03 HDFS的客户端操作
服务器和客户端的概念

hdfs的客户端有多种形式
1、网页形式
2、命令行形式
3、客户端在哪里运行,没有约束,只要运行客户端的机器能够跟hdfs集群联网
参数配置
文件的切块大小和存储的副本数量,都是由客户端决定!
所谓的由客户端决定,是通过配置参数来定的
hdfs的客户端会读以下两个参数,来决定切块大小、副本数量:
切块大小的参数: dfs.blocksize
副本数量的参数: dfs.replication
上面两个参数应该配置在客户端机器的hadoop目录中的hdfs-site.xml中配置
<property>
<name>dfs.blocksize</name>
<value>64m</value>
</property> <property>
<name>dfs.replication</name>
<value>2</value>
</property>
网页形式
http://192.168.11.25:50070
命令行形式
dfs HDFS文件系统命令
namenode -format namenode格式化
secondarynamenode 启动secondarynamenode
namenode 启动namenode
journalnode 启动journalnode
zkfc 启动ZK Failover Controller daemon(故障转移控制器守护进程)
datanode 启动datanode
dfsadmin 启动DFS管理客户端
haadmin 启动DFS HA管理客户端
fsck 运行DFS文件系统检查工具
balancer 运行集群平衡工具
jmxget 从nameNode或dataNode获取JMX输出值
oiv 应用fsimage离线查看器
oiv_legacy 对遗留的fsimage应用fsimage离线查看器
oev 应用edits离线查看器
fetchdt 从nameNode提取代理令牌
getconf 获取HDFS的配置信息
groups 获取用户属于哪个属于用户组
snapshotDiff 返回两个快照的不同,或返回快照的目录内容的不同
lsSnapshottableDir 列出所有快照表目录
portmap 运行端口映射服务
nfs3 运行 NFS-3 网关
cacheadmin 配置HDFS的缓存
命令方式 hdfs dfs 选项
| 选项名称 | 使用方式 | 含义 |
|
-ls
|
-ls <路径>
|
查看指定路径的当前目录结构
|
|
-lsr
|
-lsr <路径> |
递归查看指定路径的目录结构
|
|
-du
|
-du <路径>
|
统计目录下个文件大小
|
|
-dus
|
-dus <路径>
|
汇总统计目录下文件(夹)大小
|
|
-count
|
-count [-q] <路径>
|
统计文件(夹)数量
|
|
-mv
|
-mv <源路径> <目标路径>
|
移动到指定的位置
|
|
-cp
|
-cp <源路径> <目的路径> | 复制到指定的位置 |
| -rm | -rm [-skipTrash] <路径> | 删除文件/空白文件夹 |
|
-rmr
|
-rmr [-skipTrash] <路径> | 递归删除 |
|
-put
|
-put <多个linux上的文件> <hdfs路径> | 上传文件 |
|
-copyFromLocal
|
-copyFromLocal <多个linux上的文件> <hdfs路径> | 从本地复制 |
|
-moveFromLocal
|
-moveFromLocal <多个linux上的文件> <hdfs路径> | 从本地移动 |
|
-getmerge
|
-getmerge <源路径> <linux路径> | 合并到本地 |
|
-cat
|
-cat <hdfs路径> | 查看文件内容 |
|
-text
|
-text <hdfs路径> | 查看文件内容 |
|
-copyToLocal
|
-copyToLocal [-ignoreCrc] [-crc] [hdfs源路径] [linux目的路径] | 从本地复制 |
|
-moveToLocal
|
-moveToLocal [-crc] <hdfs源路径> <linux目的路径> | 从本地移动 |
|
-mkdir
|
-mkdir <hdfs路径> | 创建空白文件夹 |
|
-setrep
|
-setrep [-R] [-w] <副本数> <路径> | 修改副本数量 |
|
-touchz
|
-touchz <文件路径> | 创建空白文件 |
|
-stat
|
-stat[format] <路径> | 显示文件统计信息 |
|
-tail
|
-tail [-f] <文件> | 查看文件尾部信息 |
|
-chmod
|
-chmod[-R] <权限模式>[路径] | 修改权限 |
|
-chown
|
-chown [-R] [属主][:[属组]] 路径 | 修改属主 |
|
-chgrp
|
-chgrp [-R] 属组名称 路径 | 修改属组 |
|
-help
|
-help [命令选项] | 帮助 |
| -get | -get <hdfs文件路径> <linux目的路径> | 下载文件 |
代码形式
HDFS Java API
org.apache.hadoop.conf.Configuration 加载配置文件
org.apache.hadoop.fs.FileSystem 与HDFS连接实例
org.apache.hadoop.fs.Path 路径的抽象
org.apache.hadoop.fs.FileStatus 封装元数据信息
org.apache.hadoop.fs.FSDataInputStream HDFS读取文件的流
org.apache.hadoop.fs.FSDataOutputStream HDFS 写文件的输出流
org.apache.hadoop.io.IOUtils 文件读写工具类 HDFS存储文件,以字节形式存储
