python + BeautifulSoup + selenium 实现爬取中医智库的古籍分类的数据
爬取内容为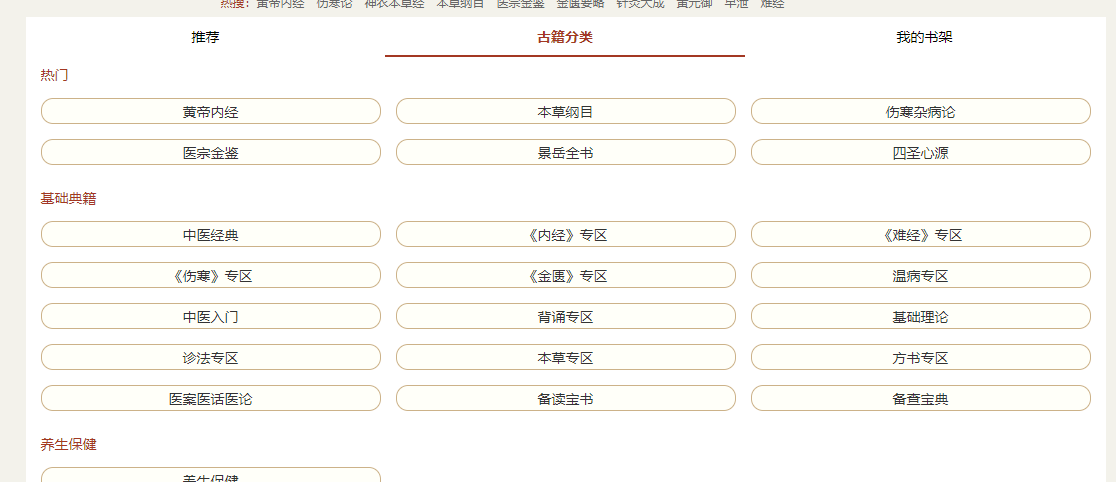
该图片下的七个分类, 然后对应的每个种类的书本信息(摘要和目录)
效果为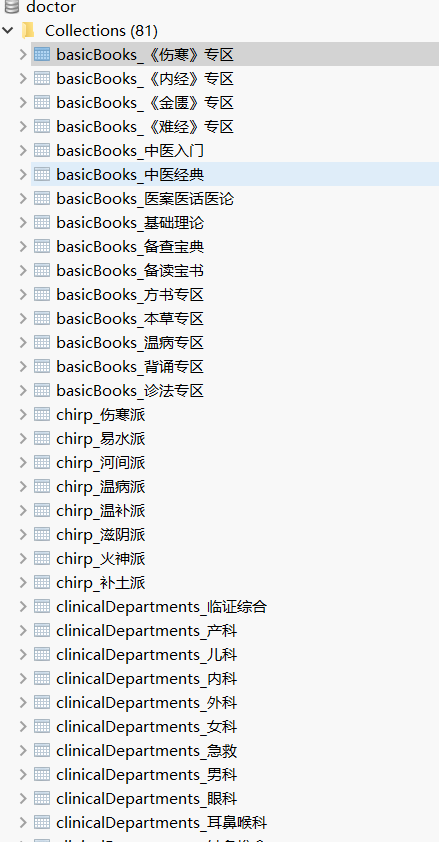
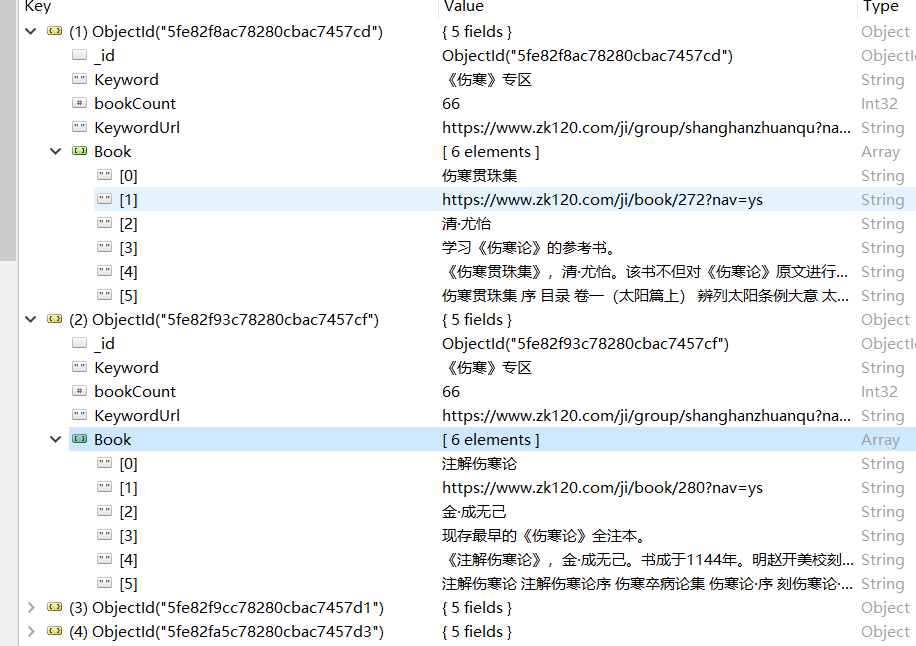
代码如下
import requests
from bs4 import BeautifulSoup
import re
import time
from selenium import webdriver
from selenium.common.exceptions import ElementNotInteractableException, NoSuchElementException
import pymongo
browser = webdriver.Chrome()
browser2 = webdriver.Chrome()
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/80.0.3987.163 Safari/537.36 '
}
# 第一层的七个分类
allMap = {}
# 热门
hotMap = {} # range(0,6)
# 基础典籍
basicBooks = {} # range(6,21)
# 养生保健
health = {} # range(21,22)
# 孤本
orphan = {} # range(22,23)
# 临症各科
clinicalDepartments = {} # range(23, 35) 23 + 12
# 争鸣流派
chirp = {} # range(35, 44) +9
# 历代医家
doctors = {} # range(44, 82) +13*3-1
def toMongoDB(Keyword, name, bookCount, nameUrl, bookName, bookUrl, bookAuthor, bookDescription, digest, catlog):
myClient = pymongo.MongoClient("mongodb://localhost:27017/")
myDb = myClient["doctor"]
myCollection = myDb[str(Keyword) + "_" + str(name)]
myDictionary = {
"Keyword": name,
"bookCount": bookCount,
"KeywordUrl": nameUrl,
"Book": [
bookName, bookUrl, bookAuthor, bookDescription, digest, catlog
]
}
result = myCollection.insert_one(myDictionary)
print(result)
pass
def splitIntoSevenMap():
for i, (k, v) in enumerate(allMap.items()):
if i in range(0, 6):
hotMap[k] = v
# print(k, v)
if i in range(6, 21):
basicBooks[k] = v
# print(k, v)
if i in range(21, 22):
health[k] = v
# print(k, v)
if i in range(22, 23):
orphan[k] = v
# print(k, v)
if i in range(23, 35):
clinicalDepartments[k] = v
# print(k, v)
if i in range(35, 44):
chirp[k] = v
# print(k, v)
if i in range(44, 82):
doctors[k] = v
# print(k, v)
pass
def getSevenPart(html1, html2):
domain = 'https://www.zk120.com'
soup = BeautifulSoup(html1, 'html.parser')
# ResultSets = soup.find_all('h2', class_='group_title')
ResultSets = soup.find_all('h2', class_='group-hot-title')
# print(ResultSets) # 得到所有的标题 非热门的
for ResultSet in ResultSets:
tt = re.match('''<h2 class="group(.*)title">(.*)</h2>''', str(ResultSet))
liSoup = soup.find_all('li')
for i in liSoup:
lis = BeautifulSoup(str(i), 'html.parser')
