利用Python进行数据分析 第6章 数据加载、存储与文件格式(2)
6.2 二进制数据格式
实现数据的高效二进制格式存储最简单的办法之一,是使用Python内置的pickle序列化。
pandas对象都有一个用于将数据以pickle格式保存到磁盘上的to_pickle方法:

通过pickle直接读取被pickle化的数据,或使用更为方便的pandas.read_pickle:

Ps:pickle仅建议用于短期存储格式。因其很难保证该格式是永远稳定的。
pandas内置支持两个二进制数据格式:HDF5和MessagePack。pandas或Numpy数据的其他存储格式有:
- bcolz:一种可压缩的列存储二进制格式,基于Blosc压缩库
- Feather:跨语言的列存储文件格式。其使用了Apache Arrow的列式内存格式。
6.2.1 使用HDF5格式
HDF5是一种存储大规模科学数组数据的非常好的文件格式。它可被作为C标准库,带有许多语言的接口,如Java、Python和Matlab等。
HDF5中的HDF指的是层次型数据格式。每个HDF5文件都含有一个文件系统式的节点结构,使得能够存储多个数据集并支持元数据。
相较其他简单格式,HDF5支持多种压缩器的即时压缩,还能更高效地存储重复模式数据。对于非常大地无法直接放入内存的数据,HDF5可以高效地分块读写。
pandas提供地高级接口HDFStore类,可以像字典一样处理低级的细节,可以简化存储Series和DataFrame对象。(此外,也可用PyTables或h5py库直接访问HDF5文件,不如HDFStore高级简便):
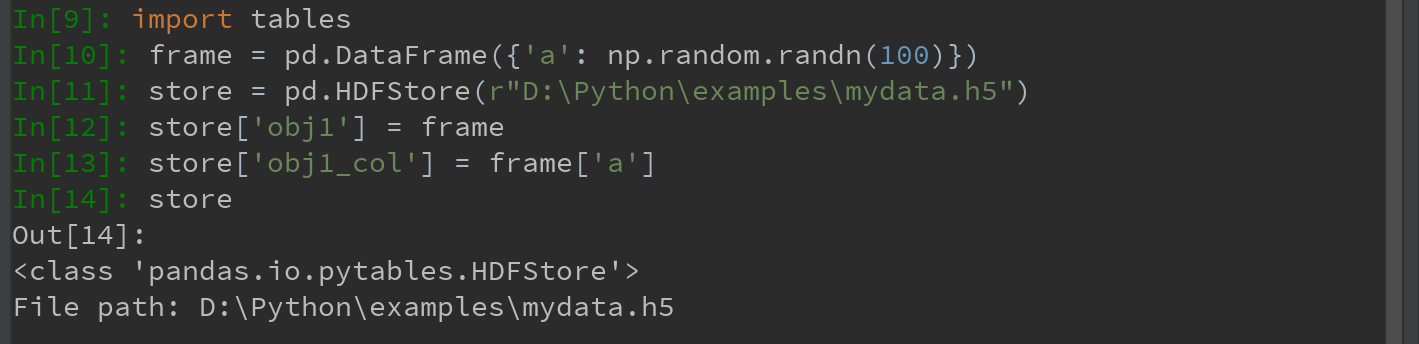
