python实例:利用jieba库,分析统计金庸名著《倚天屠龙记》中人物名出现次数并排序
本实例主要用到python的jieba库
首先当然是安装pip install jieba
这里比较关键的是如下几个步骤:
加载文本,分析文本
txt=open("C:\\Users\\Beckham\\Desktop\\python\\倚天屠龙记.txt","r", encoding='utf-8').read() #打开倚天屠龙记文本
words=jieba.lcut(txt) #jieba库分析文本
对数据进行筛选和处理
for word in words: #筛选分析后的词组
if len(word)==1: #因为词组中的汉字数大于1个即认为是一个词组,所以通过continue结束点读取的汉字书为1的内容
continue
elif word=="教主": #书中教主也指张无忌,即循环读取到教主也认为是张无忌这个名字出现一次,后面类似
rword="张无忌"
elif word=="无忌":
rword="张无忌"
elif word=="义父":
rword="谢逊"
else:
rword=word
counts[rword]=counts.get(rword,0)+1 #对rword出现的频率进行统计,当rword不在words时,返回值是0,当rword在words中时,返回+1,以此进行累计计数 for word in exculdes:#如果循环读取到的词组与exculdes字典内的内容匹配,那么过滤掉(不显示)这个词组
del(counts[word])
创建列表显示和排序
items=list(counts.items())#字典到列表
items.sort(key=lambda x:x[1],reverse=True)#lambda是一个隐函数,是固定写法,以下命令的意思就是按照记录的第2列排序 for i in range(15):#显示前15位数据
word,count=items[i]
print("{0:<10}{1:>10}".format(word,count)) #0:<10左对齐,宽度10,”>10"右对齐
具体脚本如下,每一步都有解析,就不分步解释了
# -*-coding:utf8-*-
# encoding:utf-8 import jieba #倒入jieba库 txt=open("C:\\Users\\Beckham\\Desktop\\python\\倚天屠龙记.txt","r", encoding='utf-8').read() #打开倚天屠龙记文本 exculdes={"说道","甚么","自己","武功","咱们","一声","心中","少林","一个","弟子",
"明教","便是","之中","如何","师父","只见","怎么","两个","没有","不是","不知","这个","不能","只是",
"他们","突然","出来","如此","今日","知道","我们","心想","二人","两人","不敢","虽然","姑娘","这时","众人"
,"可是","原来","之下","当下","身子","你们","脸上","左手","手中","倘若","之后","起来","喝道","武当派","跟着"
,"武当","却是","登时","身上","说话","长剑","峨嵋派","性命","难道","丐帮","兄弟","见到","魔教","不可","心下"
,"之间","少林寺","伸手","高手","一招","这里","正是"} #创建字典,主要用于存储非人物名词,供后面剔除使用 words=jieba.lcut(txt) #jieba库分析文本
counts={} for word in words: #筛选分析后的名词
if len(word)==1: #因为词组中的汉字数大于1个即认为是一个词组,所以通过continue结束掉读取的汉字书为1的内容
continue
elif word=="教主": #书中教主也指张无忌,即循环读取到教主也认为是张无忌这个名字出现一次,后面类似
rword="张无忌"
elif word=="无忌":
rword="张无忌"
elif word=="义父":
rword="谢逊"
else:
rword=word
counts[rword]=counts.get(rword,0)+1 #对rword出现的频率进行统计,当rword不在words时,返回值是0,当rword在words中时,返回+1,以此进行累计计数 for word in exculdes:#如果循环读取到的词组与exculdes字典内的内容匹配,那么过滤掉(不显示)这个词组
del(counts[word]) items=list(counts.items())#字典到列表
items.sort(key=lambda x:x[1],reverse=True)#lambda是一个隐函数,是固定写法,以下命令的意思就是按照记录的第2列排序 for i in range(15):#显示前15位数据
word,count=items[i]
print("{0:<10}{1:>10}".format(word,count)) #0:<10左对齐,宽度10,”>10"右对齐
毫无疑问,张无忌妥妥的主角
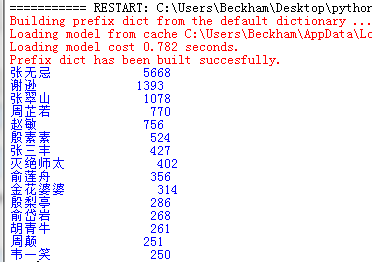
参考:
https://gitee.com/huangshenru/codes/clneriovm0sqxw5k89j2h98
https://www.cnblogs.com/0330lgs/p/10648168.html
python实例:利用jieba库,分析统计金庸名著《倚天屠龙记》中人物名出现次数并排序的更多相关文章
- Python之利用jieba库做词频统计且制作词云图
一.环境以及注意事项 1.windows10家庭版 python 3.7.1 2.需要使用到的库 wordcloud(词云),jieba(中文分词库),安装过程不展示 3.注意事项:由于wordclo ...
