爬虫(七):爬取猫眼电影top100
一:分析网站
目标站和目标数据
目标地址:http://maoyan.com/board/4?offset=20
目标数据:目标地址页面的电影列表,包括电影名,电影图片,主演,上映日期以及评分。
二:上代码
(1):导入相应的包
import requests
from requests.exceptions import RequestException # 处理请求异常
import re
import pymysql
import json
from multiprocessing import Pool
(2):分析网页
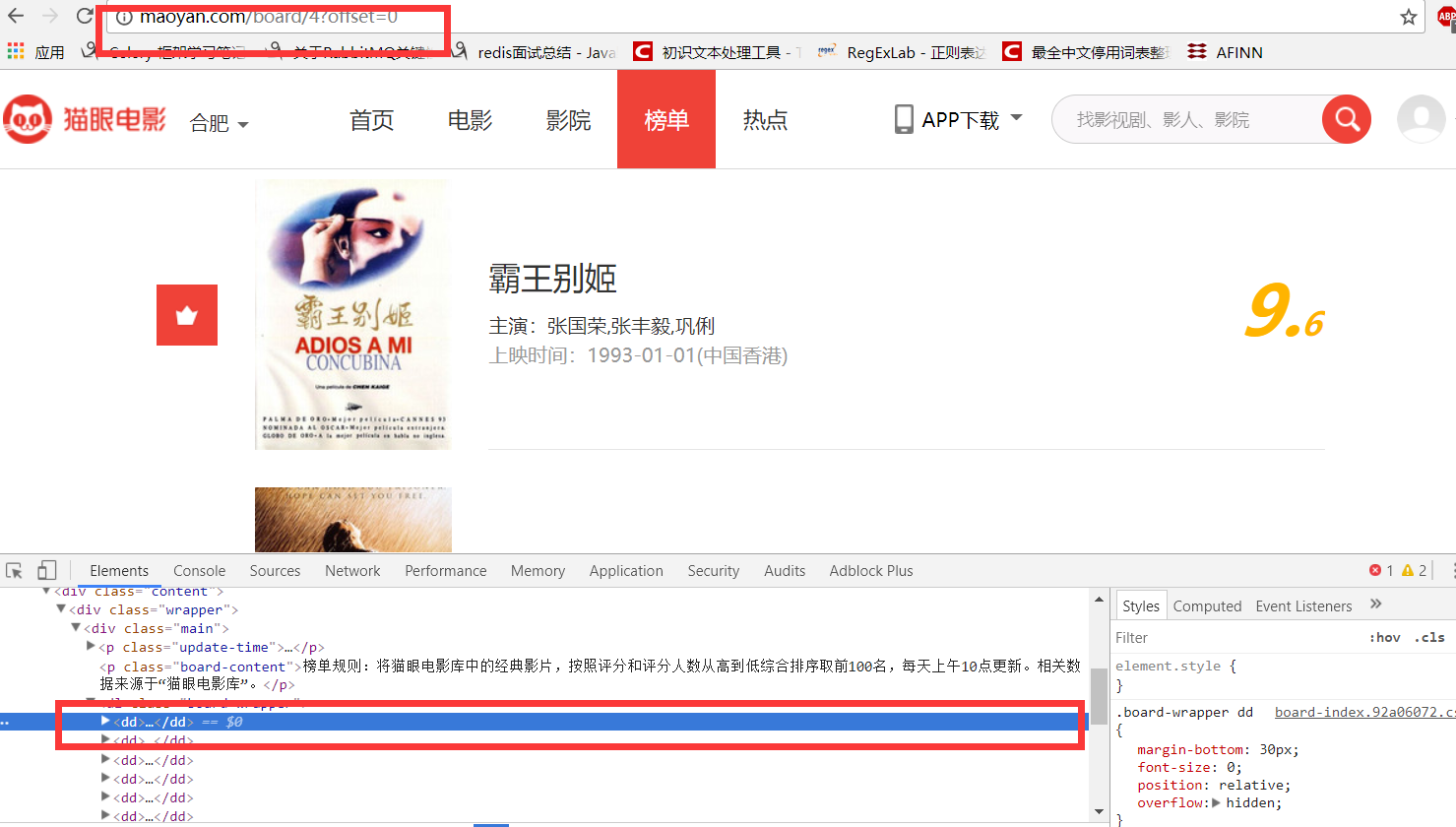
通过检查发现需要的内容位于网页中的<dd>标签内。通过翻页发现url中的参数的变化。
(3):获取html网页
# 获取一页的数据
def get_one_page(url):
# requests会产生异常
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36',
}
try:
response = requests.get(url, headers=headers)
if response.status_code == 200: # 状态码是200表示成功
return response.text
else:
return None
except RequestException:
return None
(4):通过正则提取需要的信息 --》正则表达式详情
# 解析网页内容
def parse_one_page(html):
pattern = re.compile(
'<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?class="name"><a.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>',
re.S) # re.S可以匹配任意字符包括换行
items = re.findall(pattern, html) # 将括号中的内容提取出来
for item in items:
yield { # 构造一个生成器
'index': item[0].strip(),
'title': item[2].strip(),
'actor': item[3].strip()[3:],
'score': ''.join([item[5].strip(), item[6].strip()]),
'pub_time': item[4].strip()[5:],
'img_url': item[1].strip(),
}
(5):将获取的内容存入mysql数据库
# 连接数据库,首先要在本地创建好数据库
def commit_to_sql(dic):
conn = pymysql.connect(host='localhost', port=3306, user='mydb', passwd='', db='maoyantop100',
charset='utf8')
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) # 设置游标的数据类型为字典
sql = '''insert into movies_top_100(mid,title,actor,score,pub_time,img_url) values("%s","%s","%s","%s","%s","%s")''' % (
