机器学习:集成学习:随机森林.GBDT
集成学习(Ensemble Learning)
集成学习的思想是将若干个学习器(分类器&回归器)组合之后产生一个新学习器.弱分类器(weak learner)指那些分类准确率只稍微好于随机猜测的分类器(error
rate < 0.5);
集成算法的成功在于保证弱分类器的多样性(Diversity).而且集成不稳定的算法也能够得到一个比较明显的性能提升
常见的集成学习思想有:
Bagging
Boosting
Stacking
Why need Ensemble Learning?
1. 弱分类器间存在一定的差异性,这会导致分类的边界不同,也就是说可能存在错误。那么将多个弱分类器合并后,就可以得到更加合理的边界,减少整体的错误率,实现更好的效果;
2. 对于数据集过大或者过小,可以分别进行划分和有放回的操作产生不同的数据子集,然后使用数据子集训练不同的分类器,最终再合并成为一个大的分类器;
3. 如果数据的划分边界过于复杂,使用线性模型很难描述情况,那么可以训练多个模型,然后再进行模型的融合;
4. 对于多个异构的特征集的时候,很难进行融合,那么可以考虑每个数据集构建一个分类模型,然后将多个模型融合。
Bagging方法
Bagging方法又叫做自举汇聚法(Bootstrap Aggregating),思想是:在原始数据集上通过有放回的抽样的方式,重新选择出S个新数据集来分别训练S个分类器的集成技术。也就是说这些模型的训练数据中允许存在重复数据。
Bagging方法训练出来的模型在预测新样本分类的时候,会使用多数投票或者求均值的方式来统计最终的分类结果。
Bagging方法的弱学习器可以是基本的算法模型,eg: Linear、Ridge、Lasso、Logistic、Softmax、ID3、C4.5、CART、SVM、KNN等
备注:Bagging方式是有放回的抽样,并且每个子集的样本数量必须和原始样本数量一致,但是子集中允许存在重复数据。
随机森林(Random Forest)
在Bagging策略的基础上进行修改后的一种算法
从样本集中用Bootstrap采样选出n个样本;
从所有属性中随机选择K个属性,选择出最佳分割属性作为节点创建决策树;
重复以上两步m次,即建立m棵决策树;
这m个决策树形成随机森林,通过投票表决结果决定数据属于那一类
RF的推广算法
RF算法在实际应用中具有比较好的特性,应用也比较广泛,主要应用在:分类、
回归、特征转换、异常点检测等。常见的RF变种算法如下:
Extra Tree
Totally Random Trees Embedding(TRTE)
Isolation Forest
Extra Tree
Extra Tree是RF的一个变种,原理基本和RF一样,区别如下:
1. RF会随机采样来作为子决策树的训练集,而Extra Tree每个子决策树采用原始数
据集训练;
2.RF在选择划分特征点的时候会和传统决策树一样,会基于信息增益、信息增益率、
基尼系数、均方差等原则来选择最优特征值;而Extra Tree会随机的选择一个特征值
来划分决策树。
Extra Tree因为是随机选择特征值的划分点,这样会导致决策树的规模一般大于RF所生成的决策树。也就是说Extra Tree模型的方差相对于RF进一步减少。在某
些情况下,Extra Tree的泛化能力比RF的强
Totally Random Trees Embedding(TRTE)完全随机树嵌入
TRTE是一种非监督的数据转化方式。将低维的数据集映射到高维,从而让映射到高维的数据更好的应用于分类回归模型。
TRTE算法的转换过程类似RF算法的方法,建立T个决策树来拟合数据。当决策树构建完成后,数据集里的每个数据在T个决策树中叶子节点的位置就定下来了,将位置信息转换为向量就完成了特征转换操作。
Isolation Forest 与世隔绝的森林
IForest是一种异常点检测算法,使用类似RF的方式来检测异常点;IForest算法和RF算法的区别在于:
1. 在随机采样的过程中,一般只需要少量数据即可;
2. 在进行决策树构建过程中,IForest算法会随机选择一个划分特征,并对划分特征随机选择一个划分阈值;
3. IForest算法构建的决策树一般深度max_depth是比较小的。
区别原因:目的是异常点检测,所以只要能够区分异常的即可,不需要大量数据;另外在异常点检测的过程中,一般不需要太大规模的决策树。
对于异常点的判断,则是将测试样本x拟合到T棵决策树上。计算在每棵树上该样本的叶子节点的深度ht(x)。从而计算出平均深度h(x);然后就可以使用下列公式计算样本点x的异常概率值,p(x,m)的取值范围为[0,1],越接近于1,则是异常点的概率越大。

RF随机森林总结
RF的主要优点:
1. 训练可以并行化,对于大规模样本的训练具有速度的优势;
2. 由于进行随机选择决策树划分特征列表,这样在样本维度比较高的时候,仍然具有比较高的训练性能;
3.给出各个特征的重要性列表;
4. 由于存在随机抽样,训练出来的模型方差小,泛化能力强;
