13、Flask实战第13天:SQLAlchemy操作MySQL数据库
安装MySQL
在MySQL官网下载win版MySQL

双击运行
后面根据提示设置密码然后启动即可,这里我设置的密码是:123456
我们可以通过Navicat客户端工具连接上MySQL
address: 127.0.0.1
port: 3306
username: root
password: 123456
连接信息
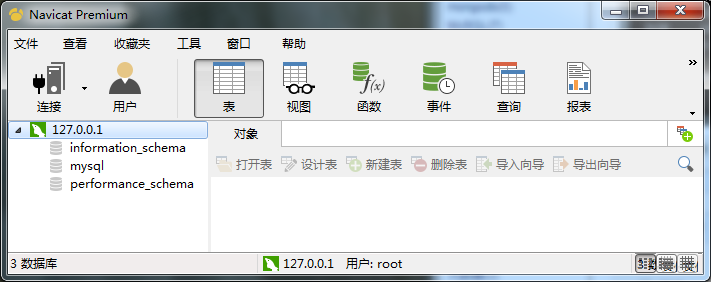
创建一个数据库heboan,字符集设置为utf8
安装pymysql和sqlalchemy
#进入cmd窗口,然后进入虚拟环境进行安装
workon flask-env
pip install pymysql
pip install sqlalchemy
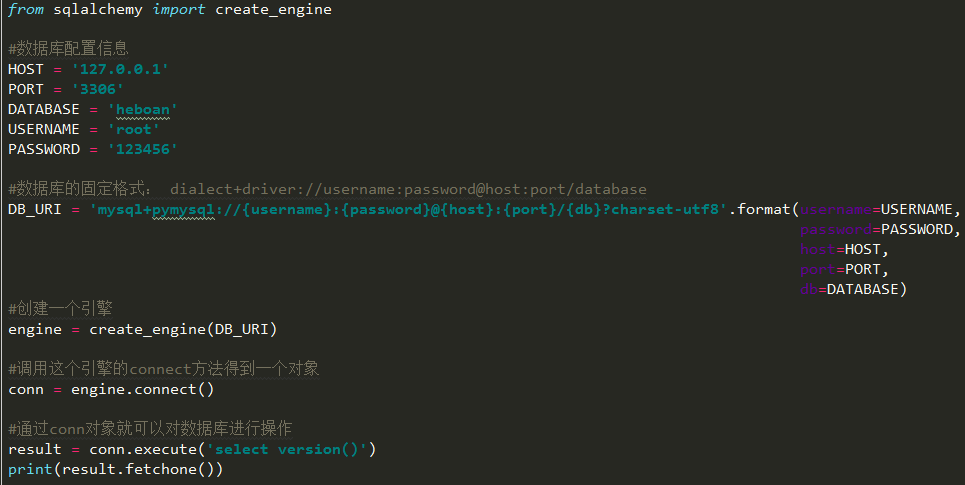
使用SQLAlchemy连接数据库
在项目目下创建一个文件learn_sql.py,然后运行此文件
ORM介绍
随着项目越来越大,采用原生SQL的方式在代码中会出现大量的SQL语句,那么问题就出现:
1、SQL语句重复利用率不高,越复杂的SQL语句条件越多,代码越长;会出现很多相近的SQL语句
2、很多SQL语句是在业务逻辑中拼出来的,如果数据需要更改,就要去修改这些逻辑,比较容易出错
3、写SQL时容易忽略web安全问题,给未来造成隐患,比如sql注入
ORM,全称Object Relationship Mapping,中文名叫做对象关系映射,通过ORM我们可以使用类的方式去操作数据库,而不用再写原生的SQL语句。通过表映射成类,把行作实例,把字段作属性。ORM在执行对象操作的时候最终还是会把对应的操作转换为数据库原生语句。使用ORM有许多优点:
1、易用性:使用ORM做数据库的开发可以有效的减少重复SQL语句的概率,写出来的模型也更加直观、清晰
2、性能损耗小:ORM转换成底层数据库操作指令确实会有一些开销,但从实际情况来看,这种性能损耗不足5%
3、设计灵活:可以轻松写出复杂的查询
4、可以移植性:SQLAlchemy封装了底层的数据库实现,支持多个关系型数据库引擎,可以轻松的切换数据库
定义ORM模型并将其映射到数据库中(创建表)
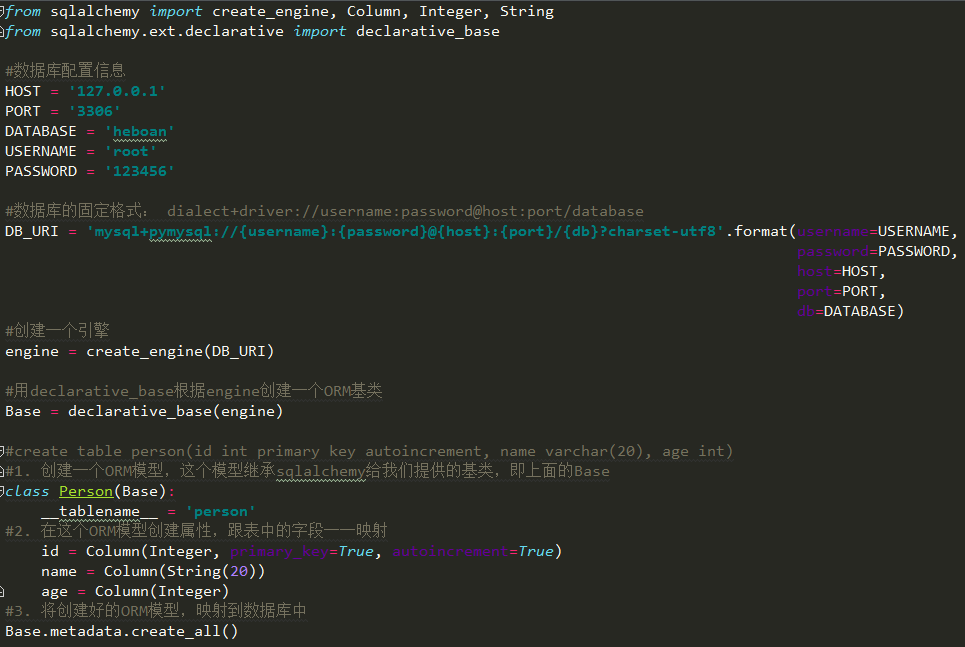
运行之后,查看数据库,person表已经创建好了
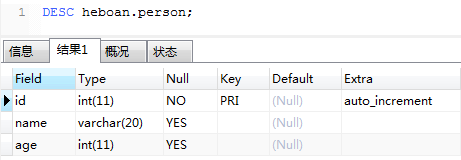
注意:一旦使用Base.metadata.create_all()将模型映射到数据库后,即使改变了模型的字段,也不会重新映射了
SQLAlchemy对数据库增删改查操作
SQLAlchemy使用ORM对数据库操作需要构建一个session对象,所有操作都必须通过中国session会话对象来实现
from sqlalchemy.orm import sessionmaker
... session = sessionmaker(engine)()
说明:
sessionmasker和上面的declarative_base一样,把engine作为参数实例化出一个对象
Session = sessionmaker(engine)
但是这样还不能直接使用Session,我们需要调用Session,我们知道直接实例.()这样运行直接上会调用__call__()方法
session = Session()
为了简介,我们就可以写成这样
session = sessionmaker(engine)()
def add_data():
p = Person(name='heboan', age=18)
session.add(p)
session.commit() add_data() #一次添加多条数据
def add_data():
p1 = Person(name='user1', age=21)
p2 = Person(name='user2', age=22)
session.add_all([p1,p2])
session.commit() add_data()
增
def search_data():
# 查找某个模型表的所有数据
# all_person = session.query(Person).all()
# for p in all_person:
# print(p) # 使用filter_by作条件查询
# all_person = session.query(Person).filter_by(name='heboan').all()
# for p in all_person:
# print(p) # 使用filter作条件查询
# all_person = session.query(Person).filter(Person.name=='heboan').all()
# for p in all_person:
# print(p) # 使用get方法查找,get方法是根据主键ID来查找的,只会返回一条数据或None
person = session.query(Person).get(1)
print(person) search_data()
查
def update_data():
# 先找出要改的对象
person = session.query(Person).first()
# 直接改属性
person.age = 20
session.commit() update_data()
改
def delete_data():
