HBase 是什么

Apache HBase™ is the Hadoop database, a distributed, scalable, big data store.
HBase 是 Hadoop database 一个分布式(文件在HDFS上)的可拓展(分区域存储的)的大数据仓库。用于存储和检索海量数据
Use Apache HBase™ when you need random随机, realtime实时 read/write access存取 to your Big Data. This project's goal is the hosting of very large tables -- billions数十亿 of rows X millions百万 of columns -- atop clusters of commodity hardware商用机器. Apache HBase is an open-source, distributed, versioned多版本(数据可以有多个版本的值), non-relational database modeled after Google's Bigtable: A Distributed Storage System for Structured Data by Chang et al. Just as Bigtable leverages the distributed data storage provided by the Google File System, Apache HBase provides Bigtable-like capabilities on top of Hadoop and HDFS.
与传统 RDBMS 数据库,HBase 対与海量数据查询检索速度有明显速度上的优势
Table in HBase
- Schema:TableName & Column Family Name
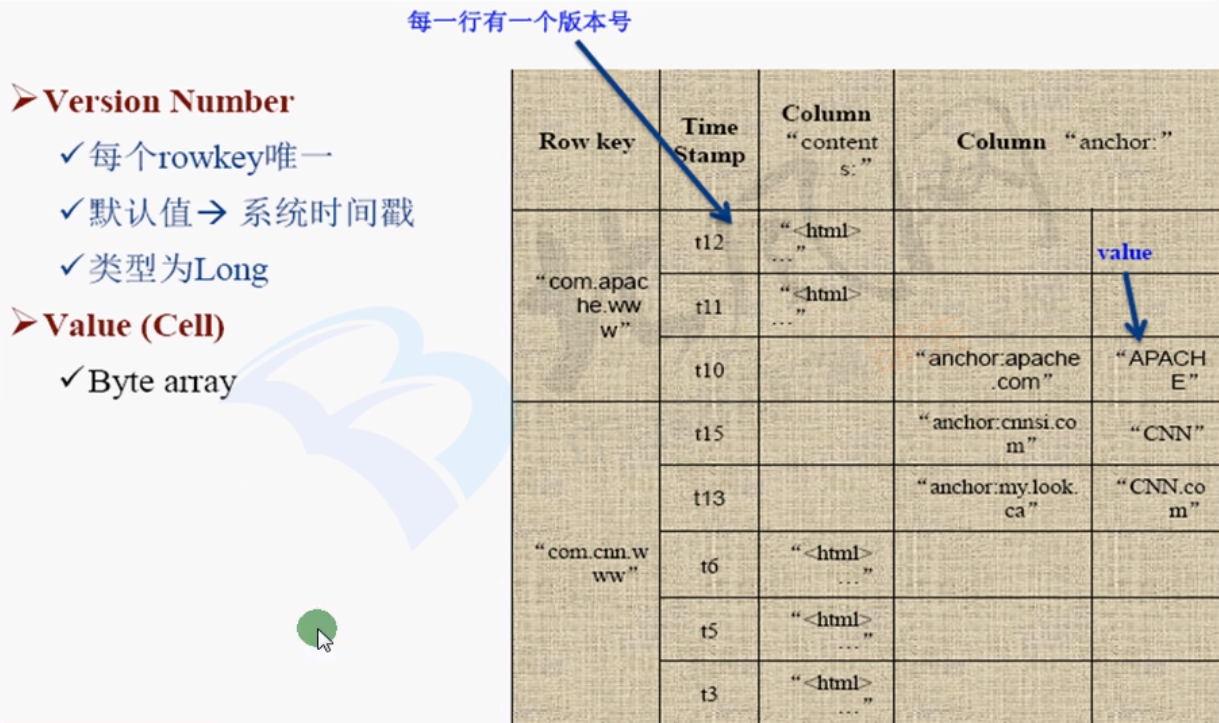
意味着 HBase 每一行的列不一定相同,不占据空间(RDBMS为NULL也占据空间) - Value 和 Name 都是使用 byte[] 数组存储在 HDFS 中
HBase 是一个面向列的数据库,数据按列存储
一个数据单元 Cell 包括了:rowkey + columnfamily + [column] + timestamp : value
- columnfamily(列簇):字段的类别 eg: basic 包括了(name,age,birthday...)
