[*]Is L2 Physics-Informed Loss Always Suitable for Training Physics-Informed Neural Network?

NeurIPS 2022
本篇工作对PINN中的物理损失进行了探究,作者认为L2损失并不总是适用于训练PINN。并从PDE解的稳定性角度给出了理论性的说明。读了这篇文章,感觉自己的毕业论文做的十分浅显。顶会文章的质量很不错,有理论支持,实验工作量也丰富。
本文的视角从PDE中稳定性的概念入手,来研究当损失接近0时学习解的渐近行为。证明了对于一般的Lp损失,只有p足够大时,一类宽的HJB方程才是稳定的。因此,使用L2损失并不适合于这类方程,L∞损失才是更合适的选择。作者提出了一种类似对抗训练精神的方法,来解决发现的问题。本文主要考虑高阶HJB方程。
在目前PINN的问题中,当L2损失等于0时,学习到的解就等价于精确解,这是自然的。但是,目前在实践中更常见的,具有小的但是非零损失的学习解的质量,目前仍然没有任何的近似保证。因此作者关心一个基础的问题:能否保证具有较小的物理信息损失的学习解始终对应于精确解的良好近似器?所以作者引出了稳定性,从稳定性的角度分析这个问题。此前的工作在面对PINN训练失败时,将目光集中到复杂的优化域和损失项之间的不可比较性。