persons = session.query(Person).filter_by(name='heboan')
for p in persons:
session.delete(p)
session.commit() delete_data()
删
SQLAlchemy属性常用数据类型
default: 默认值
nullable: 是否可空
primary_key: 是否为主键
unique: 是否唯一
autoincrement: 是否自增长
name: 该属性再数据库中的字段映射
onupdate: 当数据更新时会自动使用这个属性
比如update_time = Colum(DateTime, onupdate=datetime.now, default=datetime.now)
Colum常用属性
Integer: 整形
Float: 浮点型,后面只会保留4位小数,会有精度丢失问题,占据32位
Double: 双精度浮点类型,占据64位,也会存在精度丢失问题
DECIMAL: 定点类型,解决浮点类型精度丢失问题;如果精度要求高,比如金钱,则适合用此类型
Boolean: 传递True/False进行
enum: 枚举类型
Date: 传递datetime.date()进去
Datetime: 传递datetime.datetme()进去
Time: 传递datetime.time()进去
String: 字符类型,使用时需要指定长度,区别于Text类型
Text: 文本类型,一般可以存储6w多个字符
LONGTEXT: 长文本类型
from sqlalchemy.dialects.mysql import LONGTEXT
因为LONGTEXT只在MySQL数据库中存在
常用数据类型
...
from sqlalchemy import Column, Integer, String, Enum, Date, Float, DECIMAL, Text, Boolean, DateTime
import datetime
... class User(Base):
__tablename__ = 'user' id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(String(50), unique=True, nullable=False)
email = Column(String(100), unique=True, nullable=False)
gender = Column(Enum('m', 'f'), default='m')
birthday = Column(Date)
height = Column(Float)
wages = Column(DECIMAL(10,4)) #10表示10个阿拉伯数字,4代表4位小数,如100000.1234
introduction = Column(Text)
is_delete = Column(Boolean, default=False)
update_time = Column(DateTime, default=datetime.datetime.now, onupdate=datetime.datetime.now) Base.metadata.create_all() session = sessionmaker(engine)() user = User()
user.username = 'heboan'
user.email = 'love@heboan.com'
user.gender = 'm'
user.birthday = datetime.date(2000, 12, 12)
user.height = 1.72
user.wages = 200000.1234
user.introduction = 'hello, my name is heboan....' session.add(user)
session.commit()
示例

query函数可查询的数据
为了方便演示,我先建一个Student表,然后写入10条数据
...
import random ...
class Student(Base):
__tablename__ = 'student'
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(50), nullable=False)
score = Column(Integer, nullable=False) def __repr__(self):
return '<Student-id:{},name:{},score:{}>'.format(self.id,self.name,self.score) Base.metadata.create_all()
session = sessionmaker(engine)() for i in range(1, 11):
student = Student(name='user{}'.format(i), score=random.randint(20,100))
session.add(student)
session.commit()
创建测试数据
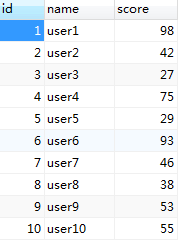
1、模型对象。指定查找这个模型的所有对象
result = session.query(Student).all()
print(result) #[<Student-id:1,name:user1,score:98>, <Student-id:2,name:user2,score:42>,...]
