Python之利用jieba库做词频统计且制作词云图
一.环境以及注意事项
1.windows10家庭版 python 3.7.1
2.需要使用到的库 wordcloud(词云),jieba(中文分词库),安装过程不展示
3.注意事项:由于wordcloud默认是英文不支持中文,所以需要一个特殊字体 simsum.tff.下载地址: https://s3-us-west-2.amazonaws.com/notion-static/b869cb0c7f4e4c909a069eaebbd2b7ad/simsun.ttf
请安装到C:\Windows\Fonts 里面
4.测试所用的三国演义txt文本下载地址(不保证永久有效):https://www.ixdzs.com/d/1/1241/
5.调试过程可能会出现许多小问题,请检查单词是否拼写正确,如words->word等等
6.特别提醒:背景图片和文本需 放在和py文件同一个地方
二.词频统计以及输出
(1) 代码如下(封装为txt函数)
函数作用:jieba库三种模式中的精确模式(输出的分词完整且不多余) jieba.lcut(str): 返回列表类型
def txt(): #输出词频前N的词语
txt = open("三国演义.txt","r").read() #打开txt文件,要和python在同一文件夹
words = jieba.lcut(txt) #精确模式,返回一个列表
counts = {} #创建字典
excludes = ("将军","二人","却说","荆州","不可","不能","如此","如何",\
"军士","左右","军马","商议","大喜") #规定要去除的没意义的词语
for word in words:
if len(word) == 1: #把意义相同的词语归一
continue
elif word == "诸葛亮" or word == "孔明曰":
rword = "孔明"
elif word == '关公' or word == '云长':
rword = '关羽'
elif word == '玄德' or word == '玄德曰':
rword = '刘备'
elif word == '孟德' or word == "丞相" or word == '曹躁':
rword = '曹操'
else:
rword = word
counts[rword] = counts.get(rword,0) + 1 #字典的运用,统计词频P167
for word in excludes: #删除之前所规定的词语
del(counts[word])
items = list(counts.items()) #返回所有键值对P168
items.sort(key=lambda x:x[1], reverse =True) #降序排序
N =eval(input("请输入N:代表输出的数字个数"))
wordlist=list()
for i in range(N):
word,count = items[i]
print("{0:<10}{1:<5}".format(word,count)) #输出前N个词频的词语
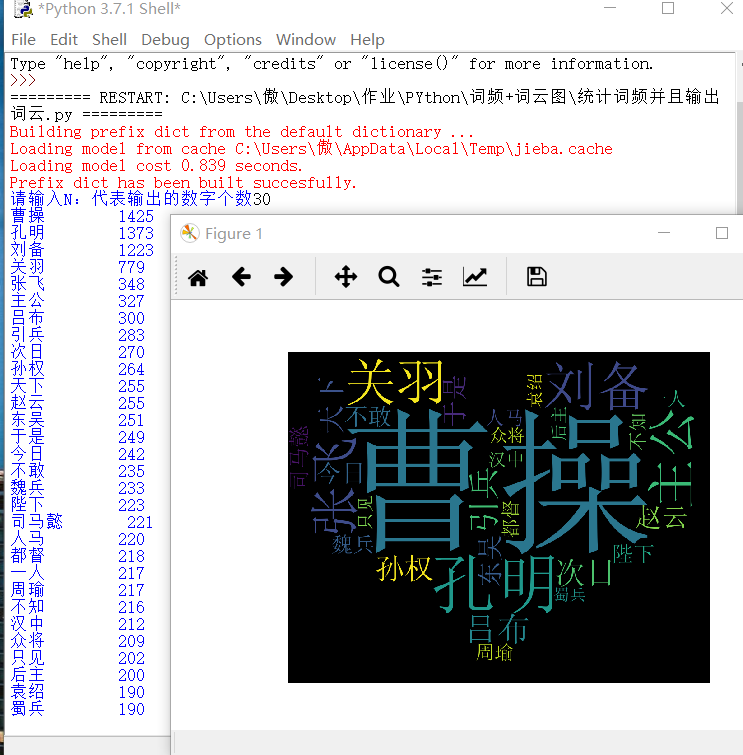
(2)效果图

三.词频+词云
(1) 词云代码如下 (由于是词频与词云结合,此函数不能直接当普通词云函数使用,自行做恰当修改即可)
def create_word_cloud(filename):
wl = txt() #调用函数获取str
cloud_mask = np.array(Image.open("love.jpg"))#词云的背景图,需要颜色区分度高 需要把背景图片名字改成love.jpg
wc = WordCloud(
background_color = "black", #背景颜色
mask = cloud_mask, #背景图cloud_mask
max_words=100, #最大词语数目
font_path = 'simsun.ttf', #调用font里的simsun.tff字体,需要提前安装
height=1200, #设置高度
width=1600, #设置宽度
max_font_size=1000, #最大字体号
random_state=1000, #设置随机生成状态,即有多少种配色方案
)
myword = wc.generate(wl) # 用 wl的词语 生成词云
# 展示词云图
plt.imshow(myword)
plt.axis("off")
plt.show()
wc.to_file('1.jpg') # 把词云保存下当前目录(与此py文件目录相同)