文章在PINN的框架下分析PDE的稳定性,稳定性表征当物理信息损失接近0时,学习解和精确解之间的渐近距离。如果PDE在某些损失函数下不稳定,那我们可能就无法通过最小化损失来获得良好的近似解。本文证明了这类方程需要Lp损失中p足够大。L2损失并不适合于这类方程,因为所学习到的解会任意的远离精确解。稳定性从形式上表征了当一个微小扰动改变算子、初始条件、边界条件时,PDE解的行为。方程是稳定的,如果扰动PDE的解在扰动接近零是收敛到精确解。
本文针对的高阶HJB方程,理论结果表明L∞会是更好的选择。受到这一点的启发,作者提出了一种新的算法用来训练PINN,采用最小最大优化进程来最小化L∞损失。具体的方法将在后面介绍。
由于神经网络的能力或者优化过程中的随机性,损失项并不会完全收敛到0。所以我们要考虑具有小损失的解是否是精确解的一个好的近似?这个问题等价于PDE中稳定性的概念。我们了解到:一些高阶HJB方程是稳定的,但不是L2稳定的,也就是L2物理信息损失将会失败于去寻找解。理论结果如下:

更重要的是,理论结果表明,物理信息损失的设计也发挥着重要的作用对于使用PINN求解PDE。
使用对抗训练求解HJB方程
目标函数是:
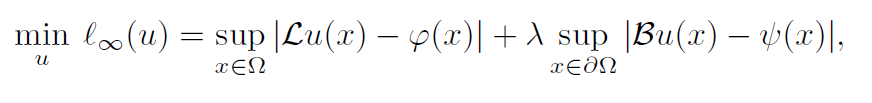
这个目标项可以看作一个最小最大问题,内循环是寻找损失最大的数据点,分别在域内和边界上,外循环上是最小化问题,寻找u使得总损失最小。
在每次循环中,模型参数和数据点都会更新。为了获得等效的L∞损失(也就是令p足够大),作者使用最大损失的方法。方法如下:
