CUDA[2] Hello,World
Section 0:Hello,World
这次我们亲自尝试一下如何用粗(CU)大(DA)写程序
CUDA最新版本是7.5,然而即使是最新版本也不兼容VS2015 。。。推荐使用VS2012
进入VS2012,新建工程,选择NVIDIA--CUDA Runtime
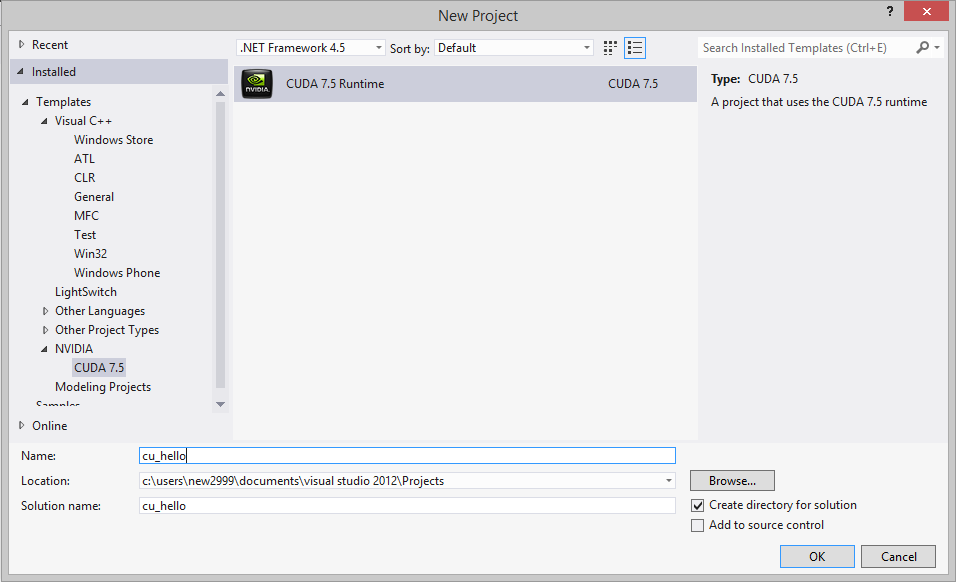
我们来写一个简单的向量加法程序:[Reference]
#include <stdio.h> __global__ void saxpy(int n, float a, float *x, float *y)
//__global__关键字,表示是将要在GPU里并行运行的核函数
{
int i = blockIdx.x*blockDim.x + threadIdx.x;
if (i < n)
y[i] = a*x[i] + y[i];
} int main()
{
int N = ;
float *x, *y, *d_x, *d_y; //都是指针,指向数组所在的内存/显存空间
x = (float*)malloc(N*sizeof(float)); //在内存中为x,y分配空间
y = (float*)malloc(N*sizeof(float)); cudaMalloc(&d_x, N*sizeof(float)); //在显存中为d_x,d_y分配空间
cudaMalloc(&d_y, N*sizeof(float)); for (int i = ; i < N; i++)
{
x[i] = (float)i;
y[i] = 2.0f;
} cudaMemcpy(d_x, x, N*sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(d_y, y, N*sizeof(float), cudaMemcpyHostToDevice);
//将内存中x,y指向的数组空间拷贝到显存中d_x,d_y指向的数组空间 saxpy<<<,N>>>(N, 10.0f, d_x, d_y);
//1个block,每个block里N个thread cudaMemcpy(y, d_y, N*sizeof(float), cudaMemcpyDeviceToHost);
//将显存中计算好的d_y指向的数组空间拷贝到内存中y指向的数组空间 for (int i = ; i < N; i++)
printf("%d %.3f\n",i,y[i]); getchar();
}
运行后就会出结果啦~
Section 1:一个好一点的代码风格
虽然刚才的程序已经能运行了,但是讲道理的话把所有的代码都写到cu文件里是很屎的风格。。。
下面再来写一个向量加法的程序:[Ref]
/* kernel.cu */
//cuda系函数必须放在cu文件里
#include "cuda_runtime.h"
#include "device_launch_parameters.h" #include <stdio.h> __global__ void addKernel(int *c, const int *a, const int *b)
{
int i = threadIdx.x;
c[i] = a[i] + b[i];
} //cpp中不能直接调用核函数,所以在cu文件中还得写一个接口,负责分配内存等
void addWithCuda(int *c, const int *a, const int *b, unsigned int size)
{
int *dev_a = ;
int *dev_b = ;
int *dev_c = ; // Choose which GPU to run on, change this on a multi-GPU system.
