金融量化之Tushare模块
一、介绍
Tushare是一个免费、开源的python财经数据接口包。主要实现对股票等金融数据从数据采集、清洗加工 到 数据存储的过程,能够为金融分析人员提供快速、整洁、和多样的便于分析的数据,为他们在数据获取方面极大地减轻工作量,使他们更加专注于策略和模型的研究与实现上。考虑到Python pandas包在金融量化分析中体现出的优势,Tushare返回的绝大部分的数据格式都是pandas DataFrame类型,非常便于用pandas/NumPy/Matplotlib进行数据分析和可视化。当然,如果您习惯了用Excel或者关系型数据库做分析,您也可以通过Tushare的数据存储功能,将数据全部保存到本地后进行分析。应一些用户的请求,从0.2.5版本开始,Tushare同时兼容Python 2.x和Python 3.x,对部分代码进行了重构,并优化了一些算法,确保数据获取的高效和稳定。
需要强调的是,TuShare库里不仅仅有股票数据,而是一个综合的财经库。只是因为股票数据数据量比较大,特别锻炼数据分析能力,所以才选择股票数据练手。其余的数据也是很有意思的,比如全国电影票房排名
使用前提
- 安装Python
- 安装pandas
- lxml也是必须的,正常情况下安装了Anaconda后无须单独安装,如果没有可执行:pip install lxml
建议安装Anaconda(http://www.continuum.io/downloads),一次安装包括了Python环境和全部依赖包,减少问题出现的几率。
下载安装
- 方式1:pip install tushare
- 方式2:访问https://pypi.python.org/pypi/Tushare/下载安装
版本升级
- pip install tushare --upgrade
查看当前版本的方法:
import tushare
print(tushare.__version__)
二、Tushare的应用
1、概念
1.K线:K线起源于日本德川幕府时代,因为图形像蜡烛,所以又称蜡烛图,日本线。K线是代表这一天股票的开盘价,收盘价,最高价和最低价。
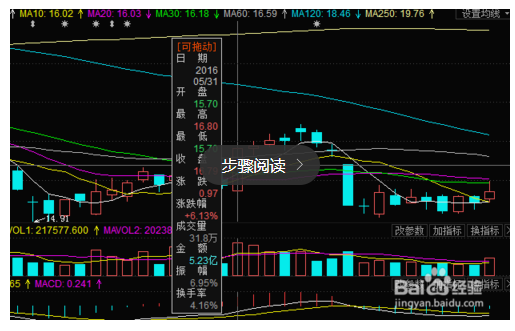
2.均线:均线一般分为5日(MA5),10日(MA10),20日(MA20),30日(MA30),60日(MA60),120日(MA120)和250日平均线(MA250),它指的是在这些天里这个股票收盘的平均价格,通过K线与均线的对比可以看出股票的强弱,一般在5日均线以上属于较强势。
2、获取股票行情的函数
我们主要还是应该掌握如何用tushare获取股票行情数据,使用的是ts.get_hist_data()函数或者ts.get_k_data()函数
参数:
code:股票代码,即6位数字代码,或者指数代码(sh=上证指数 sz=深圳成指 hs300=沪深300指数 sz50=上证50 zxb=中小板 cyb=创业板) start:开始日期,格式YYYY-MM-DD end:结束日期,格式YYYY-MM-DD ktype:数据类型,D=日k线 W=周 M=月 5=5分钟 15=15分钟 30=30分钟 60=60分钟,默认为D retry_count:当网络异常后重试次数,默认为3 pause:重试时停顿秒数,默认为0
返回值说明: date:日期 open:开盘价 high:最高价 close:收盘价 low:最低价 volume:成交量 price_change:价格变动 p_change:涨跌幅 ma5:5日均价 ma10:10日均价 ma20:20日均价 v_ma5:5日均量 v_ma10:10日均量 v_ma20:20日均量 turnover:换手率[注:指数无此项]
3、案例
import pandas as pd
