Apache Hudi助力nClouds加速数据交付
1. 概述
在nClouds上,当客户的业务决策取决于对近实时数据的访问时,客户通常会向我们寻求有关数据和分析平台的解决方案。但随着每天创建和收集的数据量都在增加,这使得使用传统技术进行数据分析成为一项艰巨的任务。
本文我们将讨论nClouds如何帮助您应对数据延迟,数据质量,系统可靠性和数据隐私合规性方面的挑战。
Amazon EMR上的Apache Hudi是需要构建增量数据管道、大规模近实时处理数据的理想解决方案。本篇文章将在Amazon EMR的Apache Hudi上进行原型验证。
nClouds是具有DevOps、数据分析和迁移能力的AWS高级咨询合作伙伴 ,并且是AWS托管服务提供商(MSP)和AWS完善的合作伙伴计划的成员。nClouds的使命是帮助您构建和管理可更快交付创新的现代基础架构解决方案。
2. 解决方案概述
Apache Hudi是一个开源数据管理框架,用于简化增量数据处理和数据管道开发。它最初于2016年在Uber开发,旨在为PB级数据分析提供更快的数据,进行低延迟、高效率的数据摄取。
Apache Hudi通常用于简化进入数据湖和分析服务的数据管道,支持记录级粒度的Change Data Capture(CDC),同时可通过Apache Hive和Presto之类的SQL查询引擎对数据集进行近乎实时的分析,更多关于Hudi详情,可访问hudi.apache.org
Amazon EMR是领先的云大数据平台,可使用开源工具(例如Apache Hudi,Apache Spark,Apache Hive,Apache HBase,Apache Flink和Presto)处理大量数据。当选择Spark,Hive或Presto作为部署选项时,Apache Hudi会自动安装在Amazon EMR集群中。
在2019年,Amazon EMR团队开始与Apache Hudi社区密切合作,以提供补丁和bug修复并添加对AWS Glue Data Catalog的支持。
Apache Hudi非常适合将数据快速提取到Hadoop分布式文件系统(HDFS)或云存储中,并加快ETL/Hive/ Spark作业,Hudi适用于读繁重或写繁重的场景,它可以管理存储在Amazon Simple Storage Service(Amazon S3)上的数据。
2.1 数据延迟
高数据延迟会影响客户的运营能力,进一步影响新产品和服务的快速开发和交付,盈利能力以及基于事实的决策。
在上述场景下,我们建议使用Apache Hudi,它提供了DeltaStreamer实用工具程序来执行自动增量更新处理,使得关键业务数据管道能够以接近实时的延迟实现高效摄取,每次查询表时,都可以读取这些增量文件。
Apache Hudi通过处理对近实时数据的查询以及增量拉取进行时间点数据分析的查询来节省时间。
2.2 数据质量
数据量不断增长可能会对数据质量判断造成困难。从海量、可变和复杂的数据集中提取高质量的数据非常困难,尤其是在混合了非结构化,半结构化和结构化数据的情况下。
当数据快速变化时,其质量取决于其时效性,Apache Hudi能够处理数据结构变更,自动执行增量数据更新以及有效地提取流数据的能力,有助于提取和集成高质量数据。
Apache Hudi可与Amazon Simple Workflow(Amazon SWF),AWS Data Pipeline和AWS Lambda等AWS服务集成以实现自动化实时数据湖工作流程。
2.3 系统可靠性