cudaSetDevice(); // Allocate GPU buffers for three vectors (two input, one output) .
cudaMalloc((void**)&dev_c, size * sizeof(int));
cudaMalloc((void**)&dev_a, size * sizeof(int));
cudaMalloc((void**)&dev_b, size * sizeof(int)); // Copy input vectors from host memory to GPU buffers.
cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice); // Launch a kernel on the GPU with one thread for each element.
addKernel<<<, size>>>(dev_c, dev_a, dev_b); // Copy output vector from GPU buffer to host memory.
cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost); cudaFree(dev_c);
cudaFree(dev_a);
cudaFree(dev_b);
cudaDeviceReset();
} //-------------------------------------------------------------------------------
/* Source.cpp */
#include"cstdio"
#include"cstring" extern void addWithCuda(int *c, const int *a, const int *b, unsigned int size);
//.cpp是由C编译器来编译的。C编译器里不允许#include一个cu文件(不资词)
//若要引用cu里的函数,在main.cpp里外部extern声明一下,让VS转为NVCC编译器处理。 int main()
{
const int arraySize = ;
const int a[arraySize] = { , , , , };
const int b[arraySize] = { , , , , };
int c[arraySize] = { }; addWithCuda(c, a, b, arraySize); printf("{1,2,3,4,5} + {10,20,30,40,50} = {%d,%d,%d,%d,%d}\n",
c[], c[], c[], c[], c[]); getchar(); return ;
}
补充:对于一些计算量较大(GPU计算时间较长)的程序,有可能运行很短时间之后就崩溃掉,并出现“显卡驱动已停止”的提示。
这是因为驱动程序默认认为GPU只负责图形计算任务,如果有任务长时间占用GPU就会自动terminate掉。
解决方法如下:[Ref]
进入注册表->HKEY_LOCAL_MACHINE->System->CurrentControlSet->Control->GraphicsDrivers
新建DWORD键TdrLevel,键值为0。保存重启即可。
Section 2:还是要学习一个
下面系统介绍一下粗大里的关键字和规则:
[Ref]
__global__:kernel函数。在device(GPU)里运行。可以在host(CPU处的主程序)调用
__device__:只允许在device运行,在device调用
__constant__:constant memory,表示常量
__shared__:shared memory,block内共享的变量
CUDA[2] Hello,World的更多相关文章
- CUDA[1] Introductory
Section 0 :Induction of CUDA CUDA是啥?CUDA®: A General-Purpose Parallel Computing Platform and Program ...
- Couldn't open CUDA library cublas64_80.dll etc. tensorflow-gpu on windows
I c:\tf_jenkins\home\workspace\release-win\device\gpu\os\windows\tensorflow\stream_executor\dso_load ...
- ubuntu 16.04 + N驱动安装 +CUDA+Qt5 + opencv
Nvidia driver installation(after download XX.run installation file) 1. ctrl+Alt+F1 //go to virtual ...
- 手把手教你搭建深度学习平台——避坑安装theano+CUDA
python有多混乱我就不多说了.这个混论不仅是指整个python市场混乱,更混乱的还有python的各种附加依赖包.为了一劳永逸解决python的各种依赖包对深度学习造成的影响,本文中采用pytho ...
- [CUDA] CUDA to DL
又是一枚祖国的骚年,阅览做做笔记:http://www.cnblogs.com/neopenx/p/4643705.html 这里只是一些基础知识.帮助理解DL tool的实现. “这也是深度学习带来 ...
