6个冷门但实用的pandas知识点
1 简介
pandas作为开展数据分析的利器,蕴含了与数据处理相关的丰富多样的API,使得我们可以灵活方便地对数据进行各种加工,但很多pandas中的实用方法其实大部分人都是不知道的,今天就来给大家介绍6个不太为人们所所熟知的实用pandas小技巧。
 图1
图1
2 6个实用的pandas小知识
2.1 Series与DataFrame的互转
很多时候我们计算过程中产生的结果是Series格式的,而接下来的很多操作尤其是使用链式语法时,需要衔接着传入DataFrame格式的变量,这种时候我们就可以使用到pandas中Series向DataFrame转换的方法:
- 利用to_frame()实现Series转DataFrame
s = pd.Series([0, 1, 2])
# Series转为DataFrame,name参数用于指定转换后的字段名
s = s.to_frame(name='列名')
s
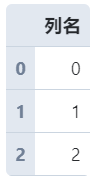 图2
图2
顺便介绍一下单列数据组成的数据框转为Series的方法:
- 利用squeeze()实现单列数据DataFrame转Series
# 只有单列数据的DataFrame转为Series
s.squeeze()
 图3
图3
2.2 随机打乱DataFrame的记录行顺序
有时候我们需要对数据框整体的行顺序进行打乱,譬如在训练机器学习模型时,打乱原始数据顺序后取前若干行作为训练集后若干行作为测试集,这在pandas中可以利用sample()方法快捷实现。
sample()方法的本质功能是从原始数据中抽样行记录,默认为不放回抽样,其参数frac用于控制抽样比例,我们将其设置为1则等价于打乱顺序:
df = pd.DataFrame({
'V1': range(5),
'V2': range(5)
})
df.sample(frac=1)
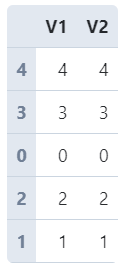 图4
图4
2.3 利用类别型数据减少内存消耗
当我们的数据框中某些列是由少数几种值大量重复形成时,会消耗大量的内存,就像下面的例子一样:
import numpy as np
pool = ['A', 'B', 'C', 'D']
# V1列由ABCD大量重复形成
df = pd.DataFrame({
'V1': np.random.choice(pool, 1000000)
})
# 查看内存使用情况
df.memory_usage(deep=True)
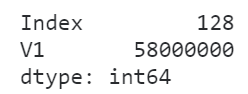 图5
图5
这种时候我们可以使用到pandas数据类型中的类别型来极大程度上减小内存消耗:
df['V1'] = df['V1'].astype('category')
df.memory_usage(deep=True)
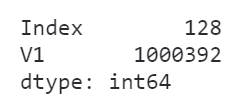 图6
图6
可以看到,转换类型之后内存消耗减少了将近98.3%!
2.4 pandas中的object类型陷阱
在日常使用pandas处理数据的过程中,经常会遇到object这种数据类型,很多初学者都会把它视为字符串,事实上object在pandas中可以代表不确定的数据类型,即类型为object的Series中可以混杂着多种数据类型:
s = pd.Series(['111100', '111100', 111100, '111100'])
s
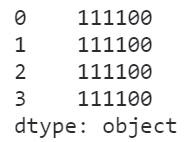 图7
图7
查看类型分布:
s.apply(lambda s: type(s))
 图8
图8
这种情况下,如果贸然当作字符串列来处理,对应的无法处理的元素只会变成缺失值而不报错,给我们的分析过程带来隐患:
s.str.replace('00', '11')
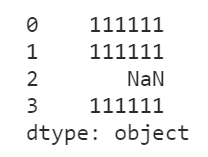 图9
图9
这种时候就一定要先转成对应的类型,再执行相应的方法:
s.astype('str').str.replace('00', '11')
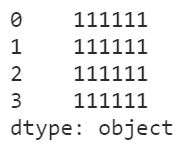 图10
图10
2.5 快速判断每一列是否有缺失值
在pandas中我们可以对单个Series查看hanans属性来了解其是否包含缺失值,而结合apply(),我们就可以快速查看整个数据框中哪些列含有缺失值:
df = pd.DataFrame({
'V1': [1, 2, None, 4],
'V2': [1, 2, 3, 4],
'V3': [None, 1, 2, 3]
})
df.apply(lambda s: s.hasnans)
 图11
图11
2.6 使用rank()计算排名时的五种策略
在pandas中我们可以利用rank()方法计算某一列数据对应的排名信息,但在rank()中有参数method来控制具体的结果计算策略,有以下5种策略,在具体使用的时候要根据需要灵活选择:
- average
在average策略下,相同数值的元素的排名是其内部排名的均值:
s = pd.Series([1, 2, 2, 2, 3, 4, 4, 5, 6])
s.rank(method='average')
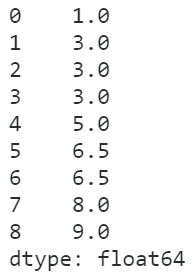 图12
图12
- min
在min策略下,相同元素的排名为其内部排名的最小值:
s.rank(method='min')
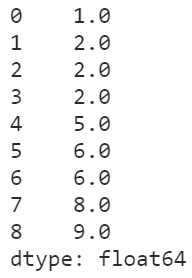 图13
图13
- max
max策略与min正好相反,取的是相同元素内部排名的最大值:
s.rank(method='max')
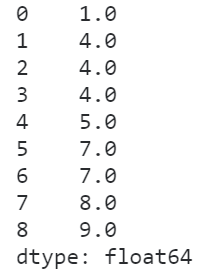 图14
图14
- dense
在dense策略下,相当于对序列去重后进行排名,再将每个元素的排名赋给相同的每个元素,这种方式也是比较贴合实际需求的:
s.rank(method='dense')
 图15
图15
- first
在first策略下,当多个元素相同时,会根据这些相同元素在实际Series中的顺序分配排名:
s = pd.Series([2, 2, 2, 1, 3])
s.rank(method='first')
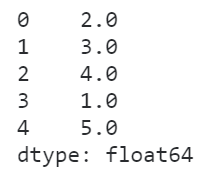 图16
图16
关于pandas还有很多实用的小知识,以后会慢慢给大家不定期分享~欢迎在评论区与我进行讨论
6个冷门但实用的pandas知识点的更多相关文章
- Python数据分析--Pandas知识点(三)
本文主要是总结学习pandas过程中用到的函数和方法, 在此记录, 防止遗忘. Python数据分析--Pandas知识点(一) Python数据分析--Pandas知识点(二) 下面将是在知识点一, ...
