A Statistical View of Deep Learning (II): Auto-encoders and Free Energy
A Statistical View of Deep Learning (II): Auto-encoders and Free Energy
With the success of discriminative modelling using deep feedforward neural networks (or using an alternative statistical lens, recursive generalised linear models) in numerous industrial applications, there is an increased drive to produce similar outcomes with unsupervised learning. In this post, I'd like to explore the connections between denoising auto-encoders as a leading approach for unsupervised learning in deep learning, and density estimation in statistics. The statistical view I'll explore casts learning in denoising auto-encoders as that of inference in latent factor (density) models. Such a connection has a number of useful benefits and implications for our machine learning practice.
Generalised Denoising Auto-encoders
Denoising auto-encoders are an important advancement in unsupervised deep learning, especially in moving towards scalable and robust representations of data. For every data point y, denoising auto-encoders begin by creating a perturbed version of it y', using a known corruption process C(y′|y). We then create a network that given the perturbed data y', reconstructs the original data y. The network is grouped into two parts, an encoder and a decoder, such that the output of the encoder z can be used as a representation/features of the data. The objective function is [1]:
where logp(⋅) is an appropriate likelihood function for the data, and the objective function is averaged over all observations. Generalised denoising auto-encoders (GDAEs) realise that this formulation may be limited due to finite training data, and introduce an additional penalty term R(⋅) for added regularisation [2]:
GDAEs exploit the insight that perturbations in the observation space give rise to robustness and insensitivity in the representation z. Two key questions that arise when we use GDAEs are: how to choose a realistic corruption process, and what are appropriate regularisation functions.
Separating Model and Inference
The difficulty in reasoning statistically about auto-encoders is that they do not maintain or encourage a distinction between a model of the data (statistical assumptions about the properties and structure we expect) and the approach for inference/estimation in that model (the ways in which we link the observed data to our modelling assumptions). The auto-encoder framework provides a computational pipeline, but not a statistical explanation, since to explain the data (which must be an outcome of our model), you must know it beforehand and use it as an input. Not maintaining the distinction between model and inference impedes our ability to correctly evaluate and compare competing approaches for a problem, leaves us unaware of relevant approaches in related literatures that could provide useful insight, and makes it difficult for us to provide the guidance that allows our insights to be incorporated into our community's broader knowledge-base.
To ameliorate these concerns we typically re-interpret the auto-encoder by seeing thedecoder as the statistical model of interest (and is indeed how many interpret and use auto-encoders in practice). A probabilistic decoder provides a generative description of the data, and our task is inference/learning in this model. For a given model, there are many competing approaches for inference, such as maximum likelihood (ML) andmaximum a posteriori (MAP) estimation, noise-contrastive estimation, Markov chain Monte Carlo (MCMC), variational inference, cavity methods, integrated nested Laplace approximations (INLA), etc. The role of the encoder is now clear: the encoder is one mechanism for inference in the model described by the decoder. Its structure is not tied to the model (decoder), and it is just one from the smorgasbord of available approaches with its own advantages and tradeoffs.
Approximate Inference in Latent Variable Models
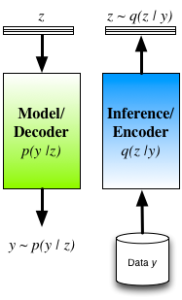
Encoder-decoder view of inference in latent variable models.
Another difficulty with DAEs is that robustness is obtained by considering perturbations in the data space — such a corruption process will, in general, not be easy to design. Furthermore, by carefully reasoning about the induced probabilities, we can show [1] that the DAE objective function LDAE corresponds to a lower bound obtained by applying the variational principle to the log-density of the corrupted data logp(y′) — this though, is nota quantity we are interested in reasoning about.
A way forward would be to instead apply the variational principle to the quantity we are interested in, the log-marginal probability of the observed data logp(y) [3][4]. The objective function obtained by applying the variational principle to the generative model (probabilistic decoder) is known as the variational free energy:
By inspection, we can see that this matches the form of the GDAE objective. There are notable differences though:
- Instead of considering perturbations in the observation space, we consider perturbations in the hidden space, obtained by using a prior p(z). The hidden variables are now random, latent variables. Auto-encoders are now generative models that are straightforward to sample from.
- The encoder q(z|y) is a mechanism for approximating the true posterior distribution of the latent/hidden variables p(z|y).
- We are now able to explain the introduction of the penalty function in the GDAE objective in a principled manner. Rather than designing the penalty by hand, we are able to derive the form this penalty should take, appearing as the KL divergence between the the prior and the encoder distribution.
Auto-encoders reformulated in this way, thus provide an efficient way of implementing approximate Bayesian inference. Using an encoder-decoder structure, we gain the ability to jointly optimise all parameters using the single computational graph; and we obtain an efficient way of doing inference at test time, since we only need a single forward pass through the encoder. The cost of taking this approach is that we have now obtained a potentially harder optimisation, since we have coupled the inferences for the latent variables together through the parameters of the encoder. Approaches that do not implement the q-distribution as an encoder have the ability to deal with arbitrary missingness patterns in the observed data and we lose this ability, since the encoder must be trained knowing the missingness pattern it will encounter. One way we explored these connections is in a model we called Deep Latent Gaussian Models (DLGM) with inference based on stochastic variational inference (and implemented using an encoder) [3], and is now the basis of a number of extensions [5][6].
Summary
Auto-encoders address the problem of statistical inference and provide a powerful mechanism for inference that plays a central role in our search for more powerful unsupervised learning. A statistical view, and variational reformulation, of auto-encoders allows us to maintain a clear distinction between the assumed statistical model and our approach for inference, gives us one efficient way of implementing inference, gives us an easy-to-sample generative model, allows us to reason about the statistical quantity we are actually interested in, and gives us a principled loss function that includes the important regularisation terms. This is just one perspective that is becoming increasingly popular, and is worthwhile to reflect upon as we continue to explore the frontiers of unsupervised learning.