Ps:此处需要先安装tables库
HDF5文件中的对象可以通过与字典一样的API进行获取:

HDFStore支持两种存储模式,‘fixed’和‘table’。后者通常会更慢,但是支持使用特殊语法进行查询操作,如下:
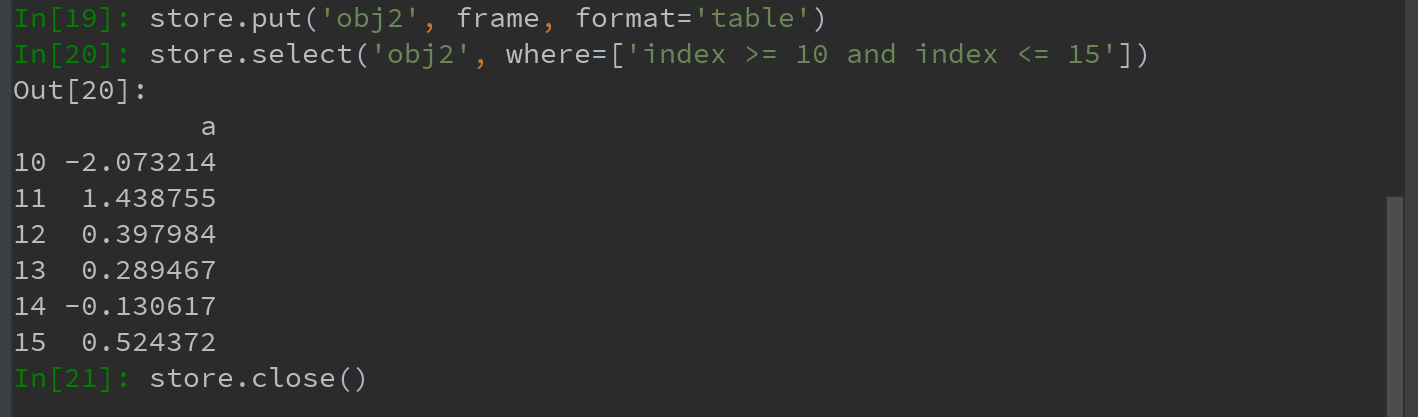
Ps:put是store['obj2'] = frame方法的显示版本,允许设置其他选项,如格式。
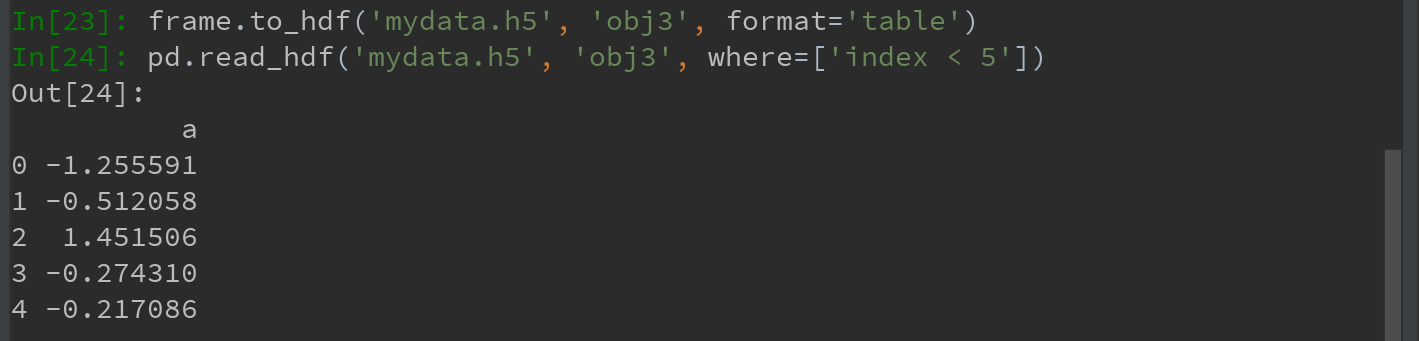
pandas.read_hdf函数可以快捷使用这些工具:
注意:如果需要处理的数据位于远程服务器,比如Amazon S3或HDFS,使用专门为分布式存储(比如Apache Parquet)的二进制格式也许更加合适。