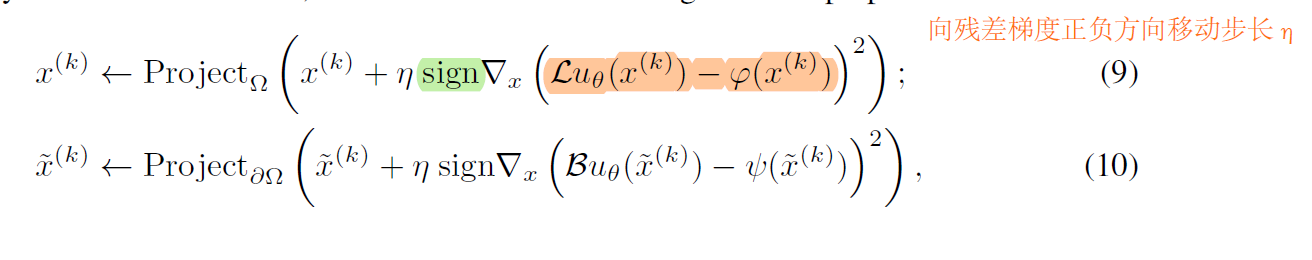
所提出方法的伪代码如下:

通过内循环找到损失最大的点,然后再利用任何的一阶方法进行优化(这就等效于L无穷范数的损失)。
实验结果如下,提升的幅度还是很大的。
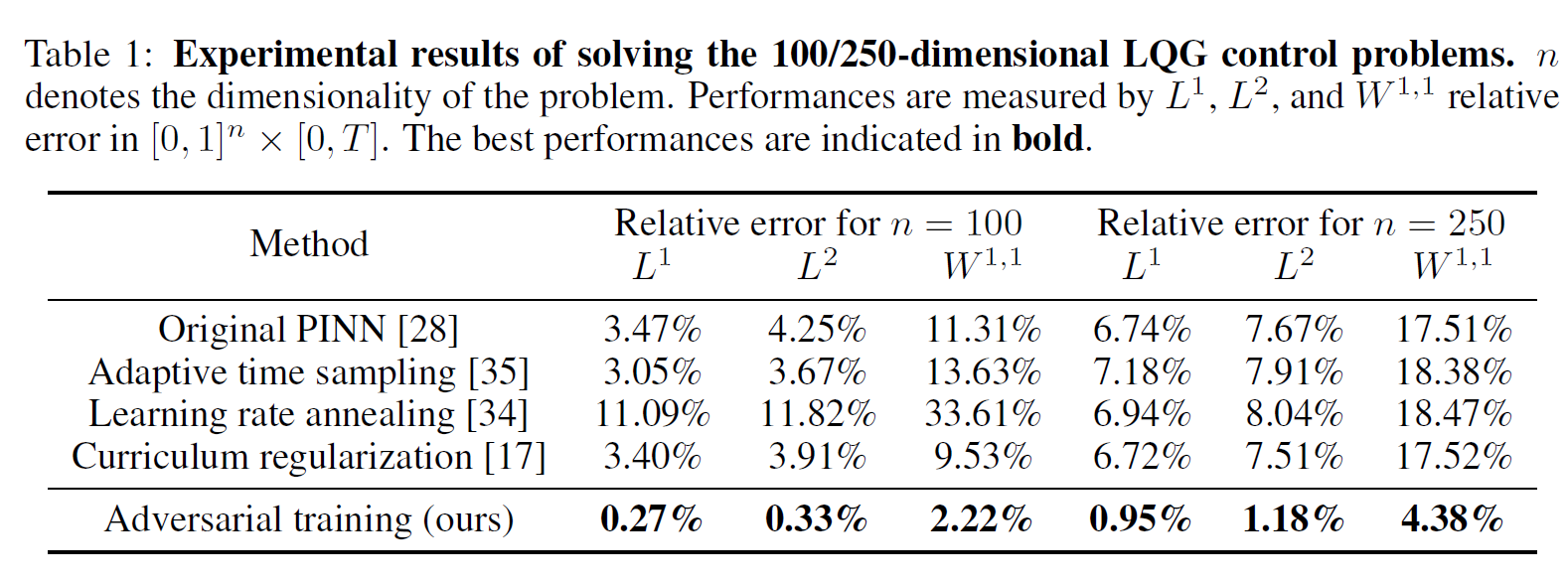
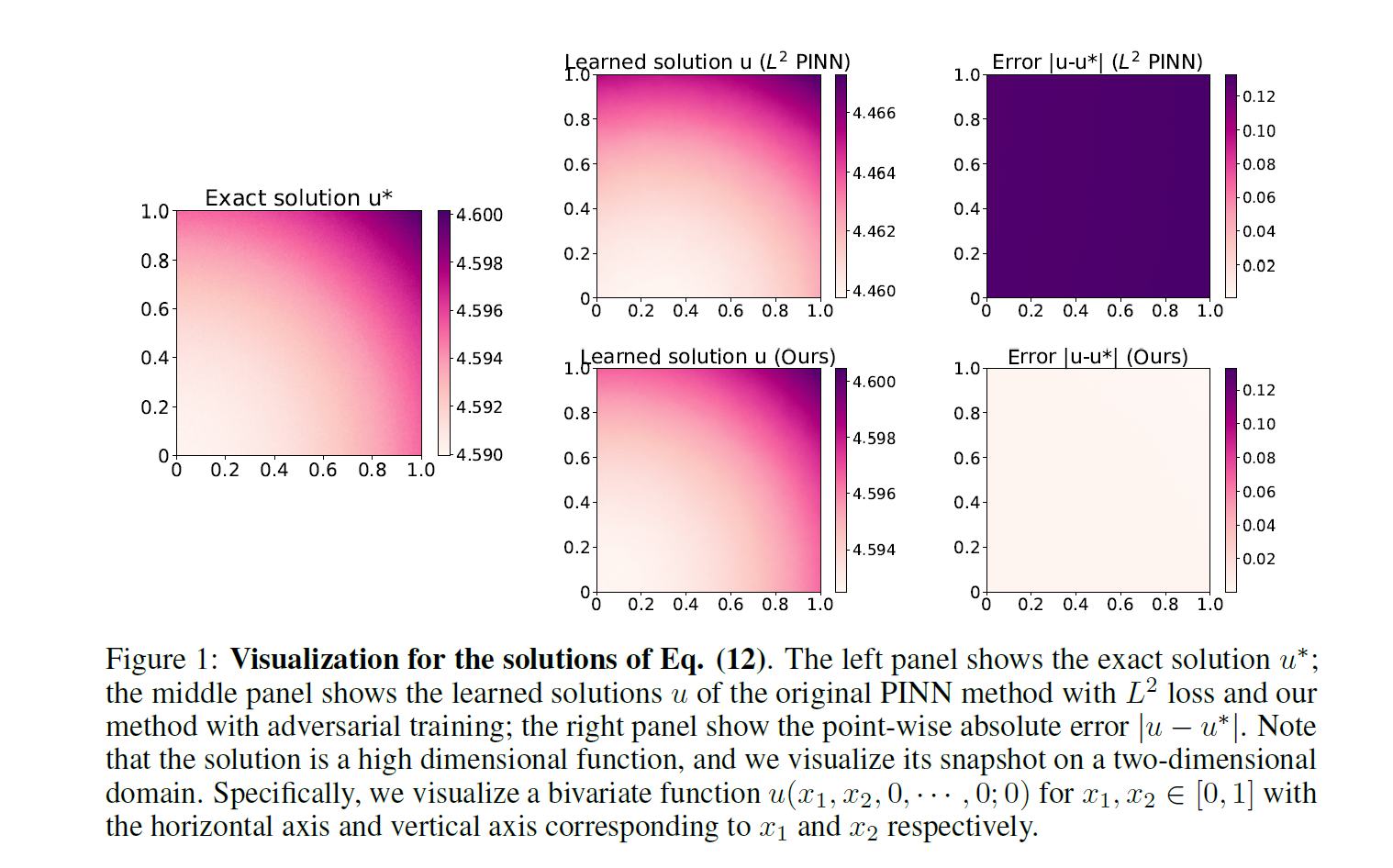
[*]Is L2 Physics-Informed Loss Always Suitable for Training Physics-Informed Neural Network?的更多相关文章
- A Deep Neural Network’s Loss Surface Contains Every Low-dimensional Pattern
目录 概 相关工作 主要内容 引理1 定理1 定理2 A Deep Neural Network's Loss Surface Contains Every Low-dimensional Patte ...
- [C4] Andrew Ng - Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization
About this Course This course will teach you the "magic" of getting deep learning to work ...