allMap[lis.find('a').text] = domain + lis.find('a').get('href')
soup = BeautifulSoup(html2, 'html.parser')
ResultSets = soup.find_all('h2', class_='group_title')
for ResultSet in ResultSets:
tt = re.match('''<h2 class="group(.*)title">(.*)</h2>''', str(ResultSet))
liSoup = soup.find_all('li')
for i in liSoup:
lis = BeautifulSoup(str(i), 'html.parser')
allMap[lis.find('a').text] = domain + lis.find('a').get('href')
# for k, v in allMap.items():
# print(str(k) + " " + str(v))
def getFirstLevel(pageUrl):
res = requests.get(pageUrl, headers=headers)
res.encoding = "utf8"
print(res.url)
# 打印出页面的所有代码
# print(res.text)
soup = BeautifulSoup(res.text, 'html.parser')
ResultSets = soup.find_all('section', class_='ice_bg space_pr space_pl')
# 生成七类
getSevenPart(str(ResultSets[0]), str(ResultSets[1]))
# 分类放入map中
splitIntoSevenMap()
def accordingPartGetResults(name):
print(name)
# 热门
if name == "hotMap":
for k, v in hotMap.items():
print(str(k) + " " + str(v))
getPerResults(name, str(k), str(v))
# 基础典籍
elif name == "basicBooks":
for k, v in basicBooks.items():
print(str(k) + " " + str(v))
getPerResults(name, str(k), str(v))
# 养生保健
elif name == "health":
for k, v in health.items():
print(str(k) + " " + str(v))
getPerResults(name, str(k), str(v))
# 孤本
elif name == "orphan":
for k, v in orphan.items():
print(str(k) + " " + str(v))
getPerResults(name, str(k), str(v))
# 临症各科
elif name == "clinicalDepartments":
for k, v in clinicalDepartments.items():
print(str(k) + " " + str(v))
getPerResults(name, str(k), str(v))
# 争鸣流派
elif name == "chirp":
for k, v in chirp.items():
print(str(k) + " " + str(v))
getPerResults(name, str(k), str(v))
# 历代医家
elif name == "doctors":
for k, v in doctors.items():
print(str(k) + " " + str(v))
getPerResults(name, str(k), str(v))
def getPerResults(KeywordName, name, nameUrl):
try:
browser.get(nameUrl)
js = 'window.scrollTo(0,document.body.scrollHeight)' # 下滑到底部
try:
try:
while browser.find_element_by_class_name('getMoreBtn') is not None:
browser.execute_script(js)
time.sleep(1)
browser.find_element_by_class_name('getMoreBtn').click()
except ElementNotInteractableException:
print("已经加载完毕")
except NoSuchElementException:
print("这个就一页")
time.sleep(1)
browser.execute_script(js)
webElement = browser.find_elements_by_class_name("book_wrapper")
