xpath beautiful pyquery三种解析库
这两天看了一下python常用的三种解析库,写篇随笔,整理一下思路。太菜了,若有错误的地方,欢迎大家随时指正。。。。。。。(come on.......)
爬取网页数据一般会经过 获取信息->提取信息->保存信息 这三个步骤。而解析库的使用,则可以帮助我们快速的提取出我们需要的那被部分信息,免去了写复杂的正则表达式的麻烦。在使用解析库的时候,个人理解也会有三个步骤 建立文档树->搜索文档树->获取属性和文本 。
建立文档树:就是把我们获取到的网页源码利用解析库进行解析,只有这样,后面才能使用这个解析库的方法。
搜索文档树:就是在已经建立的文档树里面,利用标签的属性,搜索出我们需要的那部分信息,比如一个包含一部分网页内容的div标签,一个ul标签等。
获取索性和文本:在上一步的基础上,进一步获取到具体某个标签的文本或属性,比如一个a标签的href属性,title属性,或它的文本。
首先,定义一个html的字符串,用它来模拟已经获取到的网页源码
html = '''
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
xpath解析库:XPath,全称XML Path Language,即XML路径语言,它是一门在XML文档中查找信息的语言。它最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索。
1.建立文档树:在获取到网页源码后,只需要使用etree的HTML方法,就可以把复杂的html建立成 一棵文档树了
from lxml import etree
xpath_tree = etree.HTML(html)
这里首先导入lxml库的etree模块,然后声明了一段HTML文本,调用HTML类进行初始化,这样就成功构造了一个XPath解析对象。可以使用type查看一下xpath_tree的类型,是这样的 <class 'lxml.etree._Element'>
2.搜索文档树:先看一下xpath几个常用的规则
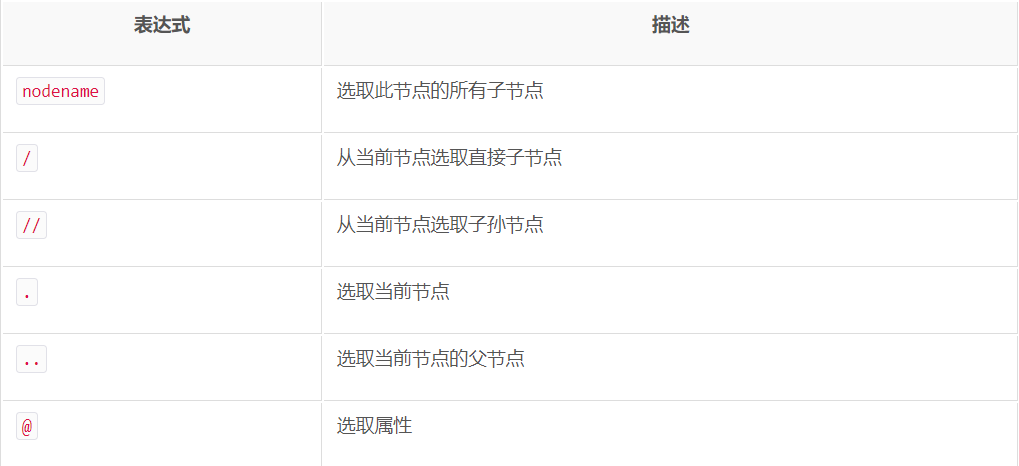
(1)从整个文档树中搜索标签:一般会用//开头的XPath规则来选取所有符合要求的节点。这里以前面的HTML文本为例。例如搜索 ul 标签
xpath_tree = etree.HTML(html)
result = xpath_tree.xpath('ul')
print(result)
print(type(result))
print(type(result[0])) 输出结果如下:
[<Element ul at 0x2322b7e8608>, <Element ul at 0x2322b7e8648>]
<class 'list'>
<class 'lxml.etree._Element'>
上面第二行代码表示从整个文档树中搜索出所有的ul标签,可以看到,返回结果是一个列表,里面的每个元素都是lxml.etree._Element类型,当然,也可以对这个列表进行一个遍历,然后对每个lxml.etree._Element对象进行操作。
(2)搜索当前节点的子节点:比如,找到每一个ul标签里面的 li 标签:
xpath_tree = etree.HTML(html)
result = xpath_tree.xpath('//ul')
for r in result:
li_list = r.xpath('./li')
print(li_list) 输出结果如下:
[<Element li at 0x23433127748>, <Element li at 0x23433127788>, <Element li at 0x23433127a88>, <Element li at 0x23433127988>, <Element li at 0x23433127ac8>]
[<Element li at 0x23433127cc8>, <Element li at 0x23433127d08>, <Element li at 0x23433127d48>, <Element li at 0x23433127d88>, <Element li at 0x23433127dc8>]
第四行代码表示,选取当前的这个ul标签,并获取到它里面的所有li标签。
(3)根据属性过滤:如果你需要根据标签的属性进行一个过滤,则可以这样来做