2、模型属性。指定查找某个模型的其中几个属性
result = session.query(Student.id, Student.name).first()
print(result) #(1, 'user1')
3、聚合函数
func.count 统计行的数量
func.avg 求平均值
func.max 求最大值
func.min 求最小值
func.sum 求和
...
from sqlalchemy import func
... result = session.query(func.avg(Student.score)).all()
print(result) #[(Decimal('55.6000'),)]
示例
filter方法常用的过滤条件
#查找id为1的记录
article = session.query(Article).filter(Article.id == 1).first()
equal
#查找title不是c++的记录
articles = session.query(Article).filter(Article.title != 'c++').all()
not equal
#查找title以p开头的记录
articles = session.query(Article).filter(Article.title.like('p%')).all()
like
#查找标题不是php也不是java的记录 #方式1:
articles = session.query(Article).filter(Article.title.notin_(['php', 'java'])).all() #方式2:
articles = session.query(Article).filter(~Article.title.in_(['php', 'java'])).all()
in
#查找detail为空的记录
articles = session.query(Article).filter(Article.detail == None).all()
is null
#查找detail不为空的记录
articles = session.query(Article).filter(Article.detail != None).all()
is not null
//查找title是python并且detail是python111的记录 #方法一:直接使用关键字参数
articles = session.query(Article).filter(Article.title=='python', Article.detail=='python111').all() #方法二,导入and_方法,from sqlalchemy import and_
articles = session.query(Article).filter(and_(Article.title=='python', Article.detail=='python111')).all()
#查找title是python,或者detail是python111的记录 导入or_方法, from sqlalchemy import or_
articles = session.query(Article).filter(or_(Article.title=='python', Article.detail=='python111')).all()
or
外键及其四种约束
在MySQL中,外键可以让表之间的关系更加紧密。而SQLAlchemy同样支持外键。通过ForeignKey类来实现。并且可以指定表的外键约束。
from sqlalchemy import ForeignKey
外键的约束有以下几项:
1、RESTRICT : 父表数据被删除,会阻止删除。默认是此项
2、NO ACTION : 在MySQL中,同RESTRICT一样
3、CASCADE : 级联删除
4、SET NULL : 父表被删除,子表数据会设置为NULL(该字段允许为NULL)
...
from sqlalchemy import ForeignKey
... class User(Base):
__tablename__ = 'user'
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(String(50), nullable=False) class Article(Base):
__tablename__ = 'article'
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(String(50), nullable=False)
content = Column(Text)
#注意:这里的uid的数据类型必须要和user表中的id数据类型一致
uid = Column(Integer, ForeignKey('user.id', ondelete='RESTRICT')) Base.metadata.create_all()
session = sessionmaker(engine)() user = User(username='heboan')
session.add(user)
session.commit() article = Article(title='hello world', content='this is a test line', uid=1)
session.add(article)
session.commit()
示例
ondelete设置外键约束,没有设置该属性则为RESTRICT, 上面我们设置为了RESTRICT
因为我们设置了外键约束是RESTRICT,所以现在删除父表user中id为1 的记录是会被阻止的

ORM层面(代码)删除数据,会无视MySQL级别的外键约束。直接将对应的数据删除,然后将从表中的那个外键设置为NULL,如果想要避免这种行为,应该将从表中的外键的nullable=False

ORM层外键和一对多关系
基于上面的情况,就是有两个表,分别为user 和article。他们两之间存在一个外键关系
需求:根据文章找到用户信息,原始的做法如下:
article = session.query(Article).first()
uid = article.uid
user = session.query(User).get(uid)
print(user)
上面的方法不够方便,orm可以这样实现
...
from sqlalchemy.orm import relationship
... class Article(Base):
__tablename__ = 'article'
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(String(50), nullable=False)
content = Column(Text)
uid = Column(Integer, ForeignKey('user.id', ondelete='RESTRICT'))
author = relationship("User") #添加作者属性,通过relationship指向user模型表 article = session.query(Article).first()
print(article.author)
orm通过实现relationship外键查找
我们也可以通过user 来找到该作者发表的文章,一个作者可能有发表多篇文章,这是一对多关系。同样的也是relationship实现
...
class User(Base):
__tablename__ = 'user'
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(String(50), nullable=False)
articles = relationship('Article')
user = session.query(User).get(2)
for article in user.articles:
print(article.title)
上面我们两个模型都互相做了relationship实现,这样比较麻烦,还有一种更简便的方法
class User(Base):
__tablename__ = 'user'
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(String(50), nullable=False) class Article(Base):
__tablename__ = 'article'
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(String(50), nullable=False)
content = Column(Text)
uid = Column(Integer, ForeignKey('user.id', ondelete='RESTRICT'))
author = relationship("User", backref="articles" ) #这样user模型表就自动拥有了articles属性关联
反向映射
有了上面的关系后,我们添加文章就可以这样
...
user = session.query(User).get(2)
article1 = Article(title='aaa', content='11aa')
article1.author = user session.add(article1)
session.commit()
添加文章方法1
...
