Python之scrapy框架之post传输数据错误:TypeError: to_bytes must receive a unicode, str or bytes object, got int
错误名:TypeError: to_bytes must receive a unicode, str or bytes object, got int
错误翻译:类型错误:to_bytes必须接收unicode、str或bytes对象,得到int to_bytes也就是需要传给服务器的二进制数据
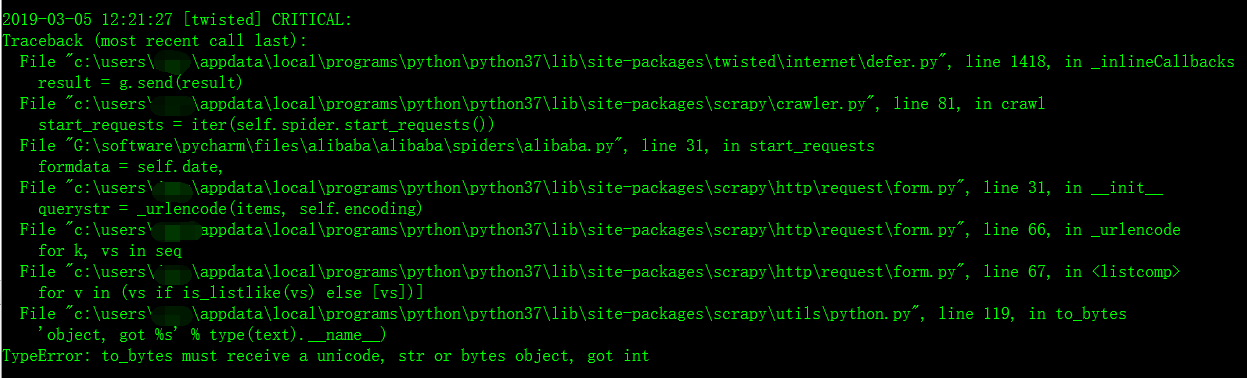
今天我企图用scrapy爬虫框架爬取阿里巴巴以及百度和腾讯的招聘网站的职位信息,在简单的进行数据分析。但是当我在写框架代码时,遇到了一个错误,我找了很久,最后发现只是一个小小的错误,就是字符串的格式出错了,我足足弄了两个小时。唉,真是想骂自己啊。。。
先来上我的错误代码
from lxml import etree
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import Rule,CrawlSpider
from alibaba.items import AlibabaItem
import json
class AlibabaSpider(CrawlSpider):
name = "alibabahr"
allowed_domains = ["alibaba.com"]
def __init__(self,pageIndex): #由于阿里巴巴的限制,他们将职位信息放在了一个json文件中,用js进行数据传输,但是也没有关系,还是一样可以抓取到 下面是json数据抓取的链接URL
self.start_urls = ["https://job.alibaba.com/zhaopin/socialPositionList/doList.json"]
self.pageIndex = pageIndex #这是需要抓取的页数
def start_requests(self):
for page in range(int(self.pageIndex)):
yield scrapy.FormRequest(
url = self.start_urls[0],
callback = self.parse,
formdata = {"pageIndex":page,"pageSize":10}, #因为阿里的一个json文件中,是放10个职位的信息,也就是一页的信息,官网上是一 #页10个职位信息 大家看到那个"pageIndex":page,"pageSize":10 了吗,那个value值在这里是一个int型的数据,但是在进行post数据传输时,scrapy.FormRuquest #这个方法默认是传输字符串的 所以就会报那个错误,我们只需要把那个10和page变成str数据结构就行了。 #将最后那句改成 : formdata = {"pageIndex":str(page),"pageSize":"10"}, 就可以了
)
def parse(self, response):
content = json.loads(response.body)['returnValue']
pageIndex = content['pageIndex']
jobDates = content['datas']
print("pageIndex:" + str(pageIndex))
print(jobDates)
改正错误之后,显示的信息是真确的,如图:

Python之scrapy框架之post传输数据错误:TypeError: to_bytes must receive a unicode, str or bytes object, got int的更多相关文章
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- Python使用Scrapy框架爬取数据存入CSV文件(Python爬虫实战4)
1. Scrapy框架 Scrapy是python下实现爬虫功能的框架,能够将数据解析.数据处理.数据存储合为一体功能的爬虫框架. 2. Scrapy安装 1. 安装依赖包 yum install g ...
- python爬虫scrapy框架
Scrapy 框架 关注公众号"轻松学编程"了解更多. 一.简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量 ...