- rowkey(行关键字):类似RDBMS中的主键,作为行的唯一标识符,每个 cell 都,快速查询的关键有 eg:ID
Example

[](http://images2017.cnblogs.com/blog/1047249/201707/1047249-20170731172419911-340741011.png
{kind=link}
HBase 是什么的更多相关文章
- Mapreduce的文件和hbase共同输入
Mapreduce的文件和hbase共同输入 package duogemap; import java.io.IOException; import org.apache.hadoop.co ...
- Redis/HBase/Tair比较
KV系统对比表 对比维度 Redis Redis Cluster Medis Hbase Tair 访问模式 支持Value大小 理论上不超过1GB(建议不超过1MB) 理论上可配置(默认配置1 ...
- Hbase的伪分布式安装
Hbase安装模式介绍 单机模式 1> Hbase不使用HDFS,仅使用本地文件系统 2> ZooKeeper与Hbase运行在同一个JVM中 分布式模式– 伪分布式模式1> 所有进 ...
- Spark踩坑记——数据库(Hbase+Mysql)
[TOC] 前言 在使用Spark Streaming的过程中对于计算产生结果的进行持久化时,我们往往需要操作数据库,去统计或者改变一些值.最近一个实时消费者处理任务,在使用spark streami ...
- Spark读写Hbase的二种方式对比
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 一.传统方式 这种方式就是常用的TableInputFormat和TableOutputForm ...
- 深入学习HBase架构原理
HBase定义 HBase 是一个高可靠.高性能.面向列.可伸缩的分布式存储系统,利用Hbase技术可在廉价PC Server上搭建 大规模结构化存储集群. HBase 是Google Bigtabl ...
- hbase协处理器编码实例
Observer协处理器通常在一个特定的事件(诸如Get或Put)之前或之后发生,相当于RDBMS中的触发器.Endpoint协处理器则类似于RDBMS中的存储过程,因为它可以让你在RegionSer ...
- hbase集群安装与部署
1.相关环境 centos7 hadoop2.6.5 zookeeper3.4.9 jdk1.8 hbase1.2.4 本篇文章仅涉及hbase集群的搭建,关于hadoop与zookeeper的相关部 ...
- 从零自学Hadoop(22):HBase协处理器
阅读目录 序 介绍 Observer操作 示例下载 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,Sour ...
- Hbase安装和错误
集群规划情况: djt1 active Hmaster djt2 standby Hmaster djt3 HRegionServer 搭建步骤: 第一步:配置conf/regionservers d ...
随机推荐
- 一个自动生成awr报告的shell脚本
最近在学习shell编程,搞一点点小工具自动完成awr报告的收集工作,方便系统出现问题时问题排查.脚本内容如下,系统收集每天开始时间6点结束时间20点的awr报告并存储在/u01/shell_t/aw ...
- delphi7 打开project/options 出错
出错提示:Access violation at address 0012F88F. Write of address 0012F88F.然后又提示一条:Access violation at add ...
- SQA和测试规程
SQA *:first-child { margin-top: 0 !important; } body>*:last-child { margin-bottom: 0 !important; ...
- MySQL联合索引最左匹配范例
MySQL联合索引最左匹配范例 参考文章:http://blog.jobbole.com/24006/ 创建示例表. 示例表来自MySQL官方文档: https://dev.mysql.com/doc ...
- 更改win7关机菜单选项功能
说明:如果你不希望别人对你的电脑进行注销切换等操,那么可以使用如下的方法 实现效果: 实现步骤: 效果1 1>切换用户: 2>注销:(需重启资源管理器生效) 效果2:
- serlvet配置xml和@WebServlet
简单介绍 XML元素不仅是大小写敏感的,而且它们还对出现在其他元素中的次序敏感.例如,XML头必须是文件中的第一项,DOCTYPE声明必须是第二项,而web-app元素必须是第三项.在web-app元 ...
- 【洛谷P1582】倒水
倒水 题目链接 显然,2^x个杯子里的水可以倒在一个杯子里 所以我们可以贪心地每次将N中最大的2^x减掉 减k次(若中途已经为0,直接输出0) 若大于0,用最小的比N大的2^x减剩下的N,即为答案 # ...
- Angularjs实例2
<!DOCTYPE html><html><head><meta http-equiv="Content-Type" content=&q ...
- mysql数据去重复distinct、group by
使用distinct 和group by都可以实现数据去重. select distinct 字段 group by 一般放在where条件后
- ## `nrm`的安装使用
作用:提供了一些最常用的NPM包镜像地址,能够让我们快速的切换安装包时候的服务器地址:什么是镜像:原来包刚一开始是只存在于国外的NPM服务器,但是由于网络原因,经常访问不到,这时候,我们可以在国内,创 ...