import numpy as np
from pandas import DataFrame,Series
import tushare as ts # 获取k线数据,加载至DataFrame中
df = ts.get_k_data('',start='2000-01-01') # 茅台
df.head() # 将从Tushare中获取的数据存储至本地
df.to_csv('./maotai.csv') # 将原数据中的时间作为行索引,并将字符串类型的时间序列化成时间对象类型
# index_col参数:把某一列col作为行索引index
# parse_dates:把字符串类型的时间序列化成时间对象类型
df = pd.read_csv('./maotai.csv',index_col='date',parse_dates=['date'])
df.drop(labels='Unnamed: 0',axis=1,inplace=True)
df.head() # 分析1:输出该股票所有收盘比开盘上涨3%以上的日期
# 获取满足条件的行索引
df.loc[(df['close'] - df['open'])/df['open'] > 0.03].index # 分析2:输出该股票所有开盘比前日收盘跌幅超过2%的日期
df.loc[(df['open'] - df['close'].shift(1)) / df['close'].shift(1) <= -0.02].index # 分析3:假如我从2010年1月1日开始,每月第一个交易日买入1手股票,每年最后一个交易日卖出所有股票,到今天为止,我的收益如何
price_last = df['open'][-1]
df = df['2010-01':'2019-01'] # 剔除首尾无用的数据
# Pandas提供了resample函数用便捷的方式对时间序列进行重采样,根据时间粒度的变大或者变小分为降采样和升采样:
df_monthly = df.resample("M").first() # 获取每月第一个交易日对应的行数据
df_yearly = df.resample("Y").last()[:-1] # 获取每年第最后一个交易日对应的行数据并去除最后一年
cost_money = 0
hold = 0 # 每年持有的股票
for year in range(2010, 2020): cost_money -= df_monthly.loc[str(year)]['open'].sum()*100
hold += len(df_monthly[str(year)]['open']) * 100
if year != 2019:
cost_money += df_yearly[str(year)]['open'][0] * hold
hold = 0 # 每年持有的股票
cost_money += hold * price_last print(cost_money)
4、双均线策略
概念
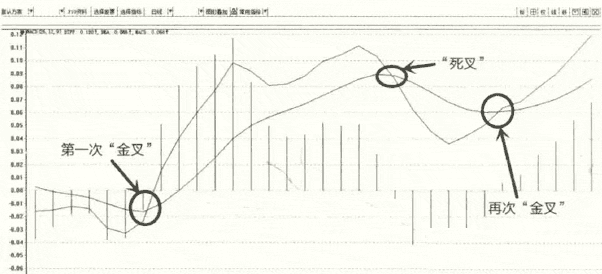
- 金叉:就是指短期的均线向上穿越中期或长期的均线,交点就为金叉,应该买入。
- 死叉:就是指短期的均线向下穿越中期或长期的均线,交点就为死叉,应该卖出。
- 其它指标以此类推
"""
如果我从假如我从2010年1月1日开始,初始资金为100000元,金叉尽量买入,死叉全部卖出,则到今天为止,我的炒股收益率如何?(双均线策略)
""" import tushare as ts
import pandas as pd
import numpy as np
from pandas import DataFrame,Series # 获取k线数据,加载至DataFrame中