5. RF实现简单;
6. 对于部分特征的缺失不敏感。
RF的主要缺点:
1. 在某些噪音比较大的特征上,RF模型容易陷入过拟合;
2. 取值比较多的划分特征对RF的决策会产生更大的影响,从而有可能影响模型的效果。
随机森林的思考
在随机森林的构建过程中,由于各棵树之间是没有关系的,相对独立的;在构建的过程中,构建第m棵子树的时候,不会考虑前面的m-1棵树。
Boosting
提升学习(Boosting是一种机器学习技术,可以用于回归和分类的问题,它每一步产生弱预测模型(如决策树),并加权累加到总模型中;如果每一步的弱预测模型的生成都是依据损失函数的梯度方式的,那么就称为梯度提升(Gradientboosting);
提升技术的意义:如果一个问题存在弱预测模型,那么可以通过提升技术的办法得到一个强预测模型;
常见的模型有:
Adaboost
Gradient Boosting(GBT/GBDT/GBRT)
AdaBoost算法原理
Adaptive Boosting是一种迭代算法。每轮迭代中会在训练集上产生一个新的学习器,然后使用该学习器对所有样本进行预测,以评估每个样本的重要性(Informative)。换句话来讲就是,算法会为每个样本赋予一个权重,每次用训练好的学习器标注/预测各个样本,如果某个样本点被预测的越正确,则将其权重降低;否则提高样本的权重。权重越高的样本在下一个迭代训练中所占的比重就越大,也就是说越难区分的样本在训练过程中会变得越重要;
整个迭代过程直到错误率足够小或者达到一定的迭代次数为止。
Adaboost算法
Adaboost算法将基分类器的线性组合作为强分类器,同时给分类误差率较小的基本分类器以大的权值,给分类误差率较大的基分类器以小的权重值;构建的线性组合 为:
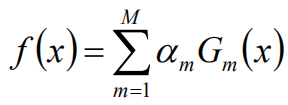
最终分类器是在线性组合的基础上进行Sign函数转换:
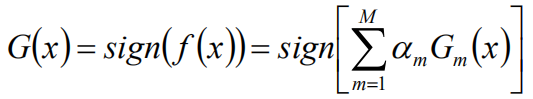
AdaBoost总结
AdaBoost的优点如下:
可以处理连续值和离散值;
模型的鲁棒性比较强;
解释强,结构简单。
AdaBoost的缺点如下:
对异常样本敏感,异常样本可能会在迭代过程中获得较高的权重值,最终影响模型效果
梯度提升迭代决策树GBDT
GBDT也是Boosting算法的一种,但是和AdaBoost算法不同;区别如下:AdaBoost算法是利用前一轮的弱学习器的误差来更新样本权重值,然后一轮一轮的迭代;GBDT也是迭代,但是GBDT要求弱学习器必须是CART模型,而且GBDT在模型训练的时候,是要求模型预测的样本损失尽可能的小。
GBDT由三部分构成:DT(Regression Decistion Tree)、GB(Gradient Boosting)和Shrinkage(衰减)
由多棵决策树组成,所有树的结果累加起来就是最终结果
迭代决策树和随机森林的区别:
随机森林使用抽取不同的样本构建不同的子树,也就是说第m棵树的构建和前m-1棵树的结果是没有关系的
迭代决策树在构建子树的时候,使用之前子树构建结果后形成的残差作为输入数据构建下一个子树;然后最终预测的时候按照子树构建的顺序进行预测,并将预测结果相加
GBDT算法原理
给定输入向量X和输出变量Y组成的若干训练样本(X1,Y1),(X2,Y2)......(Xn,Yn),目标是找到近似函数F(X),使得损失函数L(Y,F(X))的损失值最小。
L损失函数一般采用最小二乘损失函数或者绝对值损失函数
可以处理连续值和离散值;
在相对少的调参情况下,模型的预测效果也会不错;
模型的鲁棒性比较强。
GBDT的缺点如下:
由于弱学习器之间存在关联关系,难以并行训练模型。
2. 样例权重:Bagging使用随机抽样,样例的权重;Boosting根据错误率不断的调整样例的权重值,错误率越大则权重越大;
4. 并行计算:Bagging算法可以并行生成各个基模型;Boosting理论上只能顺序生产,因为后一个模型需要前一个模型的结果;
6. Bagging里每个分类模型都是强分类器,因为降低的是方差,方差过高需要降低是过拟合;Boosting里每个分类模型都是弱分类器,因为降低的是偏度,偏度过高是欠拟合。
机器学习:集成学习:随机森林.GBDT的更多相关文章
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestClassifier分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 机器学习之路:python 集成分类器 随机森林分类RandomForestClassifier 梯度提升决策树分类GradientBoostingClassifier 预测泰坦尼克号幸存者
python3 学习使用随机森林分类器 梯度提升决策树分类 的api,并将他们和单一决策树预测结果做出对比 附上我的git,欢迎大家来参考我其他分类器的代码: https://github.com/l ...