当我们执行AWS Well-Architected Review(使用AWS Well-Architected Framework的最佳实践进行架构评估)时,我们关注的核心点之一是架构可靠性。如果通过临时提取,转换,加载(ETL)作业提取数据,而没有可靠的架构通信机制,则系统可靠性可能会受到威胁。
我们喜欢Apache Hudi在数据湖中控制和管理文件布局的功能,此功能对于维护健康的数据生态系统至关重要,因为它提高了可靠性和查询性能。
使用Hudi,用户无需加载新数据并使用ETL清理数据,从之前数据层摄取的数据和变更会自动更新,并在保存新数据时触发自动化的工作流程。
然后在AWS数据库迁移服务(AWS DMS)注册更新,并在Amazon Simple Storage Service(Amazon S3)的源位置中创建一个Apache Parquet文件,它使用Apache Avro作为记录的内部规范表示,从而在数据提取或ETL管道中提供可靠性。
2.4 遵守数据隐私法规
Apache Hudi管理着数据湖中数据的所有交互,并且提供对数据的访问的服务,同时Apache Hudi使得基于Amazon S3的数据湖能够遵守数据隐私法,其提供了记录级的更新和删除,因此用户可以选择行使其被遗忘的权利或更改其有关如何使用其数据的同意。
3. 原型验证
在nClouds,我们构建了一个非面向客户的原型验证(PoC)以说明如何使用Hudi的插入、更新和删除操作来处理数据集中的更改,COVID-19的经济影响促使我们使用与COVID-19大流行相关的数据。
TDWI最近的一项研究发现,由于大流行的影响,超过一半的数据和分析专业人员被要求回答新类型的问题,约三分之一的受访者表示,他们需要更新模型和分析负载以通过重新训练模型或重塑客户群来应对不断变化的客户行为。
我们PoC的数据流为Amazon Relational Database Service(Amazon RDS)-> Amazon S3记录集更改 -> Hudi数据集,以快速应用增量更改。同时我们需要一个环境来运行我们的测试,包括Amazon RDS,AWS DMS任务,Amazon EMR集群和S3存储桶,最后一步做数据可视化,我们使用Amazon QuickSight展示报表。
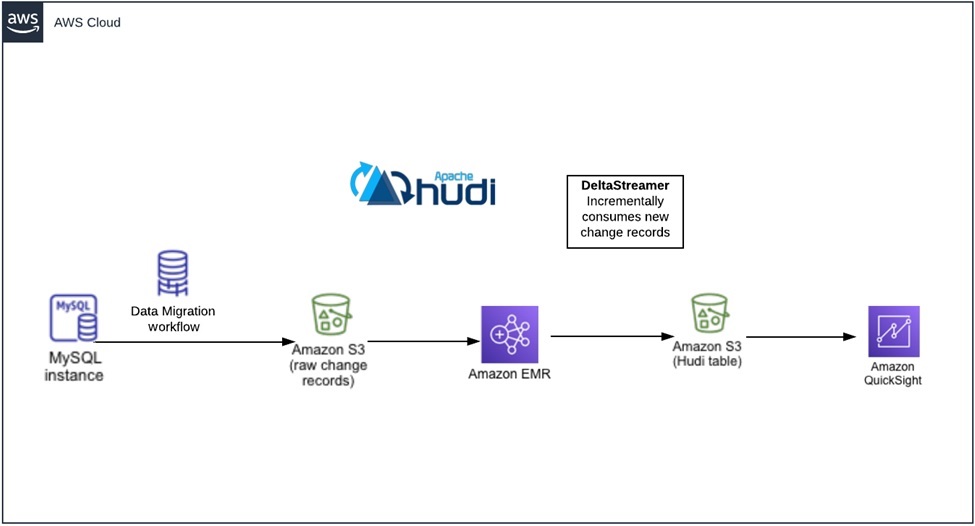
下面是PoC方案的每个具体步骤
第一步:Amazon RDS设置
在Amazon RDS仪表板中,跳转到数据库参数组部分,然后创建一个新的参数组,将binlog格式设置为ROW。
创建一个新的Amazon RDS实例,确保使用设置的DB Parameter group并开启自动备份;
创建完成后,进行连接并创建如下MySQL Schema
CREATE TABLE covid_by_state(
covid_by_state_id INTEGER NOT NULL AUTO_INCREMENT,
date TIMESTAMP DEFAULT NOW() ON UPDATE NOW(),
state VARCHAR(100),
fips INTEGER,
cases INTEGER,
deaths INTEGER,
CONSTRAINT orders_pk PRIMARY KEY(covid_by_state_id)
);
INSERT INTO covid_by_state( date , state, fips, cases, deaths) VALUES('2020-01-21','Washington',53,1,0);
INSERT INTO covid_by_state( date , state, fips, cases, deaths) VALUES('2020-01-21','Illinois',17,1,0);
第二步:AWS DMS设置