df = ts.get_k_data('',start='2000-01-01') # 将从Tushare中获取的数据存储至本地
df.to_csv('./maotai.csv') # 将原数据中的时间作为行索引,并将字符串类型的时间序列化成时间对象类型
# index_col参数:把某一列col作为行索引index
# parse_dates:把字符串类型的时间序列化成时间对象类型
df = pd.read_csv('./maotai.csv',index_col='date',parse_dates=['date'])
df.drop(labels='Unnamed: 0',axis=1,inplace=True) # 获取需要的数据
df = df['':''] # 计算均线
ma5 = df['close'].rolling(5).mean() # 5日均值
ma30 = df['close'].rolling(30).mean() # 30日均值 # 计算出金叉和死叉
s1 = ma5 < ma30
s2 = ma5 > ma30 # 计算金叉死叉图解
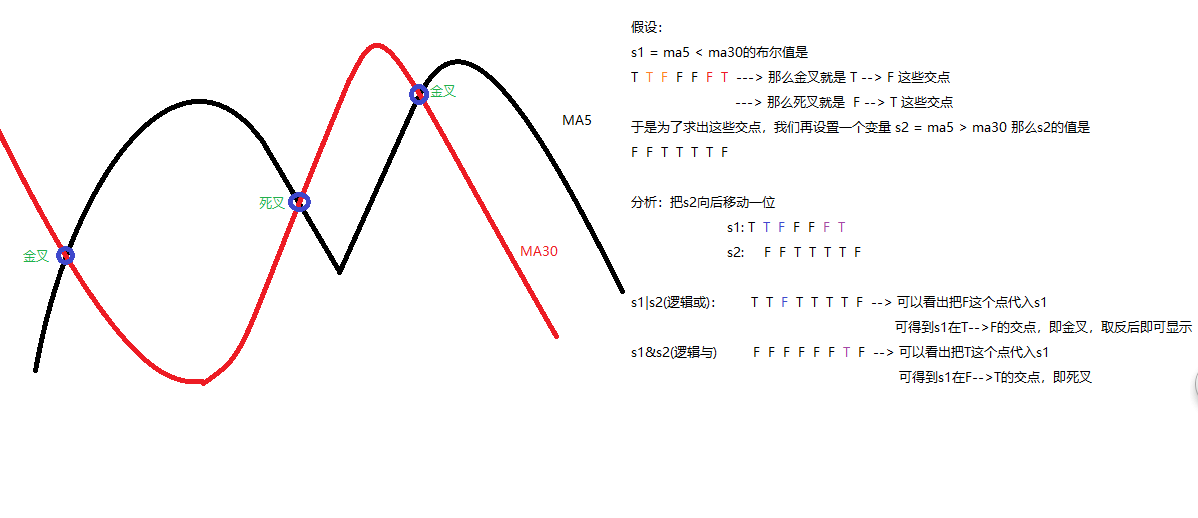
gold = df.loc[~(s1 | s2.shift(1))].index # 金叉
dead = df.loc[s1&s2.shift(1)].index # 死叉 # 计算出结果
first_money = 100000
money = first_money
hold = 0 # 持有多少股
sr1 = Series(1, index=gold) # 把所有金叉点组成一个行索引为金叉日期,值为1的Series数组
sr2 = Series(0, index=dead) # 把所有死叉点组成一个行索引为死叉日期,值为0的Series数组
# 合并金叉死叉,并根据时间排序
sr = sr1.append(sr2).sort_index() for i in range(0, len(sr)):
p = df['open'][sr.index[i]] # sr.index取到Series索引,sr.index[i],第i个索引
if sr.iloc[i] == 1:
# 金叉
buy = (money // (100 * p))
hold += buy*100
money -= buy*100*p
else:
money += hold * p
hold = 0 p = df['open'][-1]
now_money = hold * p + money print(now_money - first_money)
金融量化之Tushare模块的更多相关文章
- 金融量化之tushare模块的使用
一.TuShare简介和环境安装 TuShare是一个著名的免费.开源的python财经数据接口包.其官网主页为:TuShare -财经数据接口包.该接口包如今提供了大量的金融数据,涵盖了股票.基本面 ...
- 金融量化ushare模块
一.介绍 Tushare是一个免费.开源的python财经数据接口包.主要实现对股票等金融数据从数据采集.清洗加工 到 数据存储的过程,能够为金融分析人员提供快速.整洁.和多样的便于分析的数据,为他们 ...
- 1.tushare模块的应用
tushare模块的应用 今日概要 TuShare简介和环境安装 TuShare的应用 今日详情 一.TuShare简介和环境安装 TuShare是一个著名的免费.开源的python财经数据接口包.其 ...
- 金融量化分析【day110】:金融基础知识
一.股票 股票: 股票是股份公司发给出资人的一种凭证,股票的持有者就是股份公司的股东. 股票的面值与市值 面值表示票面金额 市值表示市场价值 上市/IPO: 企业通过证券交易所公开向社会增发股票以募集 ...