HDFS写文件流程
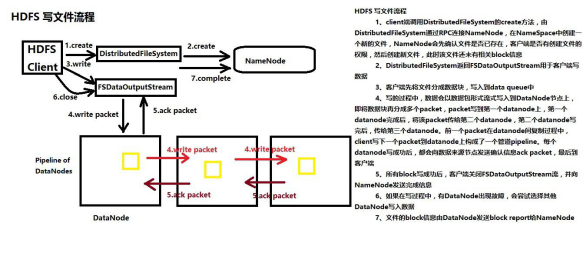
1、创建FileSystem对象
2、调用FileSystem对象的Create方法,FileSystem对象与NameNode进行RPC, NameNode检查文件是否已经存在,检查客户端有没有权限,如果通过检查,NameNode会
在 NameSpace命名空间里面,先把文件路径添加到目录树里面 同时NameNode会把DataNode列表返回给客户端
3、Create方法返回一个org.apache.hadoop.fs.FSDataOutputStream对象 4、通过FSDataOutputStream对象的write方法,将本地文件系统的文件写到DataNode上
5、客户端会将本地文件切分成block块大小
6、将block大小的数据进一步切分成数据包packet
7、客户端往DataNode写packet,第一个DataNode接收到Packet并且写成功,往第二个DataNode上传输 pipeLine
8、容错,一旦某个DataNode出现故障,客户端尝试往另外一个DataNode上写, 客户端会报告给NameNode,出现故障的DataNode。
HDFS读文件流程
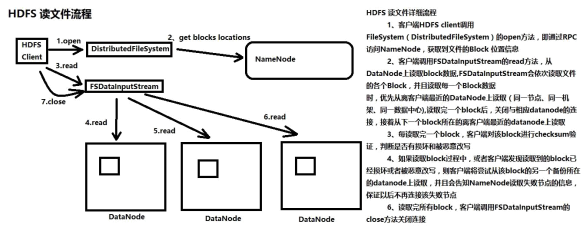
1、创建FileSystem对象
2、调用FileSystem对象的open方法,FileSystem对象与NameNode进行RPC连接, NameNode检查客户端权限,检查文件是否存在,如果通过检查, NameNode返回给客户端
关于这个文件的block信息(文件由哪些block组成,block在哪些datanode上)
3、open方法返回FSDataInputStream对象
4、客户端通过FSDataInputStream对象,从相应的DataNode读取block数据
5、读取过程中datanode挂掉,客户端尝试从该block的第二个备份所在的datanode上读取数据
6、客户端每读取一个block,会对block进行校验
HDFS权限
HDFS本身没有提供用户名、用户组的创建,在客户端调用hadoop 的文件操作命令时,hadoop 识别出执行命令 所在进程的用户名和用户组,然后使用这个用户名和组来检查文件权限。
用户名=linux命令中的`whoami`,而组名等于groups。 根据上述原理来看hdfs的文件系统权限管理较弱。
如果用户知道hdfs nameNode 地址和端口号,在安装 hdfs客户端后,使用和nameNode 相同的用户名,即可获取到所有文件的访问权限。
权限判断标准:客户端进程所属用户与HDFS文件所属者用户名称是否一样
System.setProperty("HADOOP_USER_NAME", "hadoop");
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.8.5</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
</dependencies>
### \u8BBE\u7F6E###
#log4j.rootLogger=debug,stdout,genlog
log4j.rootLogger=INFO,stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=[%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n ###
log4j.logger.logRollingFile= ERROR,test1
log4j.appender.test1 = org.apache.log4j.RollingFileAppender
log4j.appender.test1.layout = org.apache.log4j.PatternLayout
log4j.appender.test1.layout.ConversionPattern =%d{yyyy-MMM-dd HH:mm:ss}-[TS] %p %t %c - %m%n
log4j.appender.test1.Threshold = DEBUG
log4j.appender.test1.ImmediateFlush = TRUE
log4j.appender.test1.Append = TRUE
log4j.appender.test1.File = d:/logs/collect/collect.log
log4j.appender.test1.MaxFileSize = 102400KB
log4j.appender.test1.MaxBackupIndex = 200
### log4j.appender.test1.Encoding = UTF-8
package cn.oracle.core; import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.Arrays; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import org.junit.Before;
import org.junit.Test; public class HdfsClient { public static void main(String[] args) throws Exception {
/**
* Configuration参数对象的机制:
* 构造时,会加载jar包中的默认配置 xx-default.xml
* 再加载 用户配置xx-site.xml ,覆盖掉默认参数
* 构造完成之后,还可以conf.set("p","v"),会再次覆盖用户配置文件中的参数值
*/
