Scrapy爬虫框架与常用命令
07.08自我总结
一.Scrapy爬虫框架
大体框架
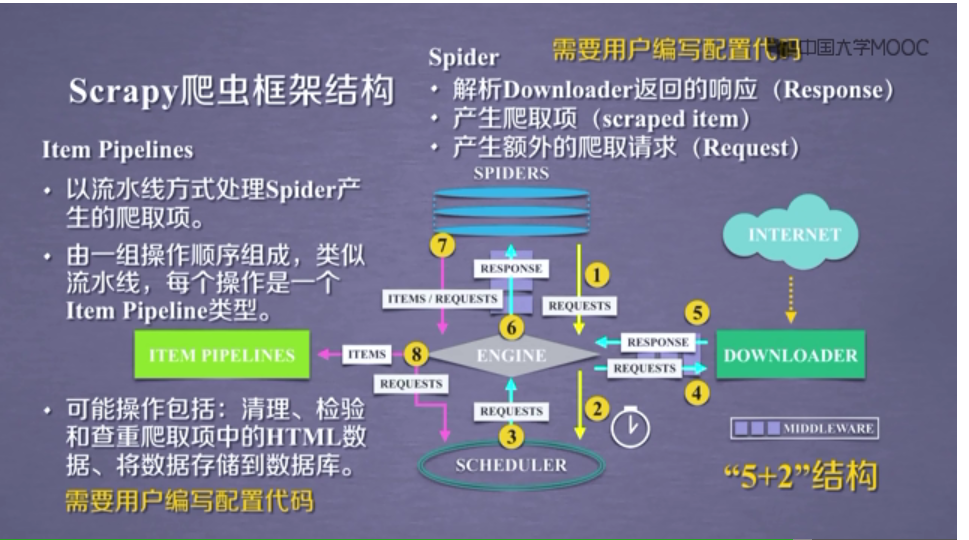
2个桥梁


二.常用命令
全局命令
startproject
语法:
scrapy startproject <project_name>这个命令是scrapy最为常用的命令之一,它将会在当前目录下创建一个名为
<project_name>的项目。settings
语法:
scrapy settings [options]该命令将会输出Scrapy默认设定,当然如果你在项目中运行这个命令将会输出项目的设定值。
runspider
语法:
scrapy runspider <spider_file.py>在未创建项目的情况下,运行一个编写在Python文件中的spider。
shell
语法:
scrapy shell [url]以给定的URL(如果给出)或者空(没有给出URL)启动Scrapy shell。
例如,
scrapy shell http://www.baidu.com
将会打开百度URL,
并且启动交互式命令行,可以用来做一些测试。
fetch
语法:
scrapy fetch <url>使用Scrapy下载器(downloader)下载给定的URL,并将获取到的内容送到标准输出。简单的来说,就是打印url的html代码。
view
语法:
scrapy view <url>在你的默认浏览器中打开给定的URL,并以Scrapy spider获取到的形式展现。 有些时候spider获取到的页面和普通用户看到的并不相同,一些动态加载的内容是看不到的, 因此该命令可以用来检查spider所获取到的页面。
version
语法:
scrapy version [-v]输出Scrapy版本。配合 -v 运行时,该命令同时输出Python, Twisted以及平台的信息。
项目命令
crawl
语法:
scrapy crawl <spider_name>使用你项目中的spider进行爬取,即启动你的项目。这个命令将会经常用到,我们会在后面的内容中经常使用。
check
语法:
crapy check [-l] <spider>运行contract检查,检查你项目中的错误之处。
list
语法:
scrapy list列出当前项目中所有可用的spider。每行输出一个spider。
genspider
语法:
scrapy genspider [-t template] <name> <domain>在当前项目中创建spider。该方法可以使用提前定义好的模板来生成spider。您也可以自己创建spider的源码文件。
Scrapy爬虫框架与常用命令的更多相关文章
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影
前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大家讲解一个完整爬虫的流程. 工具和环境 语言:python 2 ...