- Python数据分析--Pandas知识点(二)
本文主要是总结学习pandas过程中用到的函数和方法, 在此记录, 防止遗忘. Python数据分析--Pandas知识点(一) 下面将是在知识点一的基础上继续总结. 13. 简单计算 新建一个数据表 ...
- pandas知识点脑图汇总
参考文献: [1]Pandas知识点脑图汇总
- 机器学习-Pandas 知识点汇总(吐血整理)
Pandas是一款适用很广的数据处理的组件,如果将来从事机械学习或者数据分析方面的工作,咱们估计70%的时间都是在跟这个框架打交道.那大家可能就有疑问了,心想这个破玩意儿值得花70%的时间吗?咱不是还 ...
- 这几个冷门却实用的 Python 库,我爱了!
- 盘点 php 里面那些冷门又实用的小技巧
1.实用某个字段索引二维数组 取出一个数组的一个字段的值的数组,我们可以使用 array_column, 这个方法还有另外一个用法,如 array_column($array, null, 'key' ...
- Python数据分析--Pandas知识点(一)
本文主要是总结学习pandas过程中用到的函数和方法, 在此记录, 防止遗忘 1. 重复值的处理 利用drop_duplicates()函数删除数据表中重复多余的记录, 比如删除重复多余的ID. im ...
- Python之Pandas知识点
很多人都分不清Numpy,Scipy,pandas三个库的区别. 在这里简单分别一下: NumPy:数学计算库,以矩阵为基础的数学计算模块,包括基本的四则运行,方程式以及其他方面的计算什么的,纯数学: ...
- pandas知识点汇总
## pandas基础知识汇总 1.时间序列 import pandas as pd import numpy as np import matplotlib.pyplot as plt from d ...
随机推荐
- 吴恩达-机器学习+Logistic回归分类方案
- 在Ubuntu下部署Flask项目
FlaskDemo 命名为test.py # coding=utf-8 from flask import Flask app = Flask(__name__) @app.route("/ ...
- C# Web Service简介及使用
一. 软件开发的形式 1.SaaS:Software as a Service(软件即服务) (1)将软件视为一种基础设施与服务 (2)网络无所不在,网络可以看成是一个软件服务的聚合体,是一个超级大& ...
- springmvc与mybatis整合时 java.lang.IllegalArgumentException: Property 'sqlSessionFactory' or 'sqlSessionTemplate' are required 异常
今天在整合springmvc与mybatis时,启动服务器遇到这样一个问题, by: java.lang.IllegalArgumentException: Property 'sqlSessionF ...
- JS进阶系列-JS执行期上下文(一)
❝ 点赞再看,年薪百万 本文已收录至https://github.com/likekk/-Blog欢迎大家star,共同进步.如果文章有出现错误的地方,欢迎大家指出.后期将在将GitHub上规划前端学 ...
- makefile实验二 对目标的深入理解 以及rebuild build clean的实现
(一) rebuild build clean的实现 新知识点: 当一个目标的依赖是一个伪目标时,这个伪目标的规则一定会被执行. 贴实验代码 CC := gcc Target := helloworl ...
- IdentityServer4系列 | 初识基础知识点
前言 我们现在日常生活中,会使用各式各样的应用程序,层出不穷,其中有基于网页浏览方式的应用,有基于手机端的App,甚至有基于流行的公众号和小程序等等,这些应用,我们不仅要实现各个应用的功能之外,还要考 ...
- What number should I guess next ?——由《鹰蛋》一题引发的思考
What number should I guess next ? 这篇文章的灵感来源于最近技术部的团建与著名的DP优化<鹰蛋>.记得在一个月前,查到鹰蛋的题解前,我在与同学讨论时,一直试 ...
- C++ CComboBox控件详解
转载:http://blog.sina.com.cn/s/blog_46d93f190100m395.html C++ CComboBox控件详解 (2010-09-14 14:03:44) 转载▼ ...
- Java 使用UDP传输一个小文本文件
工具1:Eclipse 工具2:IntelliJ IDEA Java工程的目录结构(基于IntelliJ IDEA) 例1.1:接收方,因为接收到的数据是字节流,为了方便,这里是基于Apache co ...