- day32 Python与金融量化分析(二)
第一部分:金融与量化投资 股票: 股票是股份公司发给出资人的一种凭证,股票的持有者就是股份公司的股东. 股票的面值与市值 面值表示票面金额 市值表示市场价值 上市/IPO: 企业通过证券交易所公开向社 ...
- day31 堡垒机尾声 + Python与金融量化分析(一)
堡垒机尾声: 代码案例:https://github.com/liyongsan/git_class/tree/master/day31 课堂笔记:file send: 1.选择本地文件 2.远程路径 ...
- 金融量化分析【day112】:股票数据分析Tushare1
目录 1.使用tushare包获取某股票的历史行情数据 2.输出该股票所有收盘比开盘上涨3%以上的日期 3.输出该股票所有开盘比前日收盘跌幅超过2%的日期 4.假如我从2010年1月1日开始,每月第一 ...
- Python与金融量化分析----金融与量化投资
一:金融了解 金融:就是对现有资源进行重新的整合之后,进行价值和利润的等效流通. 金融工具: 股票 期货 黄金 外汇 基金 ............. 股票: 股票是股份公司发给出资人多的一种凭证,股 ...
- Tushare模块
.TuShare简介和环境安装 TuShare是一个著名的免费.开源的python财经数据接口包.其官网主页为:TuShare -财经数据接口包.该接口包如今提供了大量的金融数据,涵盖了股票.基本面. ...
随机推荐
- 一句话总结kNN算法
一句话总结kNN算法 核心:模板匹配,将样本分到离它最相似的样本所属的类. kNN算法本质上使用了模板匹配的思想.要确定一个样本的类别,可以计算它与所有训练样本的距离,然后找出和该样本最接近的k个样本 ...
- jquery获取内容和属性的方法
通过jquery如何捕获文本内容和属性? text(),html(),val()及attr(). attr()更具有普遍性,元素text属性和表单value属性,可以通过attr()操作. <! ...
- git rebase 使用详解
rebase 假设你现在基于远程分支"origin",创建一个叫"mywork"的分支. $ git checkout -b mywork origin 现 ...
- ERROR 1071 (42000): Specified key was too long; max key length is 767 bytes
今天在MySQL 5.6版本的数据库中修改InnoDB表字段长度时遇到了"ERROR 1071 (42000): Specified key was too long; max key le ...
- sql order by和case THEN 并用
今天在工作中遇到一个多表查询,并且按精准度匹配排序的一个需求,费了我好大劲在此和大家分享一些心得 开始我是想根据他的搜索字段的长度来排序,但是遇到图二的这种结果就不好排序了 order by abs( ...
- 尝试Java,从入门到Kotlin(上)
之前一直使用C#开发,最近由于眼馋Java生态环境,并借着工作服务化改造的契机,直接将新项目的开发都转到Java上去.积攒些Java开发经验,应该对.NET开发也会有所启发和益处. 从理论上说,Jav ...
- win8.1 AMD 屏幕亮度无法调整
lenovo z465 AMD处理器. win8.1 pro系统 屏幕亮度无法调整解决办法: 1:当然是先去本地服务里禁用"Sensor Monitoring Service&qu ...
- SSH远程登录原理
使用ssh主要有两种登录方式:第一种为密码口令登录,第二种为公钥登录 密码口令登录 通过密码进行登录,主要流程为: 1.客户端连接上服务器之后,服务器把自己的公钥传给客户端 2.客户端输入服务器密码通 ...
- hrbust1140 数字和问题
题目: 定义一种操作为:已知一个数字,对其各位数字反复求和,直到剩下的数是一位数不能求和为止.例如:数字2345,第一次求和得到2 + 3 + 4 + 5 = 14,再对14的各位数字求和得到1 + ...
- 1.1 NCE21 Daniel Mendoza
1.text translation Two hundred years ago, boxing matches were very popular in England. At that time/ ...