- Python爬虫Scrapy框架入门(1)
也许是很少接触python的原因,我觉得是Scrapy框架和以往Java框架很不一样:它真的是个框架. 从表层来看,与Java框架引入jar包.配置xml或.property文件不同,Scrapy的模 ...
- Python爬虫Scrapy框架入门(0)
想学习爬虫,又想了解python语言,有个python高手推荐我看看scrapy. scrapy是一个python爬虫框架,据说很灵活,网上介绍该框架的信息很多,此处不再赘述.专心记录我自己遇到的问题 ...
- 基于python的scrapy框架爬取豆瓣电影及其可视化
1.Scrapy框架介绍 主要介绍,spiders,engine,scheduler,downloader,Item pipeline scrapy常见命令如下: 对应在scrapy文件中有,自己增加 ...
- Python爬虫-- Scrapy框架
Scrapy框架 Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是事件驱动的,并且比较适合异步的代码.对于会阻塞线程的操作包含访问文件.数据库或者Web.产生新的进程并需要 ...
- Python爬虫 ---scrapy框架初探及实战
目录 Scrapy框架安装 操作环境介绍 安装scrapy框架(linux系统下) 检测安装是否成功 Scrapy框架爬取原理 Scrapy框架的主体结构分为五个部分: 它还有两个可以自定义下载功能的 ...
- python安装Scrapy框架
看到自己写的惨不忍睹的爬虫,觉得还是学一下Scrapy框架,停止一直造轮子的行为 我这里是windows10平台,python2和python3共存,这里就写python2.7安装配置Scrapy框架 ...
随机推荐
- DNS BIND之rndc介绍及使用
rndc(Remote Name Domain Controllerr)是一个远程管理bind的工具,通过这个工具可以在本地或者远程了解当前服务器的运行状况,也可以对服务器进行关闭.重载.刷新缓存.增 ...
- php多进程pcntl学习(采集新浪微博)
上面2篇文都简明了多进程中一些需要注意的地方,这次用多进程配合curl_mulit_*来做新浪微博的采集. 先把知识点和值得注意的坑列出 /* 需求:开3个进程,并且模拟多线程来采集新浪微博用户信息, ...
- Cplus Overolad new and delete Operator
思考:在C++类中,通过设计类的构造和析构函数,就已经把复杂的内存管理起来了. 及时是简单的结构体,也是有构造和析构函数的,而下面这种情况,可以在非结构中使用. /** Operator Overlo ...
- kaggle-泰坦尼克号Titanic-3
根据以上两篇的分析,下面我们还要对数据进行处理,观察Age和Fare两个属性,乘客的数值变化幅度较大!根据逻辑回归和梯度下降的了解,如果属性值之间scale差距较大,将对收敛速度造成较大影响,甚至不收 ...
- swift 动画
// // ViewController.swift // Anamation // // Created by su on 15/12/9. // Copyright © 2015年 tia ...
- 跳转AppStore 评分
-(void)goToAppStore { NSString *str = [NSString stringWithFormat: @"itms-apps://ax.itunes.apple ...
- string 转换为枚举对应的值
public static Object Parse(Type enumType,string value) 例如:(Colors)Enum.Parse(typeof(Colors), "R ...
- OpenGL中的像素包装理解
OpenGL中的像素包装理解 像素包装 位图和像素图很少会被紧密包装到内存中.在许多硬件平台上,考虑到性能的原因位图和像素图的每一行的数据会从特殊的字节对齐地址开始.绝大多数编译 器会自动把变量和缓冲 ...
- Struts+Spring+Hibernate整合
这段笔记三两年前写的,一直因为一些琐事,或者搞忘记了,没有发.今天偶然翻出了它,就和大家一起分享下吧. 1.导入jar包 Struts的jar包: Spring的jar包: Hibernate的jar ...
- [Erlang36]kerl轻松管理安装各种OTP版本
kerl只有一个目标:让我们在不同的OTP版本间随意切换.他是一个纯Bash项目.简单实用的工作利器! Readme里面用法已说明得非常清楚了.建议按流程来一次. 1.下载 安装(一个bash脚本,根 ...