// new Configuration()会从项目的classpath中加载core-default.xml hdfs-default.xml core-site.xml hdfs-site.xml等文件
Configuration conf = new Configuration(); // 指定本客户端上传文件到hdfs时需要保存的副本数为:2
conf.set("dfs.replication", "2");
// 指定本客户端上传文件到hdfs时切块的规格大小:64M
conf.set("dfs.blocksize", "64m"); // 构造一个访问指定HDFS系统的客户端对象: 参数1:——HDFS系统的URI,参数2:——客户端要特别指定的参数,参数3:客户端的身份(用户名)
FileSystem fs = FileSystem.get(new URI("hdfs://hdp-01:9000/"), conf, "root"); // 上传一个文件到HDFS中
fs.copyFromLocalFile(new Path("D:/install-pkgs/hbase-1.2.1-bin.tar.gz"), new Path("/aaa/")); fs.close();
} FileSystem fs = null; @Before
public void init() throws Exception{
Configuration conf = new Configuration();
conf.set("dfs.replication", "2");
conf.set("dfs.blocksize", "64m");
fs = FileSystem.get(new URI("hdfs://hdp-01:9000/"), conf, "root"); } /**
* 从HDFS中下载文件到客户端本地磁盘
* @throws IOException
* @throws IllegalArgumentException
*/
@Test
public void testGet() throws IllegalArgumentException, IOException{
fs.copyToLocalFile(new Path("/hdp20-05.txt"), new Path("f:/"));
fs.close(); } /**
* 在hdfs内部移动文件\修改名称
*/
@Test
public void testRename() throws Exception{
fs.rename(new Path("/install.log"), new Path("/aaa/in.log"));
fs.close(); } /**
* 在hdfs中创建文件夹
*/
@Test
public void testMkdir() throws Exception{
fs.mkdirs(new Path("/xx/yy/zz"));
fs.close();
} /**
* 在hdfs中删除文件或文件夹
*/
@Test
public void testRm() throws Exception{
fs.delete(new Path("/aaa"), true);
fs.close();
} /**
* 查询hdfs指定目录下的文件信息
*/
@Test
public void testLs() throws Exception{
// 只查询文件的信息,不返回文件夹的信息
RemoteIterator<LocatedFileStatus> iter = fs.listFiles(new Path("/"), true);
while(iter.hasNext()){
LocatedFileStatus status = iter.next();
System.out.println("文件全路径:"+status.getPath());
System.out.println("块大小:"+status.getBlockSize());
System.out.println("文件长度:"+status.getLen());
System.out.println("副本数量:"+status.getReplication());
System.out.println("块信息:"+Arrays.toString(status.getBlockLocations())); System.out.println("--------------------------------");
}
fs.close();
} /**
* 查询hdfs指定目录下的文件和文件夹信息
*/
@Test
public void testLs2() throws Exception{
FileStatus[] listStatus = fs.listStatus(new Path("/")); for(FileStatus status:listStatus){
System.out.println("文件全路径:"+status.getPath());
System.out.println(status.isDirectory()?"这是文件夹":"这是文件");
System.out.println("块大小:"+status.getBlockSize());
System.out.println("文件长度:"+status.getLen());
System.out.println("副本数量:"+status.getReplication()); System.out.println("--------------------------------");
}
fs.close();
} }
03 HDFS的客户端操作的更多相关文章
- HDFS的客户端操作
命令行操作: -help 功能:输出这个命令参数手册 -ls 功能:显示目录信息 示例: hadoop fs -ls hdfs://hadoop-serv ...