xpath_tree = etree.HTML(html)
result = xpath_tree.xpath('//ul')
for r in result:
li_list = r.xpath('./li[@class="item-0"]')
print(li_list) 输出结果如下:
[<Element li at 0x15c436695c8>, <Element li at 0x15c436698c8>]
[<Element li at 0x15c43669988>, <Element li at 0x15c436699c8>]
与之前的代码相比,旨在第四行的后面加了 [@class="item-0"] ,它表示找到当前ul标签下所有class属性值为item-0的li标签,当然,也可以在整个文档树搜索某个标签时,在标签后面加上某个属性,进行过滤,下面例子中有用到
(4)获取文本:获取具体某个标签的文本内容
xpath_tree = etree.HTML(html)
result = xpath_tree.xpath('//ul[@class="list"]')
for r in result:
li_list = r.xpath('./li[@class="item-0"]')
for li in li_list:
print(li.xpath('./text()')) 输出结果如下:
['first item']
[]
['first item']
[]
首先,在第二行的ul标签后面加了属性过滤,但因为两个ul标签的class属性值都是list,所以结果没加之前是一样的。然后又加了一个for循环,用来获取列表里面每一个元素的文本,因为第二个li标签里面没有文本内容,所以是空
(5)获取属性:获取具体某个标签的某个属性内容
xpath_tree = etree.HTML(html)
result = xpath_tree.xpath('//ul[@class="list"]')
for r in result:
li_list = r.xpath('./li[@class="item-0"]')
for li in li_list:
print(li.xpath('./@class')) 输出结果如下:
['item-0']
['item-0']
['item-0']
['item-0']
把第六行的text()方法换成@符号,并在后面加上想要的属性,就获取到了该属性的属性值。
这是xpath这个解析库基本的使用方法,也有一些没说到的地方,大家可以看一下静谧大佬的文章。https://cuiqingcai.com/5545.html
另外两个解析库,放在后面两篇随笔里面
beautifulsoup解析库:https://www.cnblogs.com/liangxiyang/p/11302525.html
pyquery解析库:https://www.cnblogs.com/liangxiyang/p/11303142.html
*************************不积跬步,无以至千里。*************************
xpath beautiful pyquery三种解析库的更多相关文章
- (最全)Xpath、Beautiful Soup、Pyquery三种解析库解析html 功能概括
一.Xpath 解析 xpath:是一种在XMl.html文档中查找信息的语言,利用了lxml库对HTML解析获取数据. Xpath常用规则: nodename :选取此节点的所有子节点 // : ...
- Qt中三种解析xml的方式
在下面的随笔中,我会根据xml的结构,给出Qt中解析这个xml的三种方式的代码.虽然,这个代码时通过调用Qt的函数实现的,但是,很多开源的C++解析xml的库,甚至很多其他语言解析xml的库,都和下面 ...
- JSON的三种解析方式
一.什么是JSON? JSON是一种取代XML的数据结构,和xml相比,它更小巧但描述能力却不差,由于它的小巧所以网络传输数据将减少更多流量从而加快速度. JSON就是一串字符串 只不过元素会使用特定 ...
- Android平台中实现对XML的三种解析方式
本文介绍在Android平台中实现对XML的三种解析方式. XML在各种开发中都广泛应用,Android也不例外.作为承载数据的一个重要角色,如何读写XML成为Android开发中一项重要的技能. 在 ...