bookCount = len(webElement)
print("书本的数量为 -> " + str(bookCount))
for i in webElement:
try:
bookUrl = i.find_element_by_tag_name('a').get_attribute('href')
except NoSuchElementException:
bookUrl = "没有给url"
try:
bookName = i.find_element_by_tag_name('a').text
except NoSuchElementException:
bookName = "没有给书名"
try:
bookAuthor = i.find_element_by_class_name('book-author').text
except NoSuchElementException:
bookAuthor = "没有给作者名字"
try:
bookDescription = i.find_element_by_class_name('book-description').text
except NoSuchElementException:
try:
bookDescription = i.find_element_by_class_name('book-comment').text
except NoSuchElementException:
bookDescription = "没有给书的描述"
print(str(name) + "中的----> " + str(bookName) + " " + bookUrl + " " + str(bookAuthor) + " " + str(
bookDescription))
browser2.get(bookUrl)
time.sleep(1)
try:
digest = browser2.find_element_by_css_selector(
"#book_abstract > div.abstract-wrapper-div.abstract_wrapper_div.abstract-wrapper-divnew > div")
except NoSuchElementException:
print(str(bookName) + "的摘要是使用了第二种方式")
digest = browser2.find_element_by_css_selector(
"#book_abstract > div.abstract_wrapper_div > div")
finally:
pass
catalog = browser2.find_element_by_xpath('''//*[@id="book_catalog"]/table/tbody''')
trLists = catalog.find_elements_by_tag_name('tr')
Text = ""
for tr in trLists:
Text = Text + str(
tr.find_element_by_tag_name('td').find_element_by_tag_name('a').get_attribute('innerHTML')) + " "
toMongoDB(KeywordName, name, bookCount, nameUrl, bookName, bookUrl, bookAuthor, bookDescription,
digest.text, Text)
time.sleep(1)
finally:
print(str(name) + " 已经爬取完毕")
pass
if __name__ == '__main__':
page1 = 'https://www.zk120.com/ji/group/?nav=ys'
getFirstLevel(page1)
# 下面的是依次获取每种分类的具体信息 需要爬取哪个类的就取注
# accordingPartGetResults("hotMap")
# accordingPartGetResults("basicBooks") # 备查宝典有几条没查完 备查宝典里的中医人名词典这里一直卡死
# accordingPartGetResults("health")
# accordingPartGetResults("orphan")
# accordingPartGetResults("clinicalDepartments")
# accordingPartGetResults("chirp")
# accordingPartGetResults("doctors")
python + BeautifulSoup + selenium 实现爬取中医智库的古籍分类的数据的更多相关文章
- [python爬虫] Selenium定向爬取PubMed生物医学摘要信息
本文主要是自己的在线代码笔记.在生物医学本体Ontology构建过程中,我使用Selenium定向爬取生物医学PubMed数据库的内容. PubMed是一个免费的搜寻引擎,提供生物医学方 ...