(2) 词频加词云结合的 完整 代码如下
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import jieba
import numpy as np
from PIL import Image def txt(): #输出词频前N的词语并且以str的形式返回
txt = open("三国演义.txt","r").read() #打开txt文件,要和python在同一文件夹
words = jieba.lcut(txt) #精确模式,返回一个列表
counts = {} #创建字典
excludes = ("将军","二人","却说","荆州","不可","不能","如此","如何",\
"军士","左右","军马","商议","大喜") #规定要去除的没意义的词语
for word in words:
if len(word) == 1: #把意义相同的词语归一
continue
elif word == "诸葛亮" or word == "孔明曰":
rword = "孔明"
elif word == '关公' or word == '云长':
rword = '关羽'
elif word == '玄德' or word == '玄德曰':
rword = '刘备'
elif word == '孟德' or word == "丞相" or word == '曹躁':
rword = '曹操'
else:
rword = word
counts[rword] = counts.get(rword,0) + 1 #字典的运用,统计词频P167
for word in excludes: #删除之前所规定的词语
del(counts[word])
items = list(counts.items()) #返回所有键值对P168
items.sort(key=lambda x:x[1], reverse =True) #降序排序
N =eval(input("请输入N:代表输出的数字个数"))
wordlist=list()
for i in range(N):
word,count = items[i]
print("{0:<10}{1:<5}".format(word,count)) #输出前N个词频的词语
wordlist.append(word) #把词语word放进一个列表
a=' '.join(wordlist) #把列表转换成str wl为str类型,所以需要转换
return a def create_word_cloud(filename):
wl = txt() #调用函数获取str!!
#图片名字 需一致
cloud_mask = np.array(Image.open("love.jpg"))#词云的背景图,需要颜色区分度高 wc = WordCloud(
background_color = "black", #背景颜色
mask = cloud_mask, #背景图cloud_mask
max_words=100, #最大词语数目
font_path = 'simsun.ttf', #调用font里的simsun.tff字体,需要提前安装
height=1200, #设置高度
width=1600, #设置宽度
max_font_size=1000, #最大字体号
random_state=1000, #设置随机生成状态,即有多少种配色方案
) myword = wc.generate(wl) # 用 wl的词语 生成词云
# 展示词云图
plt.imshow(myword)
plt.axis("off")
plt.show()
wc.to_file('1.jpg') # 把词云保存下当前目录(与此py文件目录相同) if __name__ == '__main__':
create_word_cloud('三国演义')
(3) 效果图如下(输出词频以及词云)
Python之利用jieba库做词频统计且制作词云图的更多相关文章
- python实例:利用jieba库,分析统计金庸名著《倚天屠龙记》中人物名出现次数并排序
本实例主要用到python的jieba库 首先当然是安装pip install jieba 这里比较关键的是如下几个步骤: 加载文本,分析文本 txt=open("C:\\Users\\Be ...
- jieba库分词词频统计
代码已发至github上的python文件 词频统计结果如下(词频为1的词组数量已省略): {'是': 5, '风格': 4, '擅长': 4, '的': 4, '兴趣': 4, '宣言': 4, ' ...