user = session.query(User).get(2)
article1 = Article(title='bb', content='11bb')
user.articles.append(article1) session.add(user)
session.commit()
添加文章方法2
一对一关系
举个例子,把user表一些不常用查询的字段放到另外一种表user_extent,这种情况下,这两张表就是一对一的关系
如果想要将两个模型映射成一对一的关系,那么应该在父模型中,指定引用的时候,需要传递一个‘uselist=False’参数,就是告诉父模型,以后引用这个从模型的时候,不再是一个列表,而是一个对象
from sqlalchemy.orm import backref
... class User(Base):
__tablename__ = 'user'
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(String(50), nullable=False) class User_Extent(Base):
__tablename__ = 'user_extent'
id = Column(Integer, primary_key=True, autoincrement=True)
school = Column(String(50))
uid = Column(ForeignKey('user.id'))
user = relationship('User', backref=backref('extend', uselist=False))
示例
一对一关系映射后,当我们把一个用户设置2个学校就会失败
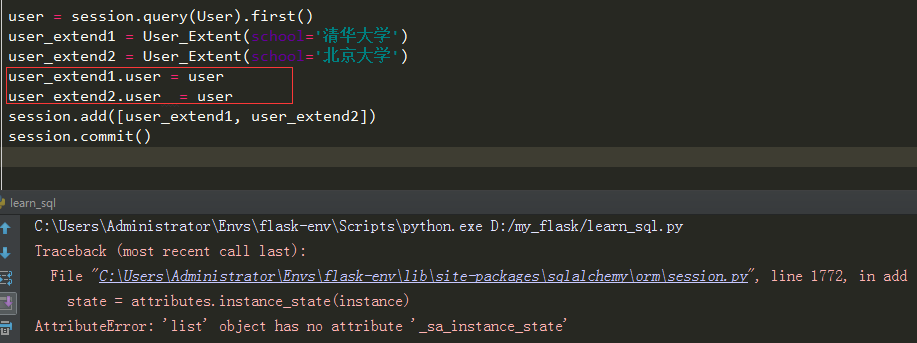
因此只能一个user只能对应user_extend中的一条记录

多对多关系
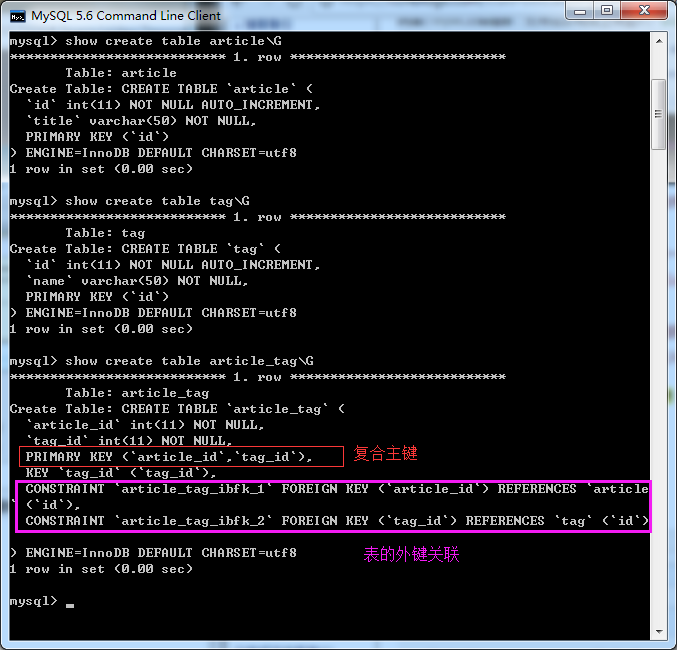
场景: 一遍文章可以有多个标签,一个标签可以对应多篇文章
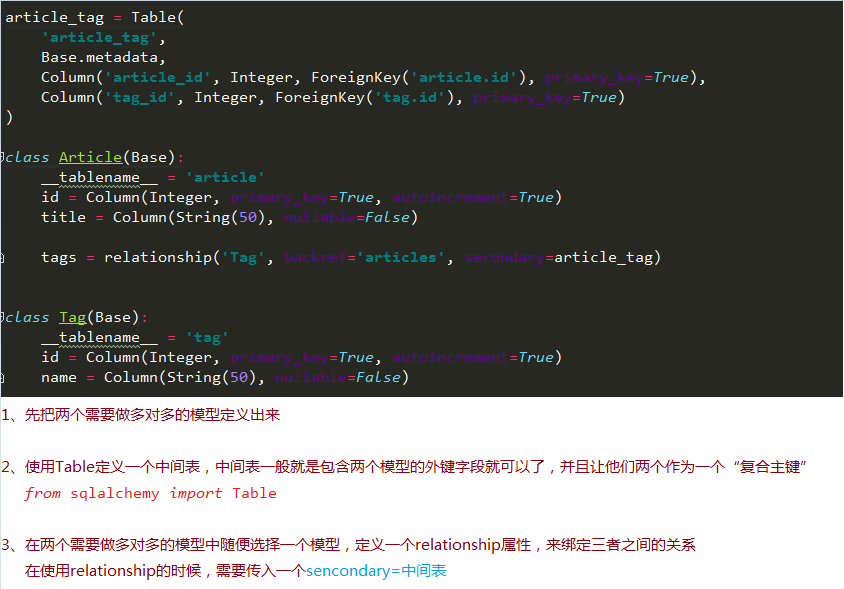
运行后,可以发现数据库成功创建了三张表

我们可以看看创建表的语句
现在我们可以写入数据
...
article1 = Article(title='Python开发')
article2 = Article(title='Java进阶') tag1 = Tag(name='编程')
tag2 = Tag(name='计算机') article1.tags.append(tag1)
article1.tags.append(tag2) article2.tags.append(tag1)
article2.tags.append(tag2) session.add_all([article1, article2])
session.commit()
写入数据
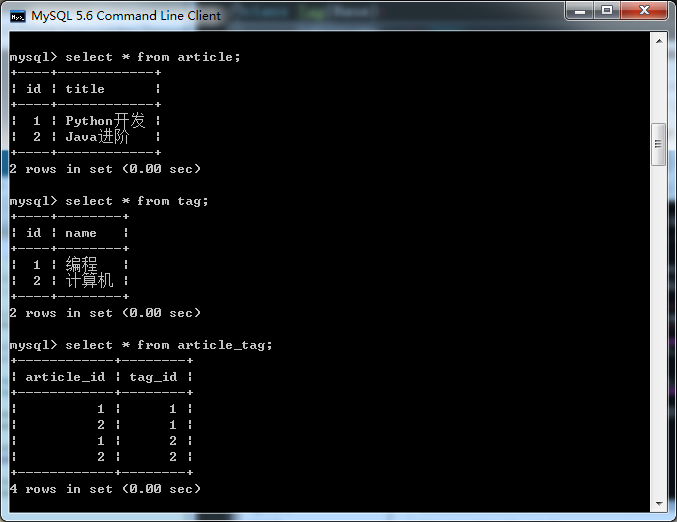
...
