二十四 Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图
1、基本概念

2、反爬虫的目的

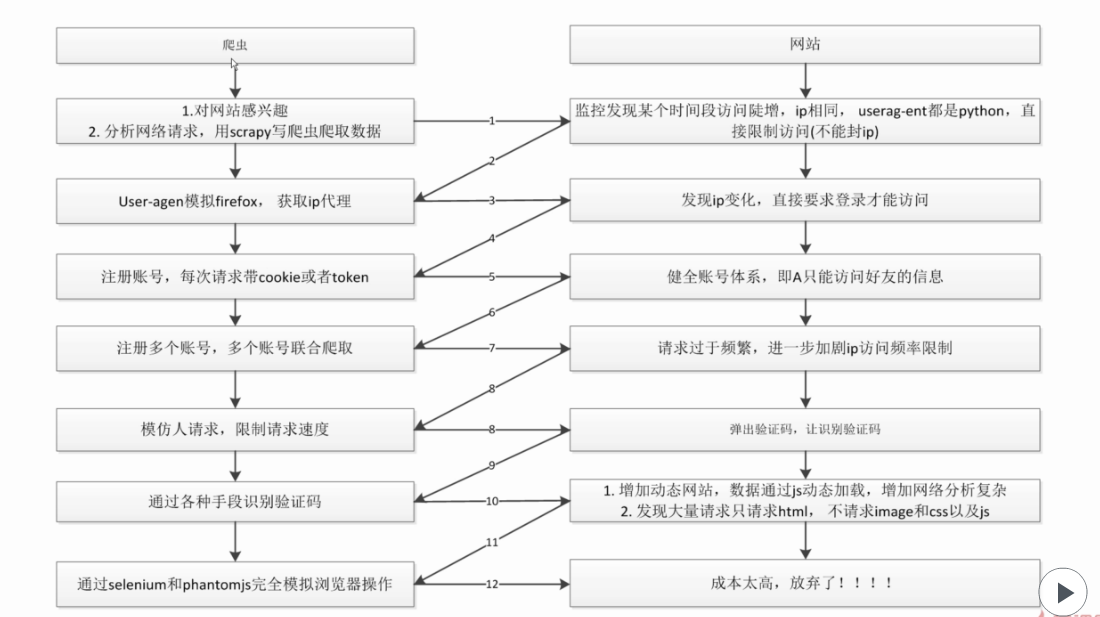
3、爬虫和反爬的对抗过程以及策略
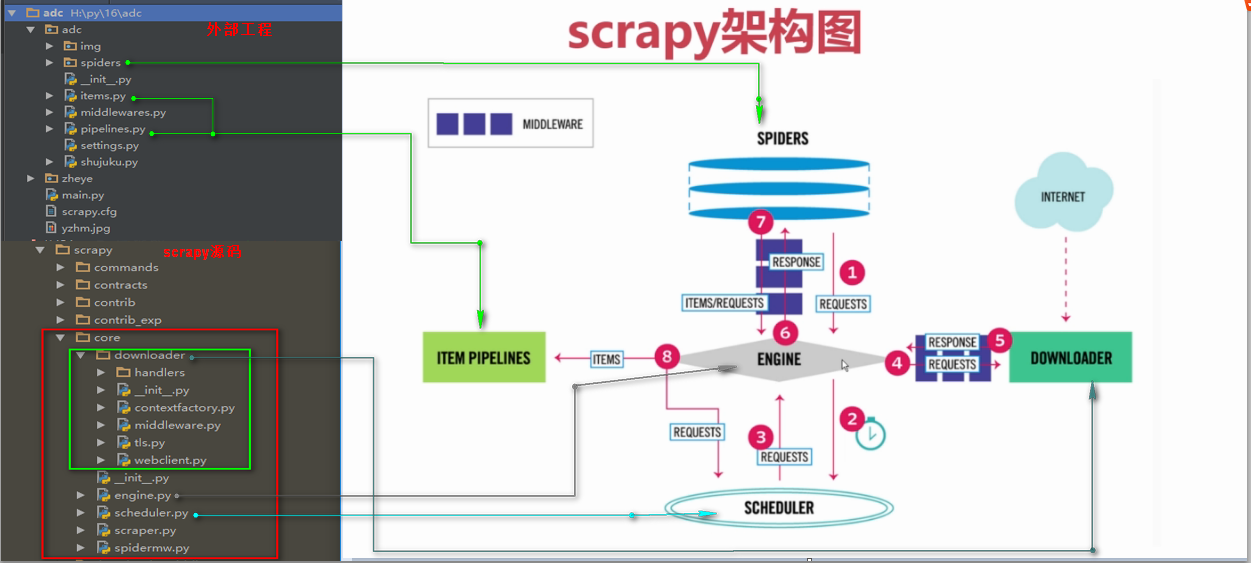
scrapy架构源码分析图
二十四 Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图的更多相关文章
- 第三百四十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图
第三百四十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图 1.基本概念 2.反爬虫的目的 3.爬虫和反爬的对抗过程以及策略 scra ...