dic['index'], dic['title'], dic['actor'], dic['score'], dic['pub_time'], dic['img_url'],)
cursor.execute(sql) # 执行sql语句并返回受影响的行数
# # 提交
conn.commit()
# 关闭游标
cursor.close()
# 关闭连接
conn.close()
(6):主程序及运行
def main(url):
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
commit_to_sql(item) if __name__ == '__main__':
urls = ['http://maoyan.com/board/4?offset={}'.format(i) for i in range(0, 100, 10)]
# 使用多进程
pool = Pool()
pool.map(main, urls)
(7):最后的结果
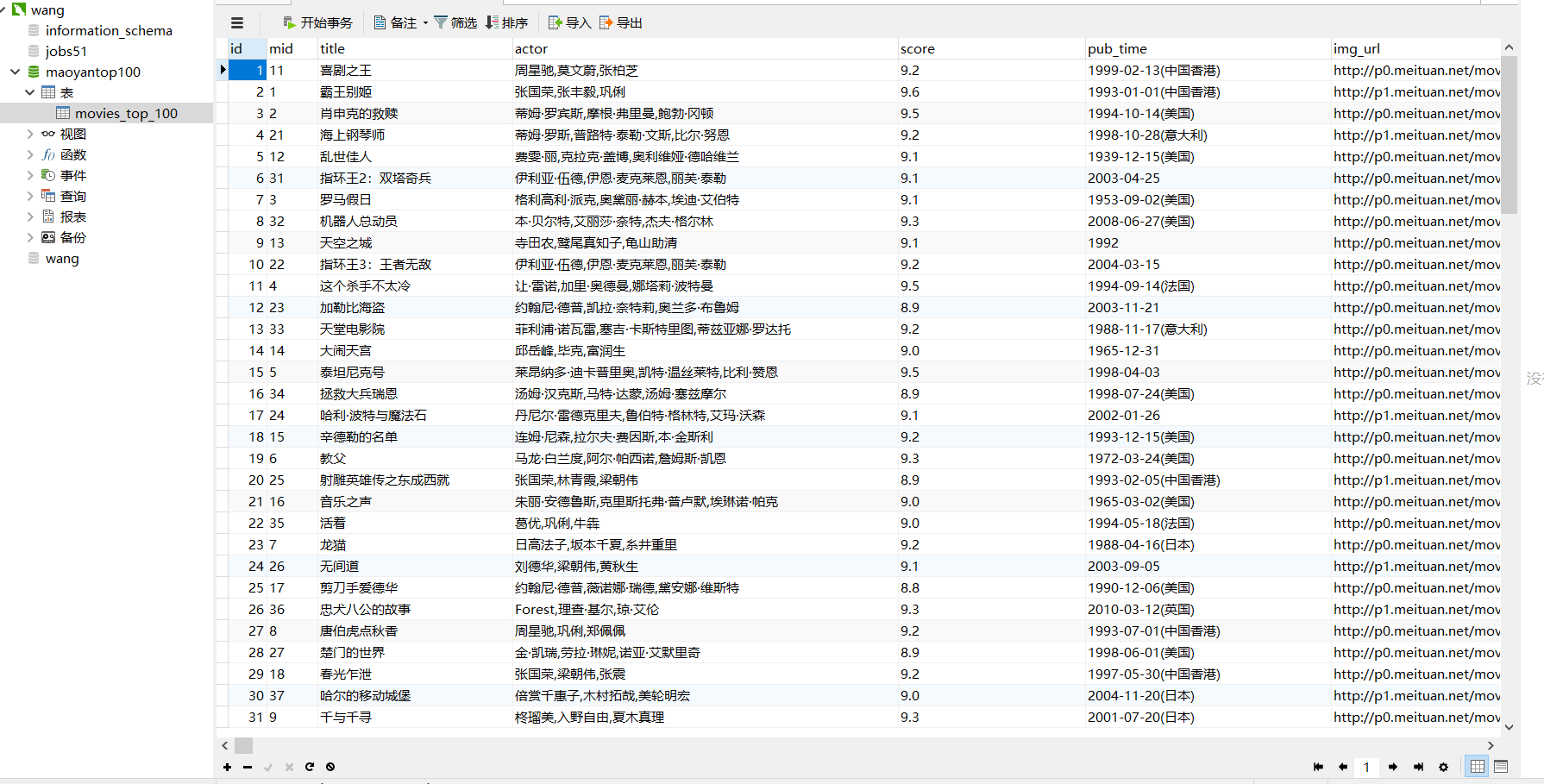
完整代码:
# -*- coding: utf-8 -*-
# @Author : FELIX
# @Date : 2018/4/4 9:29 import requests
from requests.exceptions import RequestException
import re
import pymysql
import json
from multiprocessing import Pool # 连接数据库
def commit_to_sql(dic):
conn = pymysql.connect(host='localhost', port=3306, user='wang', passwd='', db='maoyantop100',
charset='utf8')
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) # 设置游标的数据类型为字典
sql = '''insert into movies_top_100(mid,title,actor,score,pub_time,img_url) values("%s","%s","%s","%s","%s","%s")''' % (
dic['index'], dic['title'], dic['actor'], dic['score'], dic['pub_time'], dic['img_url'],)
cursor.execute(sql) # 执行sql语句并返回受影响的行数
# # 提交
conn.commit()
# 关闭游标
cursor.close()
# 关闭连接
conn.close() # 获取一页的数据
def get_one_page(url):
# requests会产生异常
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36',
}
try:
response = requests.get(url, headers=headers)
if response.status_code == 200: # 状态码是200表示成功
return response.text
else:
return None
except RequestException:
return None # 解析网页内容
def parse_one_page(html):