- Scrapy 爬虫框架学习笔记(未完,持续更新)
Scrapy 爬虫框架 Scrapy 是一个用 Python 写的 Crawler Framework .它使用 Twisted 这个异步网络库来处理网络通信. Scrapy 框架的主要架构 根据它官 ...
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- scrapy爬虫框架学习笔记(一)
scrapy爬虫框架学习笔记(一) 1.安装scrapy pip install scrapy 2.新建工程: (1)打开命令行模式 (2)进入要新建工程的目录 (3)运行命令: scrapy sta ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- 手把手教你如何新建scrapy爬虫框架的第一个项目(上)
前几天给大家分享了如何在Windows下创建网络爬虫虚拟环境及如何安装Scrapy,还有Scrapy安装过程中常见的问题总结及其对应的解决方法,感兴趣的小伙伴可以戳链接进去查看.关于Scrapy的介绍 ...
- 安装scrapy 爬虫框架
安装scrapy 爬虫框架 个人根据学习需要,在Windows搭建scrapy爬虫框架,搭建过程种遇到个别问题,共享出来作为记录. 1.安装python 2.7 1.1下载 下载地址 1.2配置环境变 ...
随机推荐
- MinGW 编译 libsndfile-1.0.25(只要有 MSYS,./configure make make install 就行了)
最近做的一个项目需要读写 wav 文件.在网上找到 libsndfile 刚好满足我的需要.但是编译的时候遇到了点小麻烦,这里记录一下编译的过程,免得下次再编译时忘记了. 因为是在编译完成若干天后写的 ...
- Qt 5.8 for Device Creation(好多内容,包括虚拟机安装,静态编译)
http://doc.qt.io/QtEnterpriseEmbedded/qt-configuration-tool.html http://doc.qt.io/QtEnterpriseEmbedd ...
- WCF研究-中篇
中篇 5.托管于宿主 6.消息模式 7.WCF行为-实例管理和并发控制 8.安全 5.托管于宿主 托管 宿主Host Ø承载WCF Service运行的环境 自承载方式 系统服务方式 IIS方式 WA ...
- 如何在excel中把汉字转换成拼音
---恢复内容开始--- 1.启动Excel 2003(其它版本请仿照操作),打开相应的工作表: 2 2.执行“工具→宏→Visual Basic编辑器”命令(或者直接按“Alt+F11”组合键),进 ...
- 每日一问:浅谈 onAttachedToWindow 和 onDetachedFromWindow
基本上所有 Android 开发都会接触到 onCreate().onDestory().onStart().onStop() 等这些生命周期方法,但却不是所有人都会去关注到 onAttachXXX( ...
- Java中常用的url签名防篡改方法
实现方式:Md5(url+key) 的方式进行的. 1.key可以是任意的字符串,然后“客户端”和“服务器端”各自保留一份,千万不能外泄. 2.请求的URL 例如: name=lxl&age ...
- [Java] 父类和子类拥有同名的成员变量(fields)的情况
首先,需要明确的是,无论是通过casting,还是通过将子类对象的reference赋值给父类变量,都无法改变该reference所指对象的真实类型.但当该reference的类型是父类时,将无法调用 ...
- 20 如何通过pycharm快速的创建一个html页面
1.打开pycharm并且新建一个html页面,如下图所示. 2.删除html页面中默认的内容,之后在页面中输入!,之后点击tab即可完成一个html页面的框架新增.
- spring 5.x 系列第21篇 —— spring 定时任务 (xml配置方式)
源码Gitub地址:https://github.com/heibaiying/spring-samples-for-all 一.说明 1.1 项目结构说明 关于任务的调度配置定义在springApp ...
- spring 5.x 系列第14篇 —— 整合RabbitMQ (代码配置方式)
源码Gitub地址:https://github.com/heibaiying/spring-samples-for-all 一.说明 1.1 项目结构说明 本用例关于rabbitmq的整合提供简单消 ...