- 机器学习--集成学习(Ensemble Learning)
一.集成学习法 在机器学习的有监督学习算法中,我们的目标是学习出一个稳定的且在各个方面表现都较好的模型,但实际情况往往不这么理想,有时我们只能得到多个有偏好的模型(弱监督模型,在某些方面表现的比较好) ...
- 机器学习——集成学习(Bagging、Boosting、Stacking)
1 前言 集成学习的思想是将若干个学习器(分类器&回归器)组合之后产生一个新学习器.弱分类器(weak learner)指那些分类准确率只稍微好于随机猜测的分类器(errorrate < ...
- [机器学习]集成学习--bagging、boosting、stacking
集成学习简介 集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务. 如何产生"好而不同"的个体学习器,是集成学习研究的核心. 集成学习的思路是通过 ...
- python大战机器学习——集成学习
集成学习是通过构建并结合多个学习器来完成学习任务.其工作流程为: 1)先产生一组“个体学习器”.在分类问题中,个体学习器也称为基类分类器 2)再使用某种策略将它们结合起来. 通常使用一种或者多种已有的 ...
- 机器学习——集成学习之Boosting
整理自: https://blog.csdn.net/woaidapaopao/article/details/77806273?locationnum=9&fps=1 AdaBoost GB ...
- Python数据科学手册-机器学习: 决策树与随机森林
无参数 算法 随机森林 随机森林是一种集成方法,集成多个比较简单的评估器形成累计效果. 导入标准程序库 随机森林的诱因: 决策树 随机森林是建立在决策树 基础上 的集成学习器 建一颗决策树 二叉决策树 ...
随机推荐
- 给EmpMapper开放Restful接口
本文例程下载:https://files.cnblogs.com/files/xiandedanteng/gatling20200428-3.zip 接口控制器代码如下: 请求url和响应都写在了每个 ...
- jzoj1497. 景点中心
Description 话说宁波市的中小学生在镇海中学参加计算机程序设计比赛,比赛之余,他们在镇海中学的各个景点参观.镇海中学共有n个景点,每个景点均有若干学生正在参观.这n个景点以自然数1至n编号, ...
- liunx配置本地yum源和更新aliyun yum源
1.挂载DVD光盘到/mnt 因为配置时候路径名里面不能有空格,否则不能识别 [root@ mnt]# mount /dev/cdrom /mnt [root@ mnt]# umount ...
- pytest文档4-Allure报告清除上一次数据
前言 大家在执行过几次Allure之后就会发现,Allure的报告会把历史的执行结果都展示出来,但实际工作中我们可能只关心本次的结果,解决的话就需要修改一下执行命令了. 问题: 例如图中显示的第一条其 ...
- [LeetCode]1249. 移除无效的括号(字符串,栈)
题目 给你一个由 '('.')' 和小写字母组成的字符串 s. 你需要从字符串中删除最少数目的 '(' 或者 ')' (可以删除任意位置的括号),使得剩下的「括号字符串」有效. 请返回任意一个合法字符 ...
- [程序员代码面试指南]递归和动态规划-机器人达到指定位置方法数(一维DP待做)(DP)
题目描述 一行N个位置1到N,机器人初始位置M,机器人可以往左/右走(只能在位置范围内),规定机器人必须走K步,最终到位置P.输入这四个参数,输出机器人可以走的方法数. 解题思路 DP 方法一:时间复 ...
- matlab外部程序接口-excel
在excel中使用matlab 内容: 1.Spreadsheet Link 程序 安装与启动 1 打开excle->文件->选项 2.加载项->转到 3.浏览(可用加载宏,本来没有 ...
- 3.Scala语法01 - 基础语法
- bellman-ford算法求K短路O(n*m),以及判负环O(n*m)
#include<iostream> #include<algorithm> #include<cstring> using namespace std; cons ...
- Asp.Net Core Log4Net 配置分多个文件记录日志(不同日志级别)
本文所有配置都是在core3.1环境下. 首先看看最终的效果. 请求监控:对每次请求的相关信息做一个记录. 全局异常:我不想我的错误信息,跟其他的信息混合在一起,查看的时候不大方便. 应用日志:这个主 ...