pattern = re.compile(
'<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?class="name"><a.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>',
re.S) # re.S可以匹配任意字符包括换行
items = re.findall(pattern, html) # 将括号中的内容提取出来
for item in items:
yield { # 构造一个生成器
'index': item[0].strip(),
'title': item[2].strip(),
'actor': item[3].strip()[3:],
'score': ''.join([item[5].strip(), item[6].strip()]),
'pub_time': item[4].strip()[5:],
'img_url': item[1].strip(),
}
# print(items) def write_to_file(content):
with open('result.txt', 'a', encoding='utf8')as f:
f.write(json.dumps(content, ensure_ascii=False) + '\n') ii = 0 def main(url):
html = get_one_page(url)
for item in parse_one_page(html):
global ii
print(ii, item)
ii = ii + 1
commit_to_sql(item)
write_to_file(item) # print(html) if __name__ == '__main__':
urls = ['http://maoyan.com/board/4?offset={}'.format(i) for i in range(0, 100, 10)]
# 使用多进程
pool = Pool()
pool.map(main, urls)
爬虫(七):爬取猫眼电影top100的更多相关文章
- Python爬虫项目--爬取猫眼电影Top100榜
本次抓取猫眼电影Top100榜所用到的知识点: 1. python requests库 2. 正则表达式 3. csv模块 4. 多进程 正文 目标站点分析 通过对目标站点的分析, 来确定网页结构, ...
- 爬虫系列(1)-----python爬取猫眼电影top100榜
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天在整理代码时,整理了一下之前自己学习爬虫的一些代码,今天先上一个简单的例子,手把手教你入门Python爬虫,爬取 ...
- 50 行代码教你爬取猫眼电影 TOP100 榜所有信息
对于Python初学者来说,爬虫技能是应该是最好入门,也是最能够有让自己有成就感的,今天,恋习Python的手把手系列,手把手教你入门Python爬虫,爬取猫眼电影TOP100榜信息,将涉及到基础爬虫 ...
- PYTHON 爬虫笔记八:利用Requests+正则表达式爬取猫眼电影top100(实战项目一)
利用Requests+正则表达式爬取猫眼电影top100 目标站点分析 流程框架 爬虫实战 使用requests库获取top100首页: import requests def get_one_pag ...
