist())], "china", is_map_symbol_show=False, is_roam=False) .set_series_opts(label_opts=opts.LabelOpts(is_show=True)) .set_global_opts( title_opts=opts.TitleOpts(title="新型冠状病毒全国疫情地图", ), legend_opts=opts.LegendOpts(is_show=False), visualmap_opts=opts.VisualMapOpts(is_show=True, max_=100, is_piecewise=False, range_color=['#FFFFE0', '#FFA07A', '#CD5C5C', '#8B0000']) ))tab.add(_map, '当前确诊')
_map = ( Map(init_opts=opts.InitOpts(theme='dark', width='1000px')) .add("治愈人数", [list(i) for i in zip(df['area'].values.tolist(),df['crued'].values.tolist())], "china", is_map_symbol_show=False, is_roam=False) .set_series_opts(label_opts=opts.LabelOpts(is_show=True)) .set_global_opts( title_opts=opts.TitleOpts(title="新型冠状病毒全国疫情地图", ), legend_opts=opts.LegendOpts(is_show=False), visualmap_opts=opts.VisualMapOpts(is_show=True, max_=1000, is_piecewise=False, range_color=['#FFFFE0', 'green']) ))tab.add(_map, '治愈')
_map = ( Map(init_opts=opts.InitOpts(theme='dark', width='1000px')) .add("死亡人数", [list(i) for i in zip(df['area'].values.tolist(),df['died'].values.tolist())], "china", is_map_symbol_show=False, is_roam=False) .set_series_opts(label_opts=opts.LabelOpts(is_show=True)) .set_global_opts( title_opts=opts.TitleOpts(title="新型冠状病毒全国疫情地图", ), legend_opts=opts.LegendOpts(is_show=False), visualmap_opts=opts.VisualMapOpts(is_show=True, max_=50, is_piecewise=False, range_color=['#FFFFE0', '#FFA07A', '#CD5C5C', '#8B0000']) ))tab.add(_map, '死亡')
tab.render_notebook()~~~**各地区确诊人数与死亡人数情况**~~~\bar = ( Bar() .add_xaxis(list(df['area'].values)[:6]) .add_yaxis("死亡", df['died'].values.tolist()[:6]) .add_yaxis("治愈", df['crued'].values.tolist()[:6]) .set_global_opts( title_opts=opts.TitleOpts(title="各地区确诊人数与死亡人数情况"), datazoom_opts=[opts.DataZoomOpts()], ))bar.render_notebook()~~~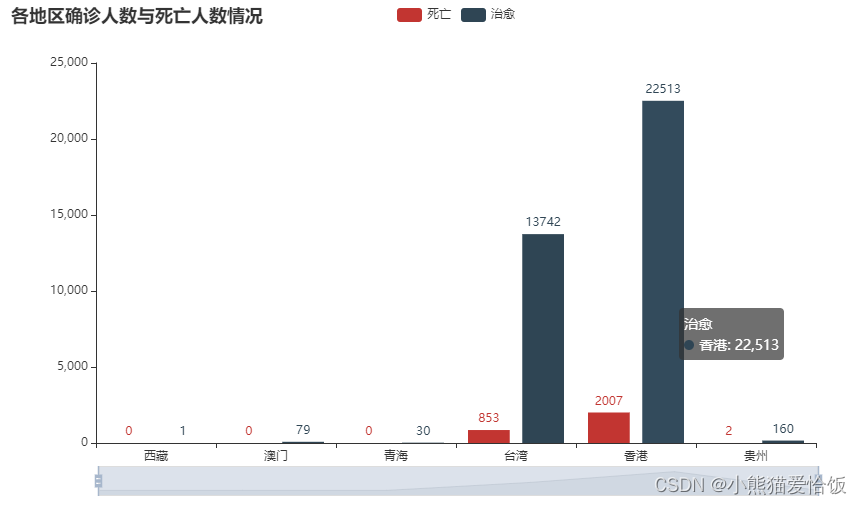
毕业论文着急了?Python疫情数据分析,并做数据可视化展示的更多相关文章
- Python调用matplotlib实现交互式数据可视化图表案例
交互式的数据可视化图表是 New IT 新技术的一个应用方向,在过去,用户要在网页上查看数据,基本的实现方式就是在页面上显示一个表格出来,的而且确,用表格的方式来展示数据,显示的数据量会比较大,但是, ...
- BI工具做数据可视化项目频频失败的原因
现如今数据可视化可谓是非常之火,随着硬件价格的一降再降,仿佛做数据可视化项目,你没有数据大屏,你就没有逼格.理想很丰满,现实很骨感,并不是每一个数据可视化项目都能够成功.数据可视化项目的进行,无外乎是 ...