article = session.query(Article).get(1)
for tag in article.tags:
print(tag.name)
查询文章id为1(Python开发)的标签有哪些
...
tag = session.query(Tag).get(1)
for article in tag.articles:
print(article.title)
查询标签是'编程'的文章有哪些
relationship方法中的cascade参数详解
如果将数据库的外键设置为RESTRICT,那么在ORM层面,删除了父表中的数据,那么从表中的数据将会NULL。如果不想要这种情况发生,那么应该将这个值的nullable=False。
在SQLAlchemy,只要将一个数据添加到session中,和其他相关联的数据可以一起存入到数据库中了。这些是怎么设置的呢?其实是通过relationship的时候,有一个关键字参数cascade可以这是这些属性:
1、save-update:默认选项。在添加一条数据的时候,会把其他和其他关联的数据都添加到数据中
2、delete: 表示当删除某一个模型的数据的时候,是否也删掉使用relationship和他关联的数据
3、delete-orphan: 表示当对一个ORM对象解除了父表中的关联对象的时候,自己便会被删除掉。当然如果父表中的数据被删除,自己也会被删除。这个选项只能用在一对多上,不能用在多对多以及多对以上。并且还需要再子模型中的relationship中,增加一个single_parent=True的参数
4、merge:默认选项。当在使用session.merge合并一个对象的时候,会将使用了relationship相关联的对象也进行merge操作
5、expunge: 移除操作的时候,会将相关联的对象也进行移除。这个操作只是从session中移除,并不会真正的从数据中删除
6、all: 是对save-update, merge, refresh-expire, expunge, delete几种的缩写
排序
order_by:根据表中的某个字段进行排序,如果前面加了一个"-",代表的是降序
class Article(Base):
__tablename__ = 'article'
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(String(50), nullable=False)
create_time = Column(DateTime, nullable=False, default=datetime.now) def __str__(self):
return "<title:{},create_time:{}>".format(self.title, self.create_time) def __repr__(self):
return self.__str__()
表结构
插入两条测试数据

现在按照文章发表时间排序
article=session.query(Article).order_by(Article.create_time).all()
print(article) #结果:[<title:title1,create_time:2018-07-08 10:33:17>, <title:title2,create_time:2018-07-08 10:34:00>]
升序
article=session.query(Article).order_by(Article.create_time.desc()).all()
print(article) #结果:[<title:title2,create_time:2018-07-08 10:34:00>, <title:title1,create_time:2018-07-08 10:33:17>]
降序
方法二:
#升序
article=session.query(Article).order_by('create_time').all() #降序
article=session.query(Article).order_by('-create_time').all()
示例
__mapper_args__ : 定表模型的时候确定默认的排序规则
class Article(Base):
__tablename__ = 'article'
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(String(50), nullable=False)
create_time = Column(DateTime, nullable=False, default=datetime.now)
__mapper_args__ = {
"order_by": create_time.desc() #根据发表时间降序
} def __str__(self):
return "<title:{},create_time:{}>".format(self.title, self.create_time) def __repr__(self):
return self.__str__() ... article=session.query(Article).all()
print(article) #结果
[<title:title2,create_time:2018-07-08 10:34:00>, <title:title1,create_time:2018-07-08 10:33:17>]
定义默认排序规则
limit、offset以及切片操作
... class Article(Base):
__tablename__ = 'article'
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(String(50), nullable=False)
create_time = Column(DateTime, nullable=False, default=datetime.now) def __str__(self):
return "<title:{},create_time:{}>".format(self.title, self.create_time) def __repr__(self):
return self.__str__() Base.metadata.drop_all()
Base.metadata.create_all()
session = sessionmaker(engine)() #写入100条测试数据
for x in range(1,101):
time.sleep(2)
title = "title {}".format(x)
article = Article(title=title)
session.add(article)
session.commit()
创建表并写入测试数据
limit:可以限制每次查询的时候只查询几条数据
#查询出全部的数据
articles = session.query(Article).all()
print(articles) #通过limit查出10条
articles = session.query(Article).limit(10).all()
print(articles)
limit
articles = session.query(Article).order_by(Article.create_time.desc()).limit(10).all()
print(articles)
查出最近发表的10篇文章
offset: 可以限制查找数据的时候过滤前面多少条
#从第5条后面开始查询出10条数据
articles = session.query(Article).offset(5).limit(10).all()
print(articles) #结果
[<title:title 6,create_time:2018-07-08 12:32:03>,...<title:title 15,create_time:2018-07-08 12:32:21>]
offset
切片: 可以对Query对象使用切片操作,来获取想要的数据
#切片有两种方式: #需求:找出最近发表的10篇文章 #1、是slice(start,end)
articles = session.query(Article).order_by(Article.create_time.desc()).slice(0, 10).all()
print(articles) #2、和列表一样的操作
articles = session.query(Article).order_by(Article.create_time.desc())[0:10]
print(articles)
切片
数据查询懒加载技术
在一对多,或者多对多的时候,如果想要获取多的这一部分的数据的时候,往往能通过一个属性就可以获取全部了。比如有一个作者,想要获取这个作者的所有文章,那么可以通过user.articles就可以。但有时候我们不想获取所有的数据,比如只想获取这个作者今天发表的文章,那这时候我们就可以给relationship传递一个lazy='dynamic',以后通过user.articles获取到的就不是一个列表,而是一个AppendQuery对象了。这样就可以对这个对象再进行一层过滤和排序等操作。
lazy可用的选项:
1、'select':这个是默认选选项,比如‘user.articles’的例子,如果你没有访问‘user.articles’这个属性,那么sqlalchemy就不会从数据库中查找文章。一旦你访问了这个属性,那么sqlalchemy就会立马从数据库中查找所有的文章。这也是懒加载。
2、‘dynamic’:就是在访问‘user.articles’的时候返回的不是一个列表,而是一个AppendQuery对象
class User(Base):
__tablename__ = 'user'
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(String(50), nullable=False) def __str__(self):
return self.username def __repr__(self):
return self.__str__() class Article(Base):
__tablename__ = 'article'
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(String(50), nullable=False)
create_time = Column(DateTime, nullable=False, default=datetime.now)
uid = Column(Integer, ForeignKey('user.id'), nullable=False) author = relationship(User, backref=backref('articles', lazy='dynamic')) #lazy='dynamic' def __str__(self):
return "<title:{},create_time:{}>".format(self.title, self.create_time) def __repr__(self):
return self.__str__() Base.metadata.drop_all()
Base.metadata.create_all()
session = sessionmaker(engine)() #写入测试数据
user = User(username='heboan')
session.add(user)
session.commit() user = session.query(User).first() for x in range(1,101):
time.sleep(2)
title = "title {}".format(x)
article = Article(title=title)
article.author = user
session.add(article)
session.commit()
dynamic
上面配置了lazy='dynamic',并写入了测试数据,我们可以看看‘user.articles’类型为AppendQuery
...