- jieba库及词频统计
import jieba txt = open("C:\\Users\\Administrator\\Desktop\\流浪地球.txt", "r", enco ...
- jieba (中文词频统计) 、collections (字频统计)、WordCloud (词云)
py库: jieba (中文词频统计) .collections (字频统计).WordCloud (词云) 先来个最简单的: # 查找列表中出现次数最多的值 ls = [1, 2, 3, 4, 5, ...
- 【python】一篇文章里的词频统计
一.环境 1.python3.6 2.windows系统 3.安装第三方模块 pip install wordcloud #词云展示库 pip install jieba #结巴分词 pip inst ...
- Python 之 使用 PIL 库做图像处理
http://www.cnblogs.com/way_testlife/archive/2011/04/17/2019013.html Python 之 使用 PIL 库做图像处理 1. 简介. 图像 ...
- 第一百四十三节,JavaScript,利用封装库做百度分享
JavaScript,利用封装库做百度分享 效果图 html代码 <div id="share"> <h2>分享到</h2> <ul> ...
- [转]Python 之 使用 PIL 库做图像处理
Python 之 使用 PIL 库做图像处理 1. 简介. 图像处理是一门应用非常广的技术,而拥有非常丰富第三方扩展库的 Python 当然不会错过这一门盛宴.PIL (Python Imaging ...
- e分钟带你利用Python制作词云图
随着大数据时代的来临,数据分析与可视化,显得越来越重要,今天给小伙伴们带来一种最常见的数据可视化图形-词云图的制作方法. 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法 ...
随机推荐
- List集合概述和特点
List集合概述 有序集合(也称序列)用户可以精确控制列表的每一个元素的位置插入,用户可以通过整数索引访问元素,并搜索列表中的元素 与set集合不同,列表通常允许重复的元素 List集合的特点 有序: ...
- 设计模式—建造者模式(Builder)
title: 设计模式-建造者模式 建造者模式(Builder)是一步一步创建一个复杂的对象,它允许用户只通过指定复杂对象的类型和内容就可以构建它们,用户不需要知道内部的具体构建细节.建造者模式属于对 ...
- Redis底层函数详解
Redis底层函数详解 serverCron 函数 它负责管理服务器的资源,并维持服务器的正常运行.在执行 serverCron 函数的过程中会调用相关的子函数,如 trackOperationsPe ...
- 网维大师无盘刷新B盘方法
- 01FPGA设计流程
今天学习了FPGA设计流程的视频,我理解要做一个完整的FPGA系统,所要经历的步骤,先将它简单总结如下: 我在对上面的流程图进行解释: 第一:设计定义就是我们这个FPGA系统或者FPGA设计所要实现的 ...
- 使用DeepWalk从图中提取特征
目录 数据的图示 不同类型的基于图的特征 节点属性 局部结构特征 节点嵌入 DeepWalk简介 在Python中实施DeepWalk以查找相似的Wikipedia页面 数据的图示 当你想到" ...
- 莎士比亚电路ヾ(≧▽≦*)o
偶尔记录一件有趣的事儿! 这个电路叫做 "莎士比亚电路"[1],请自行参悟,ヾ(≧▽≦)o,ヾ(≧▽≦)o,ヾ(≧▽≦*)o ヾ(≧▽≦*)o . <穿越计算机的迷雾> ...
- Ali_Cloud++:安装 RabbitMQ安装及环境配置
注意事项:rabbitMA版本和erlang并不是同步更新的,会出现版本不匹配,安装不了. 两都版本对应 参考官网文档 其它下载地址 1):Erlang安装 (因为是erlant语言编写的, ...
- 5.Maven坐标
而这个坐标也意味着jar包等保存在 C:\Users\用户名.m2\repository\org\apache\tomcat\tomcat-catalina\9.0.2
- 泛型Genericity
泛型:可以在类或方法中预支地使用未知的类型. 注意: 一般在创建对象时,将未知的类型确定具体的类型.当没有指定泛型时,默认类型为Object类型. E - Element ...