- 《MATLAB Deep Learning:With Machine Learning,Neural Networks and Artificial Intelligence》选记
一.Training of a Single-Layer Neural Network 1 Delta Rule Consider a single-layer neural network, as ...
- TFlearn——(1)notMNIST
1, 数据集简介 notMNIST, 看名字就知道,跟MNIST脱不了干系,其实就是升级版的MNIST,含有 A-J 10个类别的艺术印刷体字符,字符的形状各异,噪声更多,难度比 MNIST 要 ...
- A great tutorial with Jupyter notebook for ML beginners
An end to end implementation of a Machine Learning pipeline SPANDAN MADAN Visual Computing Group, Ha ...
- tflearn 中文汉字识别模型试验汇总
def get_model(width, height, classes=40): # TODO, modify model # Building 'VGG Network' network = in ...
- CNN 文本分类模型优化经验——关键点:加卷积层和FC可以提高精度,在FC前加BN可以加快收敛,有时候可以提高精度,FC后加dropout,conv_1d的input维度加大可以提高精度,但是到256会出现OOM。
network = tflearn.input_data(shape=[None, max_len], name='input') network = tflearn.embedding(networ ...
- 神经网络的结构汇总——tflearn
一些先进的网络结构: # https://github.com/tflearn/tflearn/blob/master/examples/images/highway_dnn.py # -*- cod ...
- tflearn中一些CNN RNN的例子
lstm.py # -*- coding: utf-8 -*- """ Simple example using LSTM recurrent neural networ ...
- 使用神经网络-垃圾邮件检测-LSTM或者CNN(一维卷积)效果都不错【代码有问题,pass】
from sklearn.feature_extraction.text import CountVectorizer import os from sklearn.naive_bayes impor ...
随机推荐
- Qt实现简单的TCP协议(客户端的实现)
1.QT提供了QTcpSocket类,可以直接实例化一个客户端.需要在pro文件中添加 QT += network 2.连接服务端 connect(connectbutton,SIGNAL(cli ...
- SPI读写官方Demo
// SPDX-License-Identifier: GPL-2.0-only /* * SPI testing utility (using spidev driver) * * Copyrigh ...
- JS下载单个图片、单个视频;批量下载图片,批量下载视频
下载单张图片 import JSZip from "jszip"; import FileSaver from "file-saver"; downloadIa ...
- the default discovery settings are unsuitable for production use at least one of...的解决办法
解决办法 elasticsearch.yml加上 discovery.type: single-node
- OOP学习讲义
什么是OOP 场景:我进入一家IT公司,面试官问道我这个问题.OOP?WTF?"众所周知,Java是一门面向对象的开发语言,所以OOP不就是面向对象设计咩.Java把所有的元素都当成是一个对 ...
- 尺取法 C - Vasya and String CodeForces - 676C
C - Vasya and String CodeForces - 676C #include<iostream> using namespace std; int main() { lo ...
- HTTP知识点
HTTP 请求/响应的步骤:(工作原理) 客户端连接到 Web 服务器 一个 HTTP 客户端,通常是浏览器,与 Web 服务器的 HTTP 端口(默认为 80)建立一个 TCP 套接字连接.例如,h ...
- C++ 中的匿名函数(lambda表达式)
问题引入 使用std::sort函数对自定义类型排序时,我们需要传入一个比较函数作为参数.该比较函数只需要使用一次,但占有一个全局命名域中的名字,而且非常短,短到不需要名字就知道它的作用.这很浪费命名 ...
- CodeGym自学笔记07——入门Java书籍
入门Java书籍 Head First Java Java:The Complete Reference,作者:Herbert Schildt 这本书对初学者也很有好处.与前一本书的主要区别在于素 ...
- MapReduce原理——切片代码分析
(1)程序先找到数据存储的目录 (2)遍历目录对每个文件进行切片 (3)遍历一个文件: 获取文件大小 计算切片大小 默认情况下,切片大小等于blocksize 每次切片时都要判断剩下部分师否大于块的1 ...