Python之scrapy框架之post传输数据错误:TypeError: to_bytes must receive a unicode, str or bytes object, got int
错误名:TypeError: to_bytes must receive a unicode, str or bytes object, got int
错误翻译:类型错误:to_bytes必须接收unicode、str或bytes对象,得到int to_bytes也就是需要传给服务器的二进制数据
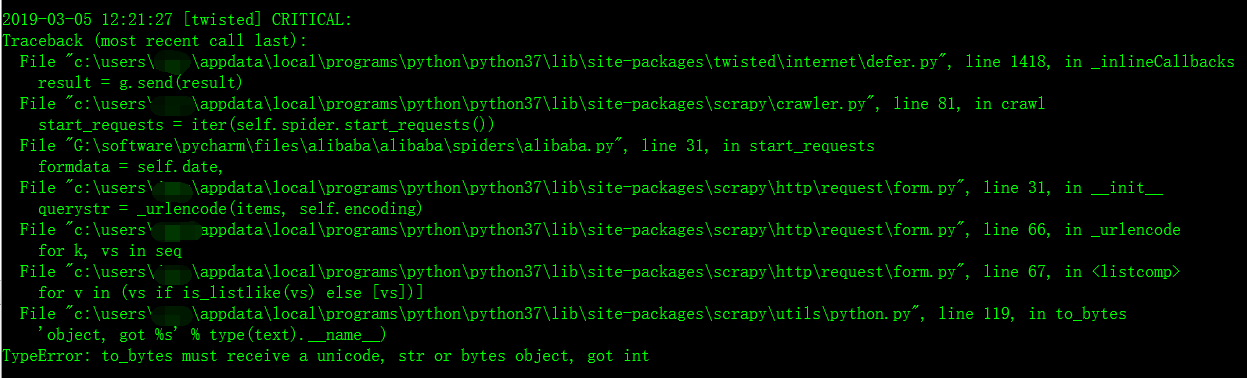
今天我企图用scrapy爬虫框架爬取阿里巴巴以及百度和腾讯的招聘网站的职位信息,在简单的进行数据分析。但是当我在写框架代码时,遇到了一个错误,我找了很久,最后发现只是一个小小的错误,就是字符串的格式出错了,我足足弄了两个小时。唉,真是想骂自己啊。。。
先来上我的错误代码
from lxml import etree
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import Rule,CrawlSpider
from alibaba.items import AlibabaItem
import json
class AlibabaSpider(CrawlSpider):
name = "alibabahr"
allowed_domains = ["alibaba.com"]
def __init__(self,pageIndex): #由于阿里巴巴的限制,他们将职位信息放在了一个json文件中,用js进行数据传输,但是也没有关系,还是一样可以抓取到 下面是json数据抓取的链接URL
self.start_urls = ["https://job.alibaba.com/zhaopin/socialPositionList/doList.json"]
self.pageIndex = pageIndex #这是需要抓取的页数
def start_requests(self):
for page in range(int(self.pageIndex)):
yield scrapy.FormRequest(
url = self.start_urls[0],
callback = self.parse,
formdata = {"pageIndex":page,"pageSize":10}, #因为阿里的一个json文件中,是放10个职位的信息,也就是一页的信息,官网上是一 #页10个职位信息 大家看到那个"pageIndex":page,"pageSize":10 了吗,那个value值在这里是一个int型的数据,但是在进行post数据传输时,scrapy.FormRuquest #这个方法默认是传输字符串的 所以就会报那个错误,我们只需要把那个10和page变成str数据结构就行了。 #将最后那句改成 : formdata = {"pageIndex":str(page),"pageSize":"10"}, 就可以了
)
def parse(self, response):
content = json.loads(response.body)['returnValue']
pageIndex = content['pageIndex']
jobDates = content['datas']
print("pageIndex:" + str(pageIndex))
print(jobDates)
改正错误之后,显示的信息是真确的,如图:

Python之scrapy框架之post传输数据错误:TypeError: to_bytes must receive a unicode, str or bytes object, got int的更多相关文章
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- Python使用Scrapy框架爬取数据存入CSV文件(Python爬虫实战4)
1. Scrapy框架 Scrapy是python下实现爬虫功能的框架,能够将数据解析.数据处理.数据存储合为一体功能的爬虫框架. 2. Scrapy安装 1. 安装依赖包 yum install g ...
- python爬虫scrapy框架
Scrapy 框架 关注公众号"轻松学编程"了解更多. 一.简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量 ...