Some References
| [1] | Pascal Vincent, Hugo Larochelle, Yoshua Bengio, Pierre-Antoine Manzagol,Extracting and composing robust features with denoising autoencoders, Proceedings of the 25th international conference on Machine learning, 2008 |
| [2] | Yoshua Bengio, Li Yao, Guillaume Alain, Pascal Vincent, Generalized denoising auto-encoders as generative models, Advances in Neural Information Processing Systems, 2013 |
| [3] | Danilo Jimenez Rezende, Shakir Mohamed, Daan Wierstra, Stochastic Backpropagation and Approximate Inference in Deep Generative Models, Proceedings of The 31st International Conference on Machine Learning, 2014 |
| [4] | Diederik P Kingma, Max Welling, Auto-encoding variational bayes, arXiv preprint arXiv:1312.6114, 2014 |
| [5] | Diederik P Kingma, Shakir Mohamed, Danilo Jimenez Rezende, Max Welling, Semi-supervised learning with deep generative models, Advances in Neural Information Processing Systems, 2014 |
| [6] | Karol Gregor, Ivo Danihelka, Alex Graves, Daan Wierstra, DRAW: A Recurrent Neural Network For Image Generation, arXiv preprint arXiv:1502.04623, 2015 |
A Statistical View of Deep Learning (II): Auto-encoders and Free Energy的更多相关文章
- A Statistical View of Deep Learning (V): Generalisation and Regularisation
A Statistical View of Deep Learning (V): Generalisation and Regularisation We now routinely build co ...
- A Statistical View of Deep Learning (IV): Recurrent Nets and Dynamical Systems
A Statistical View of Deep Learning (IV): Recurrent Nets and Dynamical Systems Recurrent neural netw ...
- A Statistical View of Deep Learning (III): Memory and Kernels
A Statistical View of Deep Learning (III): Memory and Kernels Memory, the ways in which we remember ...
- A Statistical View of Deep Learning (I): Recursive GLMs
A Statistical View of Deep Learning (I): Recursive GLMs Deep learningand the use of deep neural netw ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料【转】
转自:机器学习(Machine Learning)&深度学习(Deep Learning)资料 <Brief History of Machine Learning> 介绍:这是一 ...
- 【深度学习Deep Learning】资料大全
最近在学深度学习相关的东西,在网上搜集到了一些不错的资料,现在汇总一下: Free Online Books by Yoshua Bengio, Ian Goodfellow and Aaron C ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 2)
##机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 2)---#####注:机器学习资料[篇目一](https://github.co ...
- translation of 《deep learning》 Chapter 1 Introduction
原文: http://www.deeplearningbook.org/contents/intro.html Inventors have long dreamed of creating mach ...
- 深度学习基础 Probabilistic Graphical Models | Statistical and Algorithmic Foundations of Deep Learning
目录 Probabilistic Graphical Models Statistical and Algorithmic Foundations of Deep Learning 01 An ove ...
随机推荐
- EnterpriseArchitectect 软件的勾选的几个选项对应的中文意思
Business Process 业务流程 Requirements 需求分析 Use Case 用例 Domain Model 领域模型 Class 类 Database 数据库设计 Compone ...
- MST(Kruskal’s Minimum Spanning Tree Algorithm)
You may refer to the main idea of MST in graph theory. http://en.wikipedia.org/wiki/Minimum_spanning ...
- Rebuild my Ubuntu 分类: ubuntu shell 2014-11-08 18:23 193人阅读 评论(0) 收藏
全盘格式化,重装了Ubuntu和Windows,记录一下重新配置Ubuntu过程. //build-essential sudo apt-get install build-essential sud ...
- Android 图标上面添加提醒(二)使用开源UI类库 Viewbadger
版权声明:本文为博主原创文章,未经博主允许不得转载. 上一篇讲到用canvas进行绘制得到对应最终的bitmap. 在实际应用中,我们除了给图标添加数字外,也有可能加一些红色方块之类的图标作为新功能的 ...
- MySQL内存体系架构及参数总结 ---图解
http://www.cnblogs.com/kissdb/p/4009614.html 内存结构: Mysql 内存分配规则是:用多少给多少,最高到配置的值,不是立即分配 图只做大概参考 全局缓存包 ...
- spring mvc DispatcherServlet详解之一---处理请求深入解析(续)
上文中,我们知道分发过程有以下步骤: 分发过程如下: 1. 判断是否设置了multipart resolver,设置的话转换为multipart request,没有的话则继续下面的步骤. 2. 根据 ...
- 基于HTML5的SLG游戏开发( 二):创建HTML5页面
HTML5游戏的开发过程中是在浏览器上进行运行调试的,所以首先我们需要建立一个html页面. 其中,我们把所有的canvas都放到一个viewporter(视图)里面,因此,在body中放置了一个id ...
- windows 与Linux 互传文件
下载putty,将putty的安装路径添加到Windows的环境变量中: 我的电脑->属性->高级->环境变量->系统变量,双击其中的Path,在分号后添加putty的 ...
- Java中泛型 问号的作用
这是jdk1.5泛型的典型应用: 第一种写法,叫做使用泛型方法: public <T extends Object> void thisIsT(List <T> list ...
- IDL通过经纬度定位获取DN值
以前就想写,但是因为envi可以就一直没弄.今天正好有个机会,就做了这个事情.ENVI中在主窗口中pixel locator可以实现,但是当我们需要读入很多的数据的时候,也就是批量处理的时候,显然编程 ...