- 第三百四十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫数据保存
第三百四十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫数据保存 注意:数据保存的操作都是在pipelines.py文件里操作的 将数据保存为json文件 spider是一个信号检测 ...
- 二十四. Python基础(24)--封装
二十四. Python基础(24)--封装 ● 知识结构 ● 类属性和__slots__属性 class Student(object): grade = 3 # 也可以写在__slots ...
- python3.4学习笔记(二十四) Python pycharm window安装redis MySQL-python相关方法
python3.4学习笔记(二十四) Python pycharm window安装redis MySQL-python相关方法window安装redis,下载Redis的压缩包https://git ...
- 四十四 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
1.elasticsearch(搜索引擎)的查询 elasticsearch是功能非常强大的搜索引擎,使用它的目的就是为了快速的查询到需要的数据 查询分类: 基本查询:使用elasticsearch内 ...
- 二十六 Python分布式爬虫打造搜索引擎Scrapy精讲—通过downloadmiddleware中间件全局随机更换user-agent浏览器用户代理
downloadmiddleware介绍中间件是一个框架,可以连接到请求/响应处理中.这是一种很轻的.低层次的系统,可以改变Scrapy的请求和回应.也就是在Requests请求和Response响应 ...
- 二十九 Python分布式爬虫打造搜索引擎Scrapy精讲—selenium模块是一个python操作浏览器软件的一个模块,可以实现js动态网页请求
selenium模块 selenium模块为第三方模块需要安装,selenium模块是一个操作各种浏览器对应软件的api接口模块 selenium模块是一个操作各种浏览器对应软件的api接口模块,所以 ...
- 二十八 Python分布式爬虫打造搜索引擎Scrapy精讲—cookie禁用、自动限速、自定义spider的settings,对抗反爬机制
cookie禁用 就是在Scrapy的配置文件settings.py里禁用掉cookie禁用,可以防止被通过cookie禁用识别到是爬虫,注意,只适用于不需要登录的网页,cookie禁用后是无法登录的 ...
- 二十五 Python分布式爬虫打造搜索引擎Scrapy精讲—Requests请求和Response响应介绍
Requests请求 Requests请求就是我们在爬虫文件写的Requests()方法,也就是提交一个请求地址,Requests请求是我们自定义的 Requests()方法提交一个请求 参数: ur ...
随机推荐
- HDevelop数据类型
*图形类型*图像Hwnd:=3600read_image(Image, 'fabrik')disp_obj(Image, Hwnd)*region 区域gen_rectangle1(Rectangle ...
- java的TimeUtils或者DateUtils的编写心得
一.几种常见的日期和时间类介绍 介绍时间工具类不可避免必须要去触碰几个常见的日期和时间类,所以就简单介绍一下. 1.jdk1.8之前的日期时间类 a.Date类 我们可以通过new的方式生成一个Dat ...
- maven install jdk版本自动降为1.7
开发过程中遇到了一个奇怪的现象. IDEA中所有的设置都改成了1.8,但是在执行maven install时却自动降为1.7,报错提示: [ERROR] Failed to execute goal ...
- web前端基础——初识CSS
1 CSS概要 CSS(Cascading Style Sheets)称为层叠样式表,用于美化页面(单纯HTML写的页面只是网页框架和内容的组合,相当于赤裸的人,而CSS则是给赤裸的人穿上华丽的外衣) ...
- HTTP服务器(3)
功能完整的HTTP服务器 导语 这个一个功能完备的HTTP服务器.它可以提供一个完整的文档输,包括图像,applet,HTML文件,文本文件.它与SingleFileHttpServer非常相似,只不 ...
- iOS开发之AFNetworking网络编程
众所周知,苹果搞的一套框架NSContention发送请求与接收请求的方式十分繁琐.操作起来很不方便.不仅要做区分各种请求设置各种不同的参数,而且还要经常在多线程里操作,同时还要对请求与返回的数据做各 ...
- weblogic控制台部署web项目图解
图解网址:http://jingyan.baidu.com/article/c74d6000650d470f6b595d72.html
- 深入探讨JS中的数组排序函数sort()和reverse()
最近在研究Javascript发现了其中一些比较灵异的事情.有点让人感到无语比如: alert(typeof( NaN == NaN));//结果为假. alert(typeof( NaN != Na ...
- Cloudera Manager安装之时间服务器和时间客户端(二)
福利 => 每天都推送 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 Java全栈大联盟 ...
- 33c3-pwn500-recurse
Recurse 好记性不如烂笔头.当时没有记录,现在趁着有时间简单写一写,为以后留备份. 这个题目当时并没有队伍做出来,赛后作者发布了题目的源码和解答.看了之后发现是一个UAF漏洞,不过漏洞很不好找. ...