下一步需要使用AWS DMS将数据复制到Amazon S3中,需要一个复制实例来运行测试和复制任务
- 进入AWS DMS控制面板并创建一个新的复制实例
- 创建两个端点,一个使用Amazon RDS作为数据源,另一个使用S3作为目的地
- 检查状态,开始运行
- 使用如下策略创建AWS Identity and Access Management角色
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"s3:DeleteObjectTagging",
"s3:PutObject",
"s3:GetObject",
"s3:GetObjectTagging",
"s3:PutObjectTagging",
"s3:DeleteObject"
],
"Resource": "arn:aws:s3:::bigdatablueprint-role/*"
}
]
}
- 创建Amazon S3目的地,使用如下设置来确保使用Apache Parquet文件格式
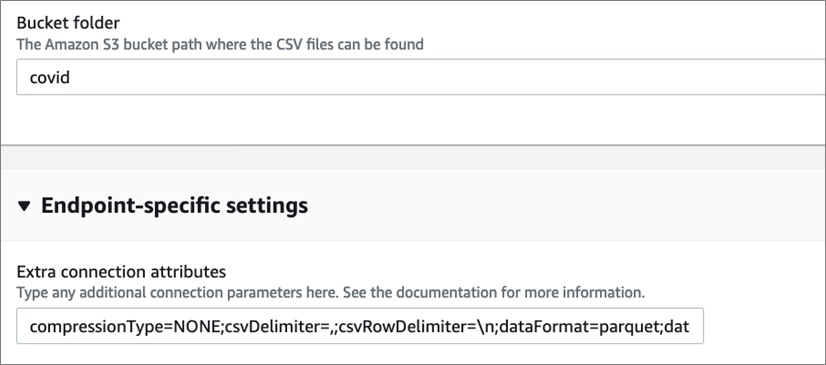
- 检查是否正常工作,下图展示了AWS DMS成功运行的结果

第三步:AWS DMS任务设置
第四步:Amazon EMR集群设置
安装Apache Spark,Apache Hive或Presto时,Amazon EMR(发行版5.28.0及更高版本)会默认安装Apache Hudi组件。
Apache Spark或Apache Hudi DeltaStreamer实用程序可以创建或更新Apache Hudi数据集。Apache Hive,Apache Spark或Presto可以交互式查询Apache Hudi数据集,或使用增量拉取(仅拉取两次操作之间更改的数据)来构建数据处理管道。
以下是有关如何使用Apache Hudi运行新的Amazon EMR集群和处理数据的教程。
- 进入Amazon EMR控制面板
- 填写如下配置
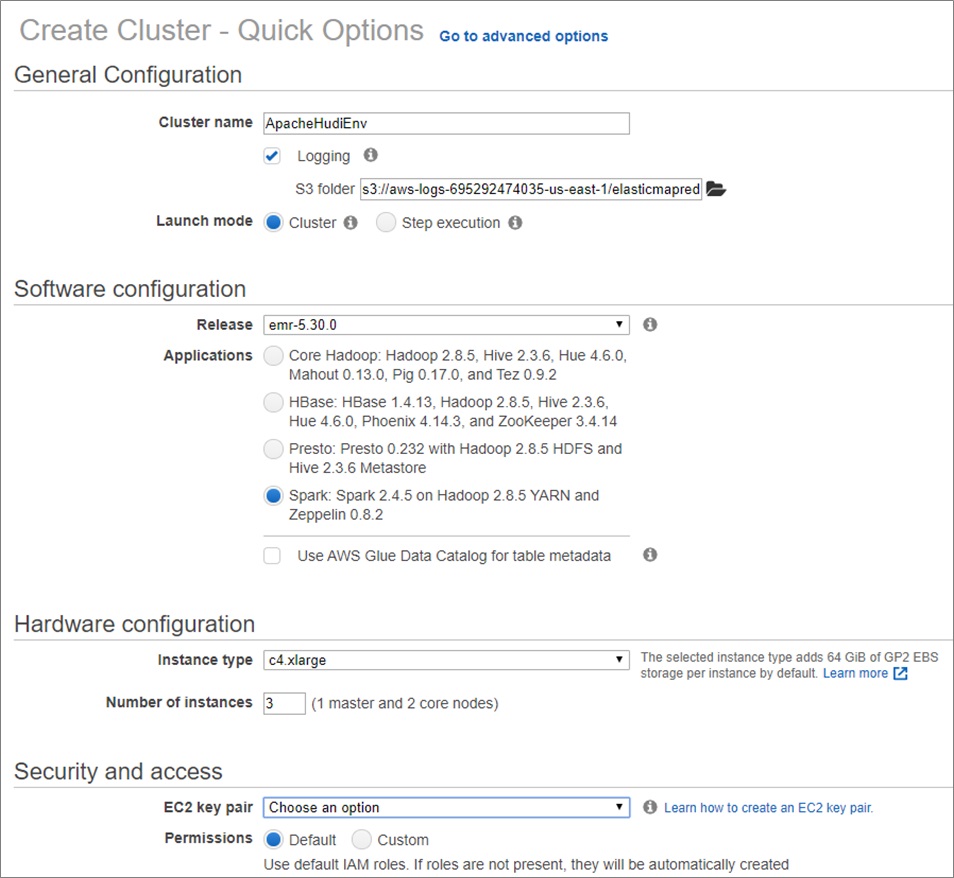
- 集群运行后,执行以下脚本来设置数据库。运行Apache Spark命令以查看两行初始插入的当前数据库状态。
scala>scala> spark.read.parquet("s3://bigdatablueprint-raw/covid/hudi_dms/covid_by_state/*").sort("updated_at").show
+----+--------+---------+-------------+-------------------+-------------------+
+----+-----------------+-------------------+----------+----+-----+------+
| Op|covid_by_state_id| date| state|fips|cases|deaths|
+----+-----------------+-------------------+----------+----+-----+------+
|null| 1|2020-01-21 00:00:00|Washington| 53| 1| 0|
|null| 2|2020-01-21 00:00:00| Illinois| 17| 1| 0|
第五步:使用Apache Hudi DeltaStreamer处理变更日志
- 要开始使用更改日志,请在工作流时间表上使用以Apache Spark作业运行的Apache Hudi DeltaStreamer。 例如,按如下所示启动Apache Spark Shell:
spark-submit --class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer --packages org.apache.spark:spark-avro_2.11:2.4.4 --master yarn --deploy-mode client hudi-utilities-bundle_2.11-0.5.2-incubating.jar --table-type
COPY_ON_WRITE --source-ordering-field cases --source-class org.apache.hudi.utilities.sources.ParquetDFSSource --target-base-path s3://bigdatablueprint-final/hudi_covid --target-table cover --transformer-class org.apache.hudi.utilities.transform.AWSDmsTrans
- 这是Apache Hudi表,具有与上游表相同的记录(也包含所有_hoodie字段):
scala> spark.read.parquet("s3://bigdatablueprint-final/hudi_covid/*/*.parquet").sort("cases").show
+-------------------+--------------------+------------------+----------------------+--------------------+-----------------+-------------------+----------+----+-----+------+---+
|_hoodie_commit_time|_hoodie_commit_seqno|_hoodie_record_key|_hoodie_partition_path| _hoodie_file_name|covid_by_state_id| date| state|fips|cases|deaths| Op|
+-------------------+--------------------+------------------+----------------------+--------------------+-----------------+-------------------+----------+----+-----+------+---+
| 20200812061302| 20200812061302_0_1| 1| default|0a292b18-5194-45d...| 1|2020-01-21 00:00:00|Washington| 53| 1| 0| |
| 20200812061302| 20200812061302_0_2| 2| default|0a292b18-5194-45d...| 2|2020-01-21 00:00:00| Illinois| 17| 1| 0| |
- 进行数据库更改以查看其他行和更新的值。
- 一旦在源Amazon S3存储桶更新后,AWS DMS将立即将摄取,然后重新运行相同的Apache Hudi作业,从而将新的Apache Parquet文件添加到AWS DMS输出文件夹。
scala> spark.read.parquet("s3://bigdatablueprint-raw/covid/hudi_dms/covid_by_state/*").sort("cases").show