- 基于Ubuntu14.04系统的nvidia tesla K40驱动和cuda 7.5安装笔记
基于Ubuntu14.04系统的nvidia tesla K40驱动和cuda 7.5安装笔记 飞翔的蜘蛛人 注1:本人新手,文章中不准确的地方,欢迎批评指正 注2:知识储备应达到Linux入门级水平 ...
- CUDA程序设计(一)
为什么需要GPU 几年前我启动并主导了一个项目,当时还在谷歌,这个项目叫谷歌大脑.该项目利用谷歌的计算基础设施来构建神经网络. 规模大概比之前的神经网络扩大了一百倍,我们的方法是用约一千台电脑.这确实 ...
- 使用 CUDA范例精解通用GPU编程 配套程序的方法
用vs新建一个cuda的项目,然后将系统自动生成的那个.cu里头的内容,除了头文件引用外,全部替代成先有代码的内容. 然后程序就能跑了. 因为新建的是cuda的项目,所以所有的头文件和库的引用系统都会 ...
- CUDA代码移植
如果CUDA的代码移植,一个是要 include文件夹对不对,这个是.h文件能否找到的关键,另一个就是lib,这个是.lib文件能否找到的关键.具体检查地方,见下头. include: lib:
随机推荐
- JS中的对象
什么事对象?对象是一个整体,对外提供一些操作.而面向对象,就是使用对象时,只关注对象提供的功能,不关注内部的细节,面向对象是一种通用思想. 面向对象编程的特点: 抽象:抓住核心问题: 封装:不考虑内部 ...
- 苹果的MDM简介
MDM(Mobile Device Management)移动设备管理,一般会用于企业管理其移动设备,鉴于iOS是比较封闭的系统很多的功能都难以实现,所以利用苹果的MDM可以达到远程控制设备,像远程定 ...
- GsonFormat插件从配置到使用
说明:目前多数服务器端都以json格式返回,那么相对应的解析时建立的实体类如果你还在自己挨个写的话,那就out了.新建一个类,选择Generate. ------------------------- ...
- iOS 语音朗读
//判断版本大于7.0 if ([[[UIDevice currentDevice] systemVersion] integerValue] >= 7.0) { NSStr ...
- 最快让你上手ReactiveCocoa之基础篇
前言 很多blog都说ReactiveCocoa好用,然后各种秀自己如何灵活运用ReactiveCocoa,但是感觉真正缺少的是一篇如何学习ReactiveCocoa的文章,这里介绍一下. 1.Rea ...
- IT软件技术人员的职位路线(从程序员到技术总监) - 部门管理经验谈
以前写过一个文(IT从业者的职业道路(从程序员到部门经理) - 项目管理系列文章),主要介绍笔者的职业发展之路,不过该文需要后续了,因为笔者现在从事的是“产品经理”一职.从笔者的导航文([置顶]博文快 ...
- mac 抓包工具charles v3.9.3 安装破解步骤
一.下载 先到它的官网http://www.charlesproxy.com/可下载到最新版本,这个下载有点慢,我已经将它放到网盘中了:http://pan.baidu.com/s/1skTXRIl ...
- iOS系列 基础篇 09 开关、滑块和分段控件
iOS系列 基础篇 09 开关.滑块和分段控件 目录: 案例说明 开关控件Switch 滑块控件Slider 分段控件Segmented Control 1. 案例说明 开关控件(Switch).滑块 ...
- Dojo: Quick Start
1.Dojo学习地址 2.Dojo快速开始 2.1.Dojo引入 2.2.指定Dojo模块的位置 2.3.模块加载require 3.查找Dom节点 3.1.根据id查找dom节点 3.2.根据c ...
- mongodb高级应用
一. 高级查询 查询操作符 条件操作符:db.collection.find({"field":{$gt/$lt/$gte/$lte/$eq/$ne:value}}); 匹配所有 ...