- python 利用jieba库词频统计
1 #统计<三国志>里人物的出现次数 2 3 import jieba 4 text = open('threekingdoms.txt','r',encoding='utf-8').re ...
- Python实例---利用正则实现计算器[FTL版]
import re # 格式化 def format_str(str): str = str.replace('--', '+') str = str.replace('-+', '-') str = ...
- jieba库词频统计
一.jieba 库简介 (1) jieba 库的分词原理是利用一个中文词库,将待分词的内容与分词词库进行比对,通过图结构和动态规划方法找到最大概率的词组:除此之外,jieba 库还提供了增加自定义中文 ...
- jieba库词频统计练习
在sypder上运行jieba库的代码: import matplotlib.pyplot as pltfracs = [2,2,1,1,1]labels = 'houqin', 'jiemian', ...
- python入门之jieba库的使用
对于一段英文,如果希望提取其中的的单词,只需要使用字符串处理的split()方法即可,例如“China is a great country”. 然而对于中文文本,中文单词之间缺少分隔符,这是中文 ...
- python 中文分词库 jieba库
jieba库概述: jieba是优秀的中文分词第三方库 中文文本需要通过分词获得单个的词语 jieba是优秀的中文分词第三方库,需要额外安装 jieba库分为精确模式.全模式.搜索引擎模式 原理 1. ...
- Python爬虫实例(六)多进程下载金庸网小说
目标任务:使用多进程下载金庸网各个版本(旧版.修订版.新修版)的小说 代码如下: # -*- coding: utf-8 -*- import requests from lxml import et ...
- 【python】利用jieba中文分词进行词频统计
以下代码对鲁迅的<祝福>进行了词频统计: import io import jieba txt = io.open("zhufu.txt", "r" ...
随机推荐
- JAVA环境+eclipse+tomcat+maven配置
1.JDK的安装 首先下载JDK,这个从sun公司官网可以下载,根据自己的系统选择64位还是32位,安装过程就是next一路到底.安装完成之后当然要配置环境变量了. ----------------- ...
- C# 一句很简单而又很经典的代码
一.知识点 二.问题 如果以上四个问题,你很自信,那么以下,您就不要看了,因为我想说的东西真的很简单. 如果你开始怀疑自己,可以继续向下看.你自己到底真的理解吗??? 再看下面这段代码有没有问题? c ...
- MySql(Windows)
百度云:链接:http://pan.baidu.com/s/1nvlSzMh 密码:o1cw 官网下载网址:http://dev.mysql.com/downloads/mysql/
- spark 源码分析之十九 -- DAG的生成和Stage的划分
上篇文章 spark 源码分析之十八 -- Spark存储体系剖析 重点剖析了 Spark的存储体系.从本篇文章开始,剖析Spark作业的调度和计算体系. 在说DAG之前,先简单说一下RDD. 对RD ...
- 配置没有问题,虚拟机Ubuntu系统ifconfig没有网卡信息
如果没有问题,前几天都好好的,突然出现这个问题 sudo ifconfig etho up 其中eth0是我的网卡名称
- Linux学习笔记05之网络基础知识
一.OSI参考模型:适用于所有网络,现有模型,后有协议 1.应用层:应用程序.用户接口 2.表示层:编码转换.压缩.解压.加密等 3.会话层:建立.维护.拆除会话 4.传输层规定了应用程序的的接口 协 ...
- ASP.NET Core on K8S深入学习(2)部署过程解析与Dashboard
上一篇<K8S集群部署>中搭建好了一个最小化的K8S集群,这一篇我们来部署一个ASP.NET Core WebAPI项目来介绍一下整个部署过程的运行机制,然后部署一下Dashboard,完 ...
- postman使用pre-request script计算md5
接口加了验签逻辑,具体是md5(salt+时间戳).被某君吐槽说测试不方便啊能不能先关掉.其实没有必要打开又关闭验签功能,postman的pre-request script功能完全可以模拟客户端加密 ...
- Git命令备忘录
目录 前言 基本内容 开始之前 基础内容 远程仓库 分支管理 前言 Git在平时的开发中经常使用,整理Git使用全面的梳理. 基本内容 开始之前 请自行准备好Git工具以及配置好Git的基本配置 基础 ...
- 【Java笔记】【Java核心技术卷1】chapter3 D4变量
package chapter3; public class D4变量 { public static final int BBB=100; //类常量 public static void main ...