user = session.query(User).first()
print(type(user.articles)) #结果
<class 'sqlalchemy.orm.dynamic.AppenderQuery'>
示例
既然user.articles为AppendQuery类型,那么它就有query拥有的属性,比如(filter、order_by等等),还可以append数据,如下
...
user = session.query(User).first()
# filter
print(user.articles.filter(Article.create_time == '2018-07-08 16:55:05').all())
#结果: [<title:title 2,create_time:2018-07-08 16:55:05>] #append
article = Article(title='python is simple')
user.articles.append(article)
session.commit()
示例

group_by和having子句
... class User(Base):
__tablename__ = 'user'
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(String(50), nullable=False)
age = Column(Integer, default=0)
gender = Column(Enum('male', 'female', 'secret'), default='male') def __str__(self):
return self.username def __repr__(self):
return self.__str__() # Base.metadata.drop_all()
Base.metadata.create_all()
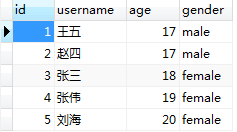
session = sessionmaker(engine)() user1 = User(username='王五', age=17, gender='male')
user2 = User(username='赵四', age=17, gender='male')
user3 = User(username='张三', age=18, gender='female')
user4 = User(username='张伟', age=19, gender='female')
user5 = User(username='刘海', age=20, gender='female') session.add_all([user1, user2, user3, user4, user5])
session.commit()
创建测试表和数据
group_by
根据某个字段进行分组。比如想要根据年龄进行分组,来统计每个分组分别有多少人
from sqlalchemy import func
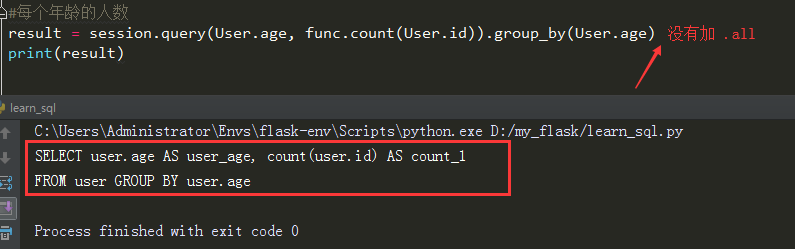
... #每个年龄的人数
result = session.query(User.age, func.count(User.id)).group_by(User.age).all()
print(result) #结果
[(17, 2), (18, 1), (19, 1), (20, 1)]
每个年龄的人数
查看sql语句
having
having是对查找结果进一步过滤。比如只想要看成年人的数量,那么可以首先对年龄进行分组统计人数,然后再对分组进行having过滤
#每个年龄的人数
result = session.query(User.age, func.count(User.id)).group_by(User.age).having(User.age >= 18).all()
print(result) #结果
[(18, 1), (19, 1), (20, 1)]
按年龄分组并查看成年人人数
join实现复杂查询
是使用SQLAlemy 的join功能之前,我们先了解原生的sql语句中的left join, right join, inner join用法
#创建表a
CREATE TABLE a(
aID int(1) AUTO_INCREMENT PRIMARY KEY,
aNUM char(20)
); #创建表b
CREATE TABLE b(
bID int(1) AUTO_INCREMENT PRIMARY KEY,
bNUM char(20)
); #插入数据到表a
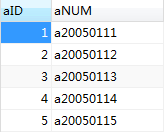
INSERT INTO a VALUES
( 1, 'a20050111' ),
( 2, 'a20050112' ),
( 3, 'a20050113' ),
( 4, 'a20050114' ),
( 5, 'a20050115' ); #插入数据到表b
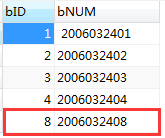
INSERT INTO b VALUES
( 1, ''),
( 2, '' ),
( 3, '' ),
( 4, '' ),
( 8, '' );
创建a,b两张表
表a记录如下
表b记录如下
left join(左联接)
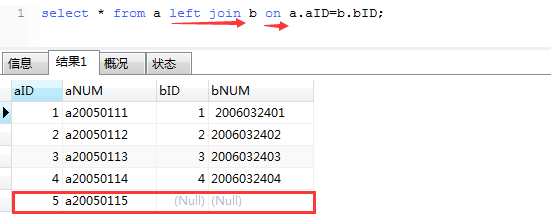
结果说明:
left join 是以a表的记录为基础,a可以看成左表,B可以看成右表,left join是以左表为准的,换句话说,左表(a)的记录将会全部表示出来,而右表(b)只会显示复合搜索条件的记录,B表记录不足的地方均为NULL.
right join(右联接)
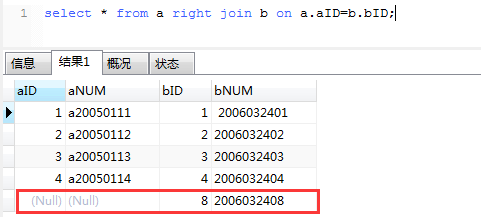
结果说明:
和left join的结果刚好相反,这次是以右表(b)为基础的,a表不足的地方用null填充
inner join(内联接)
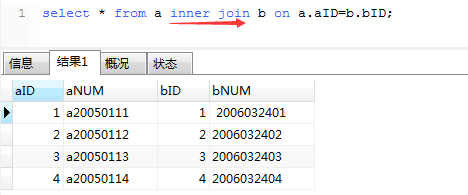
结果说明
很明显,这里只显示出了 a.aID = b.bID的记录.这说明inner join并不以谁为基础,它只显示符合条件的记录.
