sklearn preprocessing (预处理)
预处理的几种方法:标准化、数据最大最小缩放处理、正则化、特征二值化和数据缺失值处理。
知识回顾:

p-范数:先算绝对值的p次方,再求和,再开p次方。
数据标准化:尽量将数据转化为均值为0,方差为1的数据,形如标准正态分布(高斯分布)。
标准化(Standardization)
公式为:(X-X_mean)/X_std 计算时对每个属性/每列分别进行。
将数据按其属性(按列进行)减去其均值,然后除以其方差。最后得到的结果是,对每个属性/每列来说所有数据都聚集在0附近,方差值为1。
sklearn中preprocessing库里面的scale函数使用方法:
sklearn.preprocessing.scale(X, axis=0, with_mean=True, with_std=True, copy=True)
根据参数不同,可以沿任意轴标准化数据集。
参数:
- X:数组或者矩阵
- axis:int类型,初始值为0,axis用来计算均值和标准方差。如果是0,则单独的标准化每个特征(列),如果是1,则标准化每个观测样本(行)。
- with_mean:boolean类型,默认为True,表示将数据均值规范到0。
- with_std:boolean类型,默认为True,表示将数据方差规范到1。
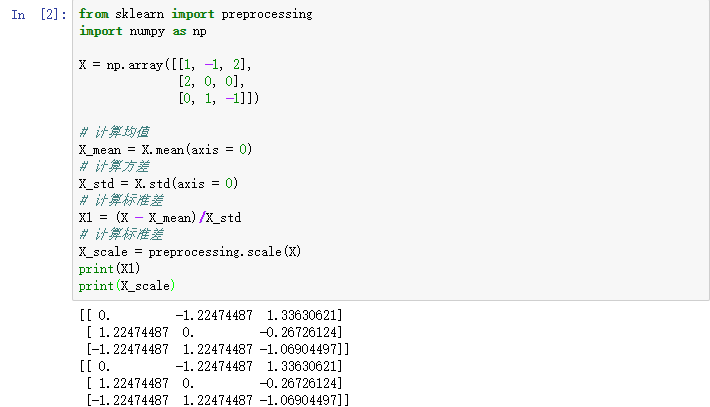
范例:假设现在构造一个数据集X,然后想要将其标准化。
方法一:使用sklearn.preprocessing.scale()函数
方法说明:
- X.mean(axis=0)用来计算数据X每个特征的均值;
- X.std(axis=0)用来计算数据X每个特征的方差;
- preprocessing.scale(X)直接标准化数据X。
方法二:sklearn.preprocessing.StandardScaler类
sklearn.preprocessing.StandardScaler(copy=True, with_mean=True, with_std=True)
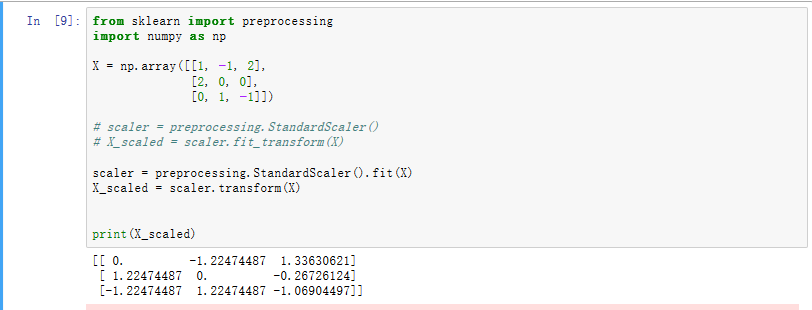
scaler = preprocessing.StandardScaler()
X_scaled = scaler.fit_transform(X)scaler = preprocessing.StandardScaler().fit(X)
X_scaled = scaler.transform(X)
上面两段代码等价。
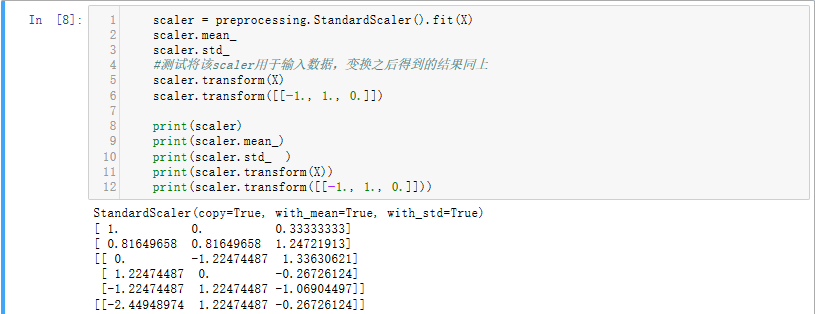
转换器(Transformer)主要有三个方法:
fit():训练算法,拟合数据
transform():标准化数据
fit_transform():先拟合数据,再标准化。
sklearn preprocessing (预处理)的更多相关文章
- 【sklearn】数据预处理 sklearn.preprocessing
数据预处理 标准化 (Standardization) 规范化(Normalization) 二值化 分类特征编码 推定缺失数据 生成多项式特征 定制转换器 1. 标准化Standardization ...