+----+-----------------+-------------------+----------+----+-----+------+
| Op|covid_by_state_id| date| state|fips|cases|deaths|
+----+-----------------+-------------------+----------+----+-----+------+
| I| 4|2020-01-21 00:00:00| Arizona| 4| 1| 0|
|null| 1|2020-01-21 00:00:00|Washington| 53| 1| 0|
|null| 2|2020-01-21 00:00:00| Illinois| 17| 1| 0|
| U| 1|2020-08-12 06:25:04|Washington| 53| 60| 0|
+----+-----------------+-------------------+----------+----+-----+------+
- 重新运行Apache Hudi DeltaStreamer命令时,它将把Apache Parquet文件变更成Apache Hudi表。
- 这是运行Apache Spark作业后的Apache Hudi结果:
scala> spark.read.parquet("s3://bigdatablueprint-final/hudi_covid/*/*.parquet").sort("cases").show
+-------------------+--------------------+------------------+----------------------+--------------------+-----------------+-------------------+----------+----+-----+------+---+
|_hoodie_commit_time|_hoodie_commit_seqno|_hoodie_record_key|_hoodie_partition_path| _hoodie_file_name|covid_by_state_id| date| state|fips|cases|deaths| Op|
+-------------------+--------------------+------------------+----------------------+--------------------+-----------------+-------------------+----------+----+-----+------+---+
| 20200812061302| 20200812061302_0_1| 1| default|0a292b18-5194-45d...| 1|2020-01-21 00:00:00|Washington| 53| 1| 0| |
| 20200812061302| 20200812061302_0_2| 2| default|0a292b18-5194-45d...| 2|2020-01-21 00:00:00| Illinois| 17| 1| 0| |
| 20200812063216| 20200812063216_0_1| 4| default|0a292b18-5194-45d...| 4|2020-01-21 00:00:00| Arizona| 4| 1| 0| I|