SQLAlcemy使用join
...
class User(Base):
__tablename__ = 'user'
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(String(50), nullable=False) def __str__(self):
return self.username def __repr__(self):
return self.__str__() class Article(Base):
__tablename__ = 'article'
id = Column(Integer, primary_key=True, autoincrement=True)
title = Column(String(50), nullable=False)
uid = Column(Integer, ForeignKey('user.id'), nullable=False)
author = relationship(User, backref='articles') def __str__(self):
return self.title def __repr__(self):
return self.__str__() # Base.metadata.drop_all()
# Base.metadata.create_all()
session = sessionmaker(engine)() user1 = User(username='jack')
user2 = User(username='slina') #用户jack有3篇文章
for x in range(3):
article = Article(title='jack title {}'.format(x))
article.author = user1
session.add(article)
session.commit() #用户slina有5篇文章
for x in range(5):
article = Article(title='slina title {}'.format(x))
article.author = user2
session.add(article)
session.commit()
创建表及数据
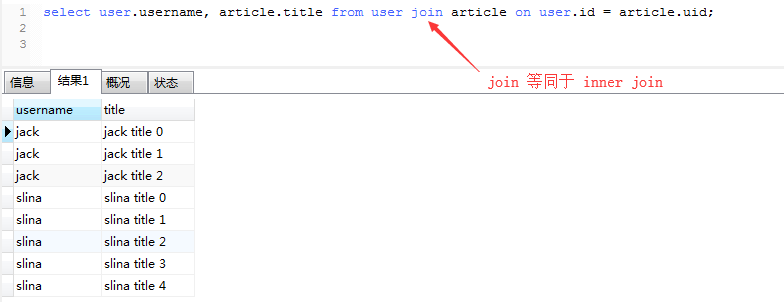
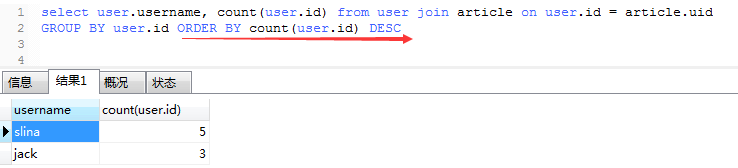
需求:查询出每个用户发表的文章数,并按倒序排序
我们先用原生sql写一遍:
1、先把两张表内连接查询
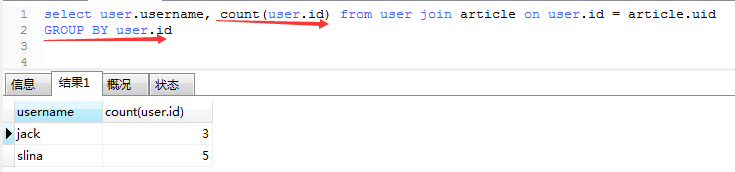
2、使用user.id进行分组统计出每个用户的文章数
3、最后把查询出来的结果依据文章数进行倒序排序
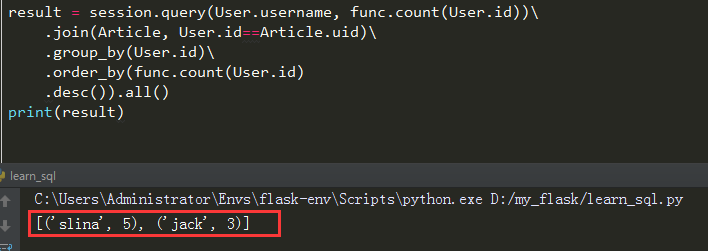
我们再来用sqlalchemy写出来
看下他的SQL语句是怎么样的
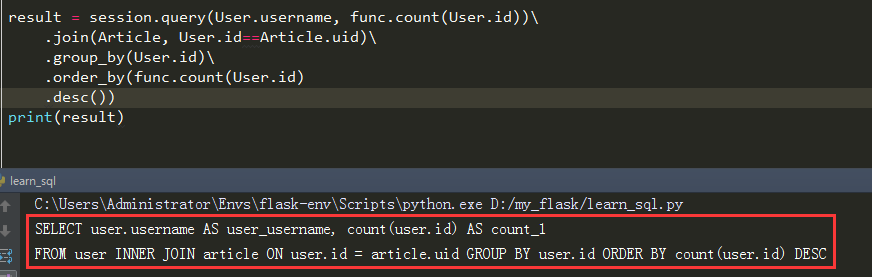
注意2点:
在sqlalchemy中,使用join来完成内联接。在写join的时候,如果不写join条件(User.id==Article=uid),那么默认使用外键作为条件连接
query查找出什么值,不会取决于join后面的东西,而是取决于query方法中传了什么参数。就跟原生sql 中的select后面那个一样
subquery实现复杂查询
子查询可以让多个查询变成一个查询,只要查找一次数据库,性能相对来讲更高效一点
...