如需要本地处理海量数据,需好好研究PyTables和h5py。由于许多数据分析问题都是IO密集型(非CPU密集型),利用HDF5这类工具能显著提升应用程序的效率。(HDF5不是数据库,是最适合用作“一次写多次读”的数据集)
6.2.2 读取Microsoft Excel文件
pandas的ExcelFile类或pandas.read_excel函数支持读取存储在Excel2003(或更高版本)中的表格型数据。
这两个工具分别使用扩展包xlrd和openpyxl读取XLS和XLSX文件。需安装这两个包。
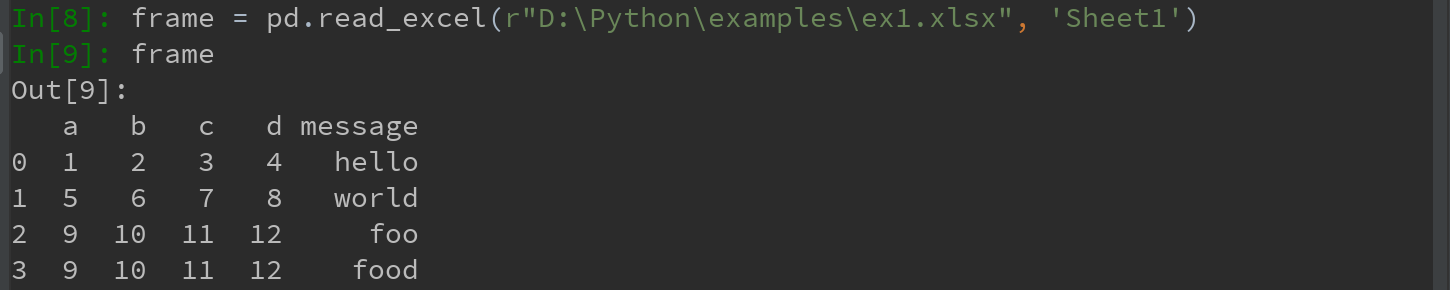
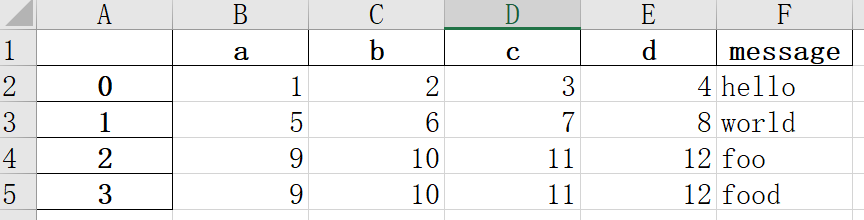
1)创建一个实例

2)用read_excel读取表单中的数据到DataFrame:

3)也可将文件名传递到pandas.read_excel:
问题:如何一次性同时读取一个文件中的多个表单?
如何同时读取同一个excl中的多个sheet?
4)如果要将pandas数据写入为Excel格式,你必须首先创建一个ExcelWriter,然后用pandas对象的to_excel方法将数据写入其中:

ps:将frame中的数据copy到ex2.xlsx中
Ps:也可不使用ExcelWriter,而是传递文件的路径到to_excel

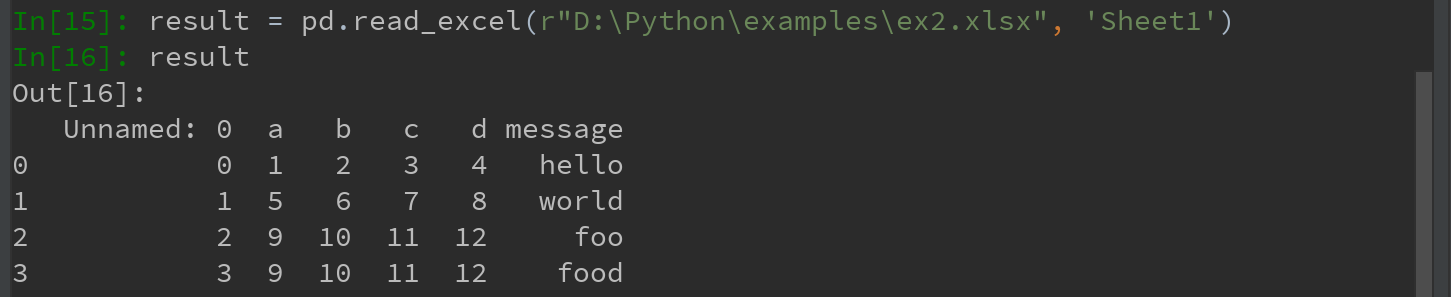
结果:
6.3 Web APIs交互
许多网站有一些通过JSON或其他格式提供数据的公共API。通过Python访问这些API的方法很多,较为简单的方法(比较推荐的方法)是requests包。