| 20200812062710| 20200812062710_0_1| 1| default|0a292b18-5194-45d...| 1|2020-08-12 06:25:04|Washington| 53| 60| 0| U|
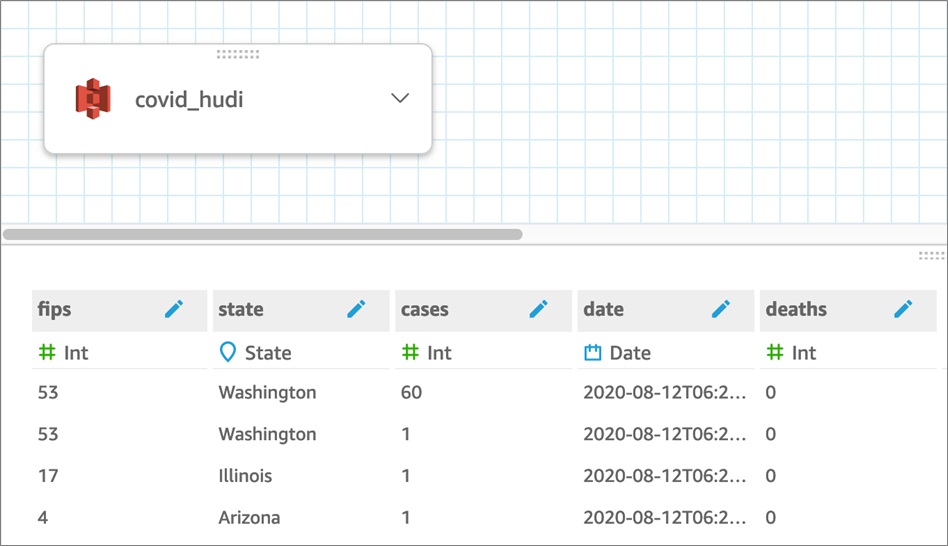
- 将数据转化为CSV格式以便可以通过Amazon QuickSight读取
var df = spark.read.parquet("s3://bigdatablueprint-final/hudi_covid/*/*.parquet").sort("cases")
df.write.option("header","true").csv("covid.csv")
使用上述命令将数据转换为.csv后,它是一种便于Amazon QuickSight查看的数据格式,可以将其可视化。下图显示了来自QuickSight中原始(.csv)源的数据的一种表示形式。
这种数据视图按状态细分了特定日期的案例数。随着Hudi使用新数据(可以直接流式传输)更新表时,将启用通过QuickSight进行近实时或实时报告。
4. 总结
在本文中,我们逐步介绍了我们的非面向客户的PoC解决方案,以在Amazon EMR和其他托管服务(包括用于数据可视化的Amazon QuickSight)上使用Apache Hudi建立新的数据和分析平台。
如果您的业务决策取决于对近实时数据的访问,并且您面临数据延迟,高数据质量,系统可靠性以及对数据隐私法规的遵从性等挑战,我们建议从nClouds实施此解决方案,它旨在加速需要增量数据管道和处理的大规模和近实时应用程序中的数据交付。
Apache Hudi助力nClouds加速数据交付的更多相关文章
- 基于Apache Hudi构建分析型数据湖
为了有机地发展业务,每个组织都在迅速采用分析. 在分析过程的帮助下,产品团队正在接收来自用户的反馈,并能够以更快的速度交付新功能. 通过分析提供的对用户的更深入了解,营销团队能够调整他们的活动以针对特 ...
- 使用Apache Flink 和 Apache Hudi 创建低延迟数据湖管道
近年来出现了从单体架构向微服务架构的转变.微服务架构使应用程序更容易扩展和更快地开发,支持创新并加快新功能上线时间.但是这种方法会导致数据存在于不同的孤岛中,这使得执行分析变得困难.为了获得更深入和更 ...
- Apache Hudi在医疗大数据中的应用
本篇文章主要介绍Hudi在医疗大数据中的应用,主要分为5个部分进行介绍:1. 建设背景,2. 为什么选择Hudi,3. Hudi数据同步,4. 存储类型选择及查询优化,5. 未来发展与思考. 1. 建 ...
- 对话Apache Hudi VP, 洞悉数据湖的过去现在和未来
Apache Hudi是一个开源数据湖管理平台,用于简化增量数据处理和数据管道开发,该平台可以有效地管理业务需求,例如数据生命周期,并提高数据质量.Hudi的一些常见用例是记录级的插入.更新和删除.简 ...
- 基于Apache Hudi在Google云构建数据湖平台
自从计算机出现以来,我们一直在尝试寻找计算机存储一些信息的方法,存储在计算机上的信息(也称为数据)有多种形式,数据变得如此重要,以至于信息现在已成为触手可及的商品.多年来数据以多种方式存储在计算机中, ...
- 基于 Apache Hudi 和DBT 构建开放的Lakehouse
本博客的重点展示如何利用增量数据处理和执行字段级更新来构建一个开放式 Lakehouse. 我们很高兴地宣布,用户现在可以使用 Apache Hudi + dbt 来构建开放Lakehouse. 在深 ...