class User(Base):
__tablename__ = 'user'
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(String(50), nullable=False)
city = Column(String(50), nullable=False)
age = Column(Integer, default=0) def __str__(self):
return self.username def __repr__(self):
return self.__str__() # Base.metadata.drop_all()
Base.metadata.create_all()
session = sessionmaker(engine)() user1 = User(username='李A', city="长沙", age=18)
user2 = User(username='王B', city="长沙", age=18)
user3 = User(username='赵C', city="北京", age=18)
user4 = User(username='张D', city="长沙", age=20) session.add_all([user1, user2, user3, user4])
session.commit()
创建测试表及数据
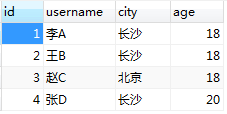
需求:寻找和李A这个人在同一个城市,并且是同年龄的人
我们可能会这样查询:
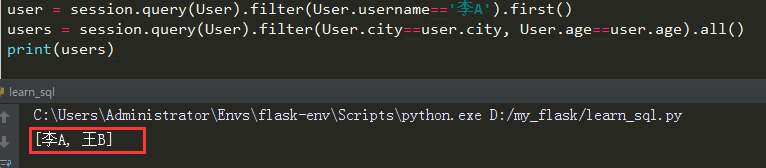
上面的方法可以实现需求,但是却需要查询两次数据库,这样必定会降低数据库查询性能,我们可以使用子查询的方式来实现需求:
原生sql子查询如下
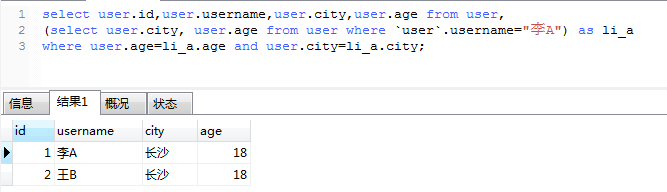
使用sqlalchemy实现

在子查询中,将以后需要用到的字段通过 label方法取个别名
在父查询中,如果想要使用子查询的字段,那么可以通过子查询的返回值的 c属性难道
13、Flask实战第13天:SQLAlchemy操作MySQL数据库的更多相关文章
- 【tips】ORM - SQLAlchemy操作MySQL数据库
优先(官方文档SQLAlchemy-version1.2): sqlalchemy | 作者:斯芬克斯 推荐一(长篇幅version1.2.0b3):python约会之ORM-sqlalchemy | ...
- python【第十二篇下】操作MySQL数据库以及ORM之 sqlalchemy
内容一览: 1.Python操作MySQL数据库 2.ORM sqlalchemy学习 1.Python操作MySQL数据库 2. ORM sqlachemy 2.1 ORM简介 对象关系映射(英语: ...
- Python3:sqlalchemy对mysql数据库操作,非sql语句
Python3:sqlalchemy对mysql数据库操作,非sql语句 # python3 # author lizm # datetime 2018-02-01 10:00:00 # -*- co ...
- 本地通过Eclipse链接Hadoop操作Mysql数据库问题小结
前一段时间,在上一篇博文中描述了自己抽时间在构建的完全分布式Hadoop环境过程中遇到的一些问题以及构建成功后,通过Eclipse操作HDFS的时候遇到的一些问题,最近又想进一步学习学习Hadoop操 ...
- 使用python操作mysql数据库
这是我之前使用mysql时用到的一些库及开发的工具,这里记录下,也方便我查阅. python版本: 2.7.13 mysql版本: 5.5.36 几个python库 1.mysql-connector ...
- ASP.NET Core使用EF Core操作MySql数据库
ASP.NET Core操作MySql数据库, 这样整套环境都可以布署在Linux上 使用微软的 Microsoft.EntityFrameworkCore(2.1.4) 和MySql出的 MySql ...
- (转)防止人为误操作MySQL数据库技巧一例
原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 .作者信息和本声明.否则将追究法律责任.http://oldboy.blog.51cto.com/2561410/1321061 防止人 ...
- 【Python】使用python操作mysql数据库
这是我之前使用mysql时用到的一些库及开发的工具,这里记录下,也方便我查阅. python版本: 2.7.13 mysql版本: 5.5.36 几个python库 1.mysql-connector ...
- Python操作MySQL数据库9个实用实例
用python连接mysql的时候,需要用的安装版本,源码版本容易有错误提示.下边是打包了32与64版本. MySQL-python-1.2.3.win32-py2.7.exe MySQL-pytho ...
随机推荐
- 【BZOJ 1647】[Usaco2007 Open]Fliptile 翻格子游戏 模拟、搜索
第一步我们发现对于每一个格子,我们只有翻和不翻两种状态,我们发现一旦确定了第一行操作,那么第二行的操作也就随之确定了,因为第一行操作之后我们要想得到答案就得把第一行全部为0,那么第二行的每一个格子的操 ...
- [USACO Hol10] 臭气弹 图上期望概率dp 高斯
记住一开始和后来的经过是两个事件因此概率可以大于一 #include<cstdio> #include<iostream> #include<cstdlib> #i ...
- HDU1151:Air Raid(最小边覆盖)
Air Raid Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Su ...
- 用静态工厂的方法实例化bean
//代码如下: package com.timo.domain; public class ClientService { //use static factory method create bea ...
- 通过js修改微信内置浏览器title
document.setTitle = function(t) { document.title = t; var i = document.createElement('iframe'); i.sr ...
- oracle中分页的知识
一:前言 自从出来实习后,基本上都没有按下心来总结下自己学的知识点,刚刚好现在快要国庆了,没有到深圳出差,在公司呆了三天,可以说是在公司打了三天的酱油啊,所以前两天都是在看些正则的文档,并且写了下总结 ...
- 网络(bzoj 4538)
Description 一个简单的网络系统可以被描述成一棵无根树.每个节点为一个服务器.连接服务器与服务器的数据线则看做一条树边.两个服务器进行数据的交互时,数据会经过连接这两个服务器的路径上的所有服 ...
- Django项目知识点汇总
目录 一.wsgi接口 二.中间件 三.URL路由系统 四.Template模板 五.Views视图 六.Model&ORM 七.Admin相关 八.Http协议 九.COOKIE 与 SES ...
- Ajax的Result工具类
ResultUtil.java package cn.qlq.util; import java.io.Serializable; public class ResultUtil<T> i ...
- 【Sqlite3】SQLITE3使用总结(转)
原文转自 https://www.cnblogs.com/wenxp2006/archive/2012/06/04/2535169.html SQL语句操作 介绍如何用sqlite 执行标准 sql ...