- Python爬虫Scrapy框架入门(1)
也许是很少接触python的原因,我觉得是Scrapy框架和以往Java框架很不一样:它真的是个框架. 从表层来看,与Java框架引入jar包.配置xml或.property文件不同,Scrapy的模 ...
- Python爬虫Scrapy框架入门(0)
想学习爬虫,又想了解python语言,有个python高手推荐我看看scrapy. scrapy是一个python爬虫框架,据说很灵活,网上介绍该框架的信息很多,此处不再赘述.专心记录我自己遇到的问题 ...
- 基于python的scrapy框架爬取豆瓣电影及其可视化
1.Scrapy框架介绍 主要介绍,spiders,engine,scheduler,downloader,Item pipeline scrapy常见命令如下: 对应在scrapy文件中有,自己增加 ...
- Python爬虫-- Scrapy框架
Scrapy框架 Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是事件驱动的,并且比较适合异步的代码.对于会阻塞线程的操作包含访问文件.数据库或者Web.产生新的进程并需要 ...
- Python爬虫 ---scrapy框架初探及实战
目录 Scrapy框架安装 操作环境介绍 安装scrapy框架(linux系统下) 检测安装是否成功 Scrapy框架爬取原理 Scrapy框架的主体结构分为五个部分: 它还有两个可以自定义下载功能的 ...
- python安装Scrapy框架
看到自己写的惨不忍睹的爬虫,觉得还是学一下Scrapy框架,停止一直造轮子的行为 我这里是windows10平台,python2和python3共存,这里就写python2.7安装配置Scrapy框架 ...
随机推荐
- PHP GD库
<?php $file = '12.jpg'; //打开图片 $im = imagecreatefromjpeg($file); //设置水印字体颜色 $color = imagecoloral ...
- linux下的shell运算(加、减、乘、除
linux下的shell运算(加.减.乘.除 摘自:https://blog.csdn.net/hxpjava1/article/details/80719112 2018年06月17日 16:03: ...
- Servlet.service() for servlet UserServlet threw exception java.lang.NullPointerException 空指针异常
错误付现: 严重: Servlet.service() for servlet UserServlet threw exceptionjava.lang.NullPointerException at ...
- context:propertyPlaceholder
Activates replacement of ${...} placeholders by registering a PropertySourcesPlaceholderConfigurer w ...
- ORA-00054、ORA-08002
https://docs.oracle.com/cd/B10501_01/server.920/a96525/e7500.htm ORA-00054 resource busy and acquire ...
- Zookeeper客户端cli_st为何在crontab中运行不正常?
实践中,发现直接在命令行终端运行cli_st时,能够得到预期的结果,但一将它放到crontab中,则只收到: bye 相关的一段clit_st源代码如下: if (FD_ISSET(, &rf ...
- iOS7修改UISearchBar的Cancel按钮的颜色和文字
两行代码搞定: [[UIBarButtonItem appearanceWhenContainedIn: [UISearchBar class], nil] setTintColor:[UIColor ...
- swift 学习之 UIAlertViewController
// // PushViewController.swift // tab // // Created by su on 15/12/7. // Copyright © 2015年 tian. ...
- (转)【经验之谈】Git使用之TortoiseGit配置VS详解
原文地址:http://www.cnblogs.com/xishuai/p/3590705.html 前言 上一篇<[经验之谈]Git使用之Windows环境下配置>: 安装 配置和使用 ...
- user_mongo_in_a_docker_and_dump_database
使用 mongo docker 镜像 使用 mongo 镜像是很方便的,直接使用官方镜像就好了,为了今后更方便使用,这里给出依据 restheart-docker 中的 docker-compose. ...