- 使用 Apache Hudi 实现 SCD-2(渐变维度)
数据是当今分析世界的宝贵资产. 在向最终用户提供数据时,跟踪数据在一段时间内的变化非常重要. 渐变维度 (SCD) 是随时间推移存储和管理当前和历史数据的维度. 在 SCD 的类型中,我们将特别关注类 ...
- 通过Apache Hudi和Alluxio建设高性能数据湖
T3出行的杨华和张永旭描述了他们数据湖架构的发展.该架构使用了众多开源技术,包括Apache Hudi和Alluxio.在本文中,您将看到我们如何使用Hudi和Alluxio将数据摄取时间缩短一半.此 ...
- Robinhood基于Apache Hudi的下一代数据湖实践
1. 摘要 Robinhood 的使命是使所有人的金融民主化. Robinhood 内部不同级别的持续数据分析和数据驱动决策是实现这一使命的基础. 我们有各种数据源--OLTP 数据库.事件流和各种第 ...
随机推荐
- Redis 三大缓存
Redis 三大缓存 过去的有些事情不一定要忘记,但一定要放下. 背景:Redis 三大缓存:缓存穿透.缓存击穿.缓存雪崩,是Redis 面试必须要掌握的东西. 一.缓存穿透 1.概念简述 ...
- 使用Java Stream,提取集合中的某一列/按条件过滤集合/求和/最大值/最小值/平均值
不得不说,使用Java Stream操作集合实在是太好用了,不过最近在观察生产环境错误日志时,发现偶尔会出现以下2个异常: java.lang.NullPointerException java.ut ...
- Maven学习总结:几个常用的maven插件
我们使用maven做一些日常的工作开发的时候,无非是想利用这个工具带来的一些便利.比如它带来的依赖管理,方便我们打包和部署运行.这里几个常见的插件就是和这些工程中常用的步骤相关. maven-comp ...
- 记一次"截图"功能的项目调研过程!
目录 项目需求 功能调研 AWT Swing Html2Image PhantomJS Headless Chrome 实现方案 结论 项目需求 最近,项目接到了一个新需求,要求对指定URL进行后端模 ...
- python协程(yield、asyncio标准库、gevent第三方)、异步的实现
引言 同步:不同程序单元为了完成某个任务,在执行过程中需靠某种通信方式以协调一致,称这些程序单元是同步执行的. 例如购物系统中更新商品库存,需要用"行锁"作为通信信号,让不同的更新 ...
- JUC 常用4大并发工具类
什么是JUC? JUC就是java.util.concurrent包,这个包俗称JUC,里面都是解决并发问题的一些东西 该包的位置位于java下面的rt.jar包下面 4大常用并发工具类: Count ...
- spring aop 源码分析(二) 代理方法的执行过程分析
在上一篇aop源码分析时,我们已经分析了一个bean被代理的详细过程,参考:https://www.cnblogs.com/yangxiaohui227/p/13266014.html 本次主要是分析 ...
- SQL Server 子查询遇到的坑
这两天改 Bug 时使用 Sql Server 的子查询遇到了一些问题,特此记录一下,之前用 MySQL 比较多,按照 MySQL 的语法其实是没有问题的. 以下面这张表为例: 执行以下 SQL: s ...
- 软件定义网络实验记录①--Mininet 源码安装和可视化拓扑工具
第一步: 在 Ubuntu 系统的 home 目录下创建一个目录,目录名为自己的标识,包括但 不限于学号.姓名拼音等,目录不要包含中文. 第二步: 在创建的目录下,完成 Mininet 的源码安装. ...
- sqli-labs第三关 详解
通过第二关,来到第三关 我们用了前两种方法,都报错,然后自己也不太会别的注入,然后莫名的小知识又增加了.这居然是一个带括号的字符型注入, 这里我们需要闭合前面的括号. $sql=select * fr ...