- # [爬虫Demo] pyquery+csv爬取猫眼电影top100
目录 [爬虫Demo] pyquery+csv爬取猫眼电影top100 站点分析 代码君 [爬虫Demo] pyquery+csv爬取猫眼电影top100 站点分析 https://maoyan.co ...
- 40行代码爬取猫眼电影TOP100榜所有信息
主要内容: 一.基础爬虫框架的三大模块 二.完整代码解析及效果展示 1️⃣ 基础爬虫框架的三大模块 1.HTML下载器:利用requests模块下载HTML网页. 2.HTML解析器:利用re正则表 ...
- 用requests库爬取猫眼电影Top100
这里需要注意一下,在爬取猫眼电影Top100时,网站设置了反爬虫机制,因此需要在requests库的get方法中添加headers,伪装成浏览器进行爬取 import requests from re ...
- python 爬取猫眼电影top100数据
最近有爬虫相关的需求,所以上B站找了个视频(链接在文末)看了一下,做了一个小程序出来,大体上没有修改,只是在最后的存储上,由txt换成了excel. 简要需求:爬虫爬取 猫眼电影TOP100榜单 数据 ...
- # 爬虫连载系列(1)--爬取猫眼电影Top100
前言 学习python有一段时间了,之前一直忙于学习数据分析,耽搁了原本计划的博客更新.趁着这段空闲时间,打算开始更新一个爬虫系列.内容大致包括:使用正则表达式.xpath.BeautifulSoup ...
- 爬虫--requests爬取猫眼电影排行榜
'''目标:使用requests分页爬取猫眼电影中榜单栏目中TOP100榜的所有电影信息,并将信息写入文件URL地址:http://maoyan.com/board/4 其中参数offset表示其实条 ...
随机推荐
- 深夜扒一扒Android的发展史
说道,Android的发展史,我们就不得不先来了解一下手机的发展史 Android之前的时代 1831年英国的法拉第发现了电磁感应现象,麦克斯韦进一步用数学公式阐述了法拉第等人的研究成果,并把电磁感应 ...
- Java Embeded 包 与各个架构之间的关系
Oracle Java Embedded Suite 7.0 for Linux x86 V37917-01.zip Oracle Java Embedded Suite ...
- Spring Cloud Alibaba学习笔记(12) - 使用Spring Cloud Stream 构建消息驱动微服务
什么是Spring Cloud Stream 一个用于构建消息驱动的微服务的框架 应用程序通过 inputs 或者 outputs 来与 Spring Cloud Stream 中binder 交互, ...
- Python之数据处理-2
一.数据处理其实是一个很麻烦的事情. 在一个样本中存在特征数据(比如:人(身高.体重.出生年月.年龄.职业.收入...))当数据的特征太多或者特征权重小或者特征部分满足的时候. 这个时候就要进行数据的 ...
- JavaScript 基础(数据类型、函数、流程控制、对象)
一.JavaScript概述 1.1 JavaScript的历史 1992年Nombas开发出C-minus-minus(C--)的嵌入式脚本语言(最初绑定在CEnvi软件中).后将其改名Script ...
- 有用的vscode快捷键大全+自定义快捷键
VS Code是前端的一个比较好用的代码编辑器,但是我们不能老是局限于鼠标操作呀,有时候很不方便,所以呢,快捷键大全来啦,有的可能会和你们电脑自带的快捷键冲突呢,这时候,你自己设置一下就好了呀 一.v ...
- NSIP
1. 第一章 信息安全概述 信息:信息是有意义的数据,具有一定的价值,是一种适当保护的资产,数据是是客观事务属性的记录,是信息的具体表现形式,数据经过加工处理之后 就是信息,而信息需要经过数字处理转换 ...
- Java程序员完美设置,Mac编程指南
重装了不知道多少次Windows,Linux发行版换来换去总是觉得不满意,终于下定决心在年头买了人生中第一台Mac. 为什么是Mac 现在的移动端.服务器端跑的大多数都是Unix系统,熟悉Un ...
- k8s的Pod状态和生命周期管理
Pod状态和生命周期管理 一.什么是Pod? 二.Pod中如何管理多个容器? 三.使用Pod 四.Pod的持久性和终止 五.Pause容器 六.init容器 七.Pod的生命周期 (1)Pod p ...
- Caused by: java.lang.ClassNotFoundException: org.fusesource.jansi.WindowsAnsiOutputStream
08:23:18,995 |-INFO in ch.qos.logback.core.joran.action.AppenderAction - About to instantiate append ...