如,搜索最新的30个GitHub上的pandas主题,可以发一个HTTP GET请求,使用requests扩展库:

响应对象的json方法会返回一个包含被解析过的JSON字典,加载到一个Python对象中:
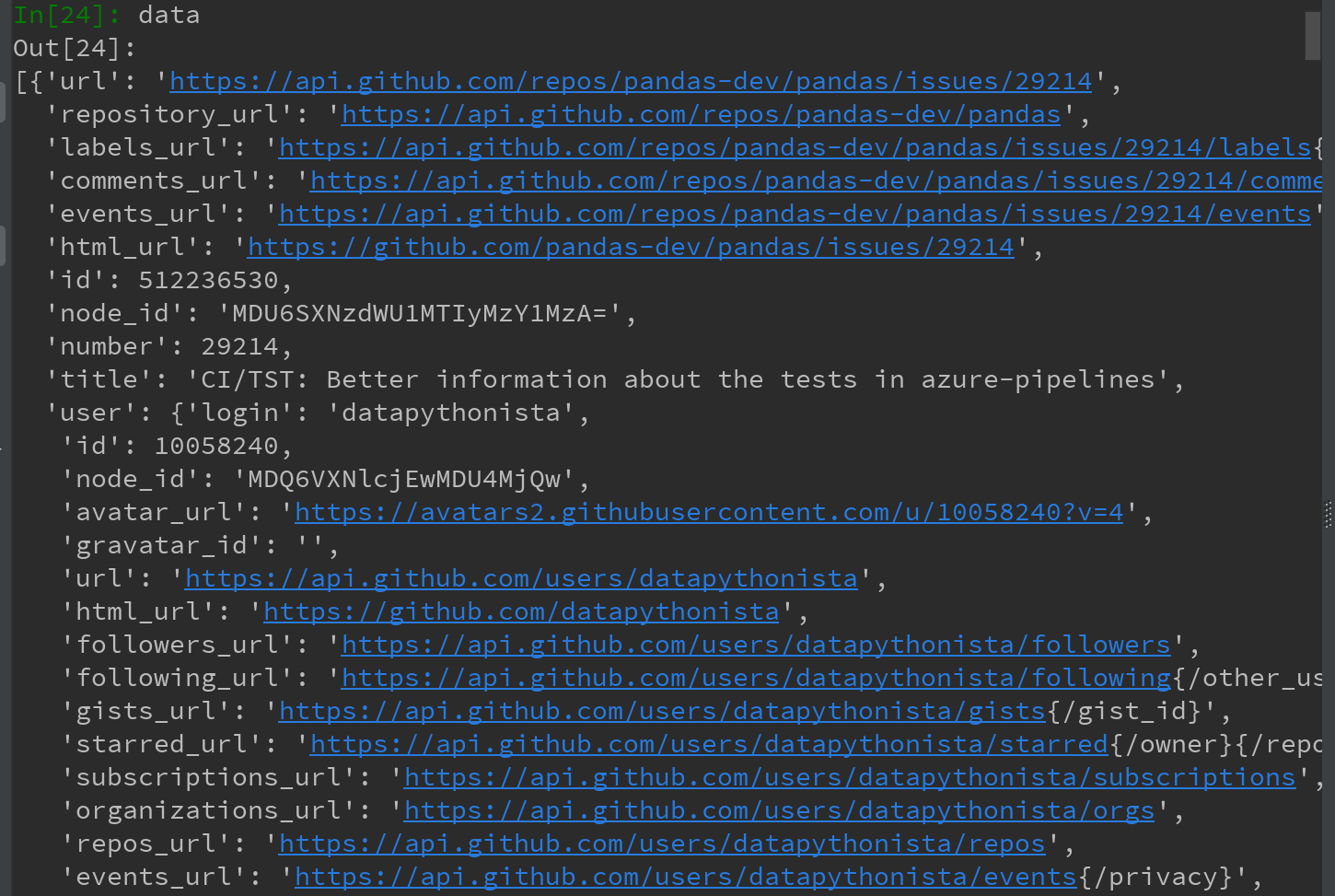

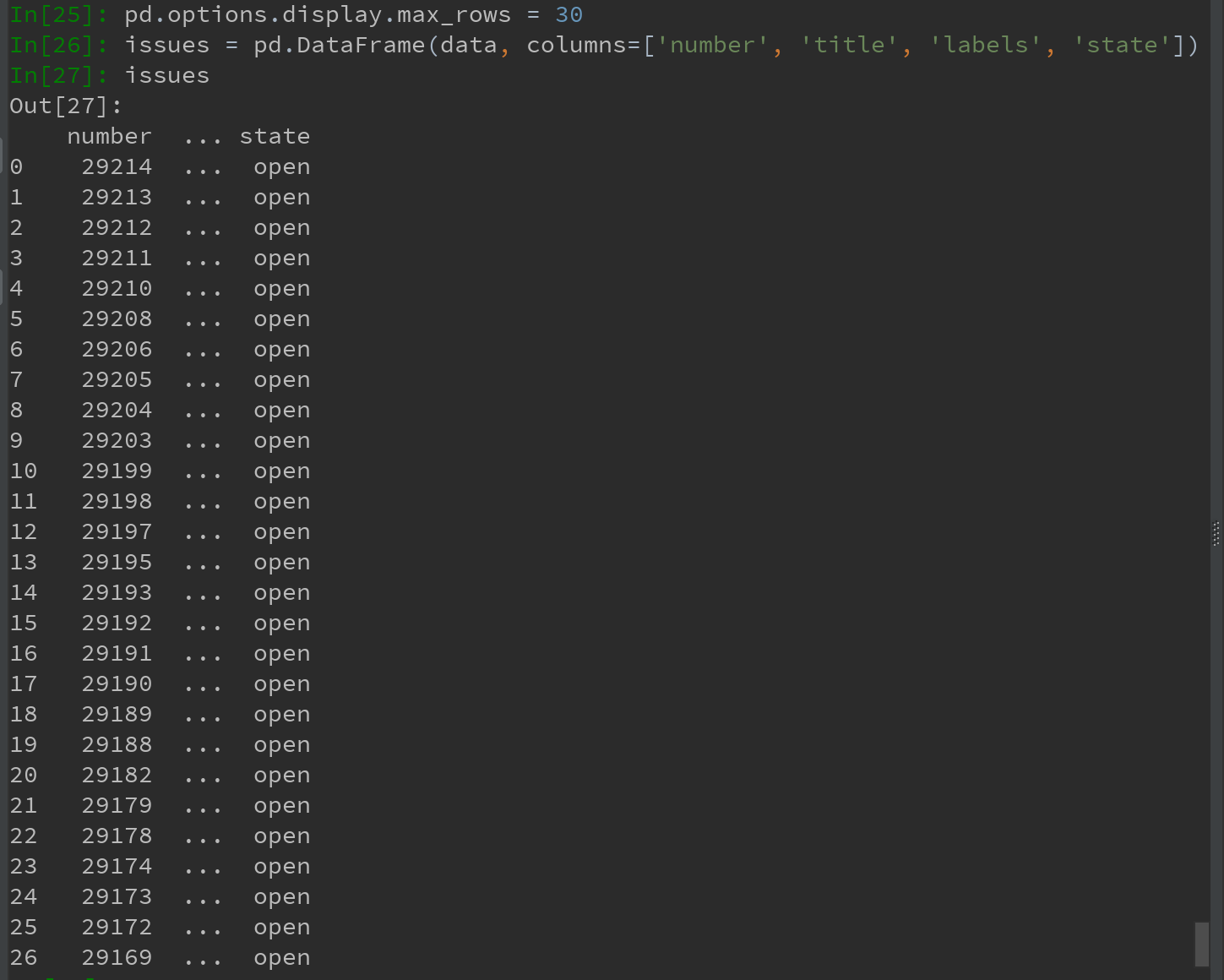
data中的每个元素都是一个包含所有GitHub主题页数据的字典。可以直接传递数据到DataFrame,并提取感兴趣的字段。
6.4 数据库交互
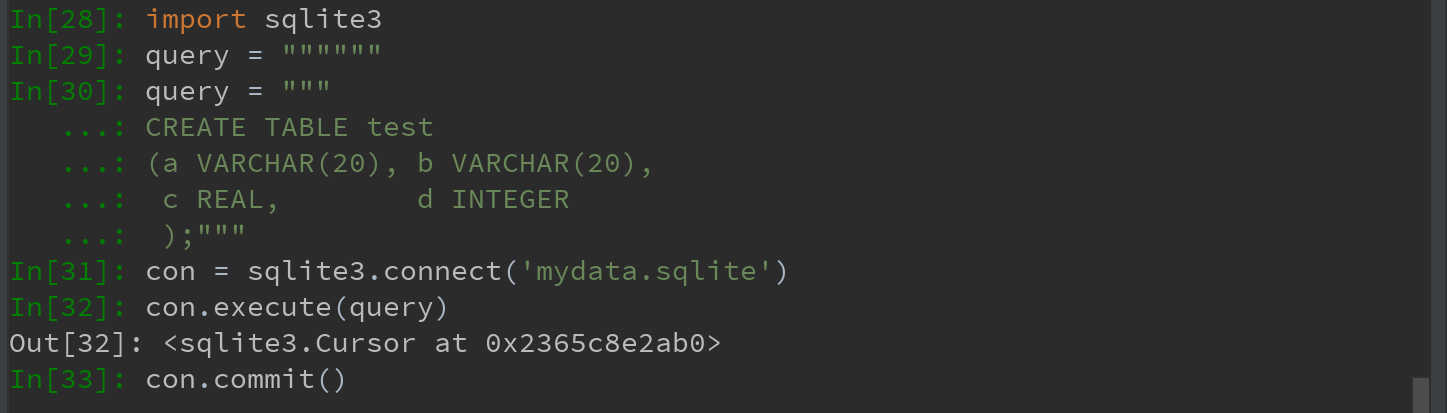
然后插入几行数据:
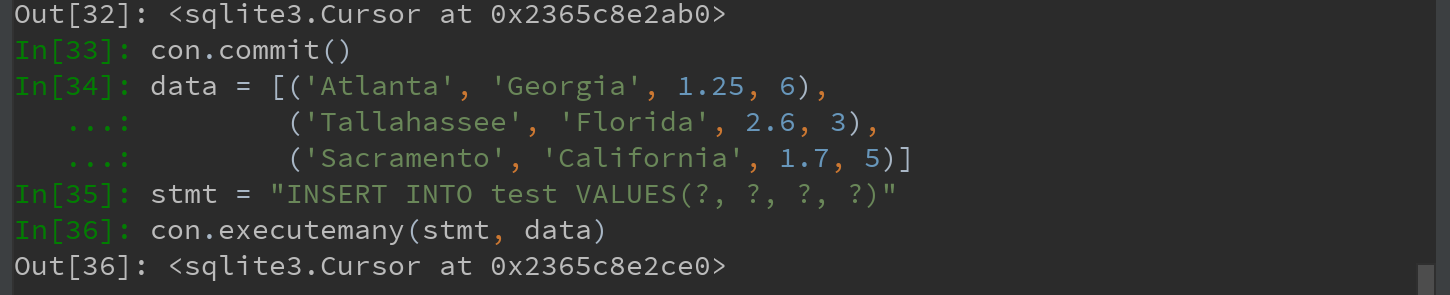