- python 使用selenium模块爬取同一个url下不同页的内容(浏览器模拟人工翻页)
页面翻页,下一页可能是一个新的url 也有可能是用js进行页面跳转,url不变,解决方法是实现浏览器模拟人工翻页 目标:爬取同一个url下不同页的数据(上述第二种情况) url:http://www. ...
- [python爬虫] Selenium定向爬取海量精美图片及搜索引擎杂谈
我自认为这是自己写过博客中一篇比较优秀的文章,同时也是在深夜凌晨2点满怀着激情和愉悦之心完成的.首先通过这篇文章,你能学到以下几点: 1.可以了解Python简单爬取图片的一些思路和方法 ...
- [python爬虫] Selenium定向爬取虎扑篮球海量精美图片
前言: 作为一名从小就看篮球的球迷,会经常逛虎扑篮球及湿乎乎等论坛,在论坛里面会存在很多精美图片,包括NBA球队.CBA明星.花边新闻.球鞋美女等等,如果一张张右键另存为的话真是手都点疼了.作为程序员 ...
- python+selenium+requests爬取我的博客粉丝的名称
爬取目标 1.本次代码是在python2上运行通过的,python3的最需改2行代码,用到其它python模块 selenium 2.53.6 +firefox 44 BeautifulSoup re ...
- selenium登录爬取知乎出现:请求异常请升级客户端后重试的问题(用Python中的selenium接管chrome)
一.问题使用selenium自动化测试爬取知乎的时候出现了:错误代码10001:请求异常请升级客户端后重新尝试,这个错误的产生是由于知乎可以检测selenium自动化测试的脚本,因此可以阻止selen ...
- Python3.x:Selenium+PhantomJS爬取带Ajax、Js的网页
Python3.x:Selenium+PhantomJS爬取带Ajax.Js的网页 前言 现在很多网站的都大量使用JavaScript,或者使用了Ajax技术.这样在网页加载完成后,url虽然不改变但 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- Python爬虫:如何爬取分页数据?
上一篇文章<Python爬虫:爬取人人都是产品经理的数据>中说了爬取单页数据的方法,这篇文章详细解释如何爬取多页数据. 爬取对象: 有融网理财项目列表页[履约中]状态下的前10页数据,地址 ...
随机推荐
- 升级adb
adb 是没有自动升级的命令的,如果想要更新adb的版本,需要在网上找到自己想要的版本进行更新. 为什么要更新呢? 肯定是在使用中遇到了什么问题必须升级版本才能解决,如果不影响使用,那都无所谓.这里提 ...
- JS中Promise
Promise的作用: Promise是异步微任务,解决了异步多层嵌套回调的问题,让代码的可读性更高,更容易维护. Promise如何使用: Promise是ES6提供的一个构造函数,可以使用Prom ...
- 面向对象3(Java)
多态 基本介绍 即同一方法可以根据发送对象的不同而采用多种不同的行为方式 一个对象的实际类型是确定的,但是可以指向对象的引用类型可以很多 多态存在的条件:a.有继承关系:b.子类重写父类方法:c.父类 ...
- Android studio 使用Internet传递信息
使用Intent在Activity之间传递信息1.首先创建一个新的Activity,在activity_main.xml中设计页面,将android.support.constraint.Constr ...
- 获取gps
package com.example.myapplication;import android.Manifest;import android.annotation.SuppressLint;imp ...
- 第一个Java程序(自动关机程序)
我的第一个程序 1.新建java工程 打开Eclipse,点击File,选择New,点击Java Project ,新建名为demo的工程,如图所示: 2.编写程序 1.打开demo工程,鼠标右键sr ...
- P2212 Watering the Fields S
题目描述 给定n个点,第i个点的坐标为(xi,yi)(xi,yi),如果想连通第i个点与第j个点,需要耗费的代价为两点的距离.第i个点与第j个点之间的距离使用欧几里得距离进行计算,即:(xi-xj ...
- Q:带宽检测 iperf工具
一.下载 iperf的下载地址为:https://iperf.fr/iperf-download.php,选择相应的版本 linux安装 rpm -qa|grep -i rperf rpm -ivh ...
- vue使用keepalive缓存上级页面
参考: vue单页应用前进刷新后退不刷新方案探讨 vue,vue-router实现浏览器返回不刷新页面 vue 怎么处理当this.$router.go(-1)时,判断返回指定页面设置指定页面的kee ...
- Docker 修改容器中的mysql密码
1.查看容器服务 docker ps2.进入mysql容器 docker exec -it mysql /bin/bash 注:mysql为容器的名字 3.登录MySQL mysql -u root ...