- 为什么有些BI工具做数据可视化项目频频失败?
现如今数据可视化可谓是非常之火,随着硬件价格的一降再降,仿佛做数据可视化项目,你没有数据大屏,你就没有逼格.理想很丰满,现实很骨感,并不是每一个数据可视化项目都能够成功.数据可视化项目的进行,无外乎是 ...
- 手把手教你用FineBI做数据可视化
前些日子公司引进了帆软商业智能FineBI,在接受了简单的培训后,发现这款商业智能软件用作可视分析只用一个词形容的话,那就是“轻盈灵动”!界面简洁.操作流畅,几个步骤就可以创建分析,获得想要的效果.此 ...
- python实现的电影票房数据可视化
代码地址如下:http://www.demodashi.com/demo/14275.html 详细说明: Tushare是一个免费.开源的python财经数据接口包.主要实现对股票等金融数据从数据采 ...
- 2021年都要过去啦,你还在用Excel做数据可视化效果吗?
2021年都要过去啦,你还在用Excel做数据可视化效果吗?古语有云,"工欲善其事,必先利其器",没有专业的工具,前期准备的再好也是白搭.现在运用数据可视化工具于经营活动中的企业是 ...
- 利用python进行数据分析之绘图和可视化
matplotlib API入门 使用matplotlib的办法最常用的方式是pylab的ipython,pylab模式还会向ipython引入一大堆模块和函数提供一种更接近与matlab的界面,ma ...
- 学机器学习,不会数据分析怎么行——数据可视化分析(matplotlib)
前言 前面两篇文章介绍了 python 中两大模块 pandas 和 numpy 的一些基本使用方法,然而,仅仅会处理数据还是不够的,我们需要学会怎么分析,毫无疑问,利用图表对数据进行分析是最容易的, ...
- Python的Excel操作及数据可视化
Excel表操作 python操作excel主要用到xlrd和xlwt这两个库,即xlrd是读excel,xlwt是写excel的库. 安装xlrd pip install xlrd 简单的表格读取 ...
随机推荐
- 进阶版css点击按钮动画
1. html <div class="menu-wrap"> <input type="checkbox" class="togg ...
- svelte组件:svelte3自定义桌面PC端对话框组件svelte-layer
基于Svelte3.x开发pc网页版自定义弹窗组件svelteLayer. svelte-layer:基于svelte.js轻量级多功能pc桌面端对话框组件.支持多种弹窗类型.30+参数随意组合配置, ...
- Go语言 时间函数
@ 目录 引言 1. 时间格式化 2. 示例 引言 1946年2月14日,人类历史上公认的第一台现代电子计算机"埃尼阿克"(ENIAC)诞生. 计算机语言时间戳是以1970年1月1 ...
- 聊聊buffer和cache的区别以及是什么?
buffer 众所周知,想把数据写入磁盘,肯定要先把数据文件读到内存中,当修改完这个文件时,不会立即写入磁盘,为了减少磁盘IO,提高性能,所有会留存一段时间再写入磁盘,这就是buffer cache ...
- c# 一些警告的处理方法
在使用.Net 6开发程序时,发现多了很多新的警告类型.这里总结一下处理方法. CS8618 在退出构造函数时,不可为 null 的 属性"Name"必须包含非 null 值 经常 ...
- [AcWing 51] 数字排列
点击查看代码 class Solution { public: vector<vector<int>> res; vector<vector<int>> ...
- 使用fastai训练的一个性别识别模型
在学习了python中的一些机器学习的相关模块后,再一次开始了深度学习之旅.不过与上次的TensorFlow框架不同,这一次接触的是fast.ai这样一个东西.这个框架还不稳定,网上也没有相关的中文文 ...
- 浅谈 UNIX、Linux、ios、android 他们之间的关系
开源Linux 一个执着于技术的公众号 Unix, 简化形成了Linux,Linux则是Android的内核,而苹果则是使用unix系统作为ios和macos的内核. 几个系统出现的时间 UNIX系统 ...
- Java安全之SnakeYaml反序列化分析
Java安全之SnakeYaml反序列化分析 目录 Java安全之SnakeYaml反序列化分析 写在前面 SnakeYaml简介 SnakeYaml序列化与反序列化 常用方法 序列化 反序列化 Sn ...
- 解读论文《Agglomerative clustering of a search engine query log》,以解决搜索推荐相关问题
<Agglomerative clustering of a search engine query log> 论文作者:Doug Beeferman 本文将解读此篇论文,此论文利用搜索日 ...