- sklearn学习笔记(一)——数据预处理 sklearn.preprocessing
https://blog.csdn.net/zhangyang10d/article/details/53418227 数据预处理 sklearn.preprocessing 标准化 (Standar ...
- Python数据预处理(sklearn.preprocessing)—归一化(MinMaxScaler),标准化(StandardScaler),正则化(Normalizer, normalize)
关于数据预处理的几个概念 归一化 (Normalization): 属性缩放到一个指定的最大和最小值(通常是1-0)之间,这可以通过preprocessing.MinMaxScaler类实现. 常 ...
- sklearn preprocessing 数据预处理(OneHotEncoder)
1. one hot encoder sklearn.preprocessing.OneHotEncoder one hot encoder 不仅对 label 可以进行编码,还可对 categori ...
- sklearn数据预处理-scale
对数据按列属性进行scale处理后,每列的数据均值变成0,标准差变为1.可通过下面的例子加深理解: from sklearn import preprocessing import numpy as ...
- sklearn数据预处理
一.standardization 之所以标准化的原因是,如果数据集中的某个特征的取值不服从标准的正太分布,则性能就会变得很差 ①函数scale提供了快速和简单的方法在单个数组形式的数据集上来执行标准 ...
- Scikit-learn Preprocessing 预处理
本文主要是对照scikit-learn的preprocessing章节结合代码简单的回顾下预处理技术的几种方法,主要包括标准化.数据最大最小缩放处理.正则化.特征二值化和数据缺失值处理. 数学基础 均 ...
- 数据规范化——sklearn.preprocessing
sklearn实现---归类为5大类 sklearn.preprocessing.scale()(最常用,易受异常值影响) sklearn.preprocessing.StandardScaler() ...
- sklearn 数据预处理1: StandardScaler
作用:去均值和方差归一化.且是针对每一个特征维度来做的,而不是针对样本. [注:] 并不是所有的标准化都能给estimator带来好处. “Standardization of a dataset i ...
随机推荐
- PHP官方文档和phpstorm配置指南
http://cn2.php.net/manual/zh/ phpstorm安装——>next——>…… 下载PHP.exe 地址:http://www.php.net/ 配置interp ...
- Python笔记 #19# 实现bpnn
代码编辑&解释工具:Jupyter Notebook 快速入门 形象说明BP神经网络的用法(图片来自推特): Bpnn类最主要的三个方法: initialize方法,用于设定神经网络的层数.各 ...
- P3380 【模板】二逼平衡树(树套树)(线段树套平衡树)
P3380 [模板]二逼平衡树(树套树) 前置芝士 P3369 [模板]普通平衡树 线段树套平衡树 这里写的是线段树+splay(不吸氧竟然卡过了) 对线段树的每个节点都维护一颗平衡树 每次把给定区间 ...
- oracle merge同时包含增、删、改
原来一直没注意,merge是可以支持delete,只不过必须的是on条件满足,也就是要求系统支持逻辑删除,而非物理删除. Using the DELETE Clause with MERGE Stat ...
- Spring Boot 整合Mybatis非starter时,mapper一直无法注入解决
本来呢,直接使用mybatis-spring-boot-starter还是挺好的,但是我们系统比较复杂,有多个数据源,其中一个平台自己的数据源,另外一些是动态配置出来的,两者完全没有关系.所以直接使用 ...
- Net SMTP QQ 发送邮件
调用DEMO var currUser = new List<string> { "123@qq.com" , "123@qq.com" , &qu ...
- 02: docker高级篇
1.1 Docker Compose 1.Docker Compose 介绍 1. Compose是一个定义和管理多容器的工具,使用Python语言编写. 2. 使用Compose配置文件描述多个容器 ...
- python简说(十三)递归
#递归就是函数自己调用自己count = 0# def abc():# pass# abc()最多循环999次
- sentos7为例添加python3和python2共存
转载:https://www.cnblogs.com/JahanGu/p/7452527.html 1.查看是否已经安装Python CentOS 7.2 默认安装了python2.7.5 因为一些命 ...
- 关于sql中in 和 exists 的效率问题
在用in的地方可以使用freemark标签代替,例如: 将 <#if assistantList??&& (assistantList?size > 0)> AND ...