- day03-hdfs的客户端操作\hdfs的java客户端编程
5.hdfs的客户端操作 客户端的理解 hdfs的客户端有多种形式: 1.网页形式 2.命令行形式 3.客户端在哪里运行,没有约束,只要运行客户端的机器能够跟hdfs集群联网 文件的切块大小和存储的副 ...
- HDFS的Java客户端操作代码(HDFS的查看、创建)
1.HDFS的put上传文件操作的java代码: package Hdfs; import java.io.FileInputStream; import java.io.FileNotFoundEx ...
- Hadoop HDFS的shell(命令行客户端)操作实例
HDFS的shell(命令行客户端)操作实例 3.2 常用命令参数介绍 -help 功能:输出这个命令参数手册 -ls 功能:显示目录信息 示例: hadoop fs ...
- Hadoop JAVA HDFS客户端操作
JAVA HDFS客户端操作 通过API操作HDFS org.apache.logging.log4jlog4j-core2.8.2org.apache.hadoophadoop-common${ha ...
- Hadoop学习(2)-java客户端操作hdfs及secondarynode作用
首先要在windows下解压一个windows版本的hadoop 然后在配置他的环境变量,同时要把hadoop的share目录下的hadoop下的相关jar包拷贝到esclipe 然后Build Pa ...
- 客户端操作 2 HDFS的API操作 3 HDFS的I/O流操作
2 HDFS的API操作 2.1 HDFS文件上传(测试参数优先级) 1.编写源代码 // 文件上传 @Test public void testPut() throws Exception { Co ...
- HDFS的Java操作
实验环境: Windows 10 Eclipse Mars.2 Release (4.5.2) CentOS 7 Hadoop-2.7.3 先决条件: 1) Windows上各环境变量已配置OK. ...
- Hadoop HDFS文件常用操作及注意事项
Hadoop HDFS文件常用操作及注意事项 1.Copy a file from the local file system to HDFS The srcFile variable needs t ...
随机推荐
- fcntl()函数之文件打开状态
比较有用的就两个. 1.获得/设置文件打开状态标志 oldflag=fcntl(fd,F_GETFL); 获得打开文件的状态标志. arg=oldflag|O_APPEND; fcntl(fd,F_S ...
- 如何在Windows服务器上新建一个Powershell.ps1的定时任务
背景: 有一些一次性的Powershell脚本,需要我们每次都手动执行一下,为了简化工作,现在我们可以使用Windows自带的计划任务,进行定时执行. 该教程是在Windows Server 2012 ...
- http请求头缓存实现
转自CSDN ouyang-web之路 原文链接:https://blog.csdn.net/cangqiong_xiamen/article/details/90405555 一.浏览器的缓存 st ...
- NIO详解
目录 NIO 前言 IO与NIO的区别 Buffer(缓冲区) Channel(通道) Charset(字符集) NIO遍历文件 NIO 前言 NIO即New IO,这个库是在JDK1.4中才引入的. ...
- CSS预处理技术
CSS自定义变量 这是一个实验中的标准,后续的具体写法和解析可能会有变动. 与Less|Sass等预处理器不同的是CSS变量带有语义效果,并且不需要额外的编译.因为其名称本身就包含了语义的信息,这使得 ...
- SpringMVC源码剖析2——处理器映射器
1.处理器映射器 HandlerMapping 一句话概括作用: 为 我 们 建 立 起 @RequestMapping 注 解 和 控 制 器 方 法 的 对 应 关 系 . 怎么去查看 第一步: ...
- $(document).ready()和window.onload方法
引用:http://www.jb51.net/article/21628.htm Jquery中$(document).ready()的作用类似于传统JavaScript中的window.onload ...
- 关于angular跳转路由之后不能自动回到顶部的解决方法
Question: angular2 scroll top on router change 当我们在第一个路由滑动到底部当我们点击导航跳转到另一个路由时页面没有回到顶部而是保持上一个路由的滚动位置, ...
- <JZOJ1286>太空电梯
一道简单可爱的dp #include<cstdio> #include<iostream> #include<cstring> #include<algori ...
- JS做深度学习2——导入训练模型
JS做深度学习2--导入训练模型 改进项目 前段时间,我做了个RNN预测金融数据的毕业设计(华尔街),当时TensorFlow.js还没有发布,我不得已使用了keras对数据进行了训练,并且拟合好了不 ...