- 爬虫的三种解析方式(正则解析, xpath解析, bs4解析)
一 : 正则解析 : 常用正则回顾: 单字符: . : 除换行符以外的所有字符 [] : [aoe] [a-w] 匹配集合中任意一个字符 \d : 数字 [0-9] \D : 非数字 \w : 非数字 ...
- 【Android学习】XML文本的三种解析方式(通过搭建本地的Web项目提供XML文件)
XML为一种可扩展的标记语言,是一种简单的数据存储语言,使用一系列简单的标记来描述. 一.SAX解析 即Simple API for XML,以事件的形式通知程序,对Xml进行解析. 1.首先在Web ...
- windows phone中三种解析XML的方法
需求如下, 项目需要将一段xml字符串中的信息提取出来 <?xml version=""1.0"" encoding=""UTF-8& ...
- python爬虫之数据的三种解析方式
一.正则解析 单字符: . : 除换行以外所有字符 [] :[aoe] [a-w] 匹配集合中任意一个字符 \d :数字 [0-9] \D : 非数字 \w :数字.字母.下划线.中文 \W : 非\ ...
- Python_XML的三种解析方法
什么是XML? XML 指可扩展标记语言(eXtensible Markup Language). XML 被设计用来传输和存储数据. XML是一套定义语义标记的规则,这些标记将文档分成许多部件并对这 ...
随机推荐
- wireshark数据包分析实战 第一章
1,数据包分析工具:tcpdump.wireshark.前者是命令行的,后者是图形界面的. 分析过程:收集数据.转换数据(二进制数据转换为可读形式).分析数据.tcpdump不提供分析数据,只将最原始 ...
- Codeforces Gym100502A:Amanda Lounges(DFS染色)
http://codeforces.com/gym/100502/attachments 题意:有n个地点,m条边,每条边有一个边权,0代表两个顶点都染成白色,2代表两个顶点都染成黑色,1代表两个顶点 ...
- QT知识整理
1.connect函数的SIGNAL可以是按键.定时器.其他对象的信号.如果是其他对象的信号,对象必须要在当前类中实例化. 2.Qt数据类型转换 1)int转QStringint a=10;QStri ...
- 自己实现定制自己的专属java锁,来高效规避不稳定的第三方
java juc 包下面已经提供了很多并发锁工具供我们使用,但在日常开发中,为了各种原因我们总是会用多线程来并发处理一些问题,然而并不是所有的场景都可以使用juc 或者java本身提供的锁来方便的帮助 ...
- 前端从零开始学习Graphql
学习本姿势需要电脑装有node,vue-cli相关环境,以及要有node,express,koa,vue相关基础 本文相关demo的github地址: node服务:https://github.co ...
- C++学习书籍推荐《Exceptional C++(英文)》下载
百度云及其他网盘下载地址:点我 作者简介 Herb Sutter is the author of three highly acclaimed books, Exceptional C++ Styl ...
- ecshop数据库结构和字段介绍(转载)
ecs_account_log:账户变动日志(注册用户充值.支付等记录信息)字段 类型 Null 默认 字段说明log_id mediumint(8) 否 无 日志IDuser_id mediumin ...
- Go语言设计模式汇总
目录 设计模式背景和起源 设计模式是什么 Go语言模式分类 个人观点 Go语言从面世就受到了业界的普遍关注,随着区块链的火热Go语言的地位也急速蹿升,为了让读者对设计模式在Go语言中有一个初步的了解和 ...
- ZIP:ZipFile
ZipFile: /* 此类用于从 ZIP 文件读取条目 */ ZipFile(File file) :打开供阅读的 ZIP 文件,由指定的 File 对象给出. ZipFile(File file, ...
- 深入理解Java虚拟机一 阅读笔记
xl_echo编辑整理.欢迎添加echo微信(微信号:t2421499075)交流学习. 百战不败,依不自称常胜,百败不颓,依能奋力前行.--这才是真正的堪称强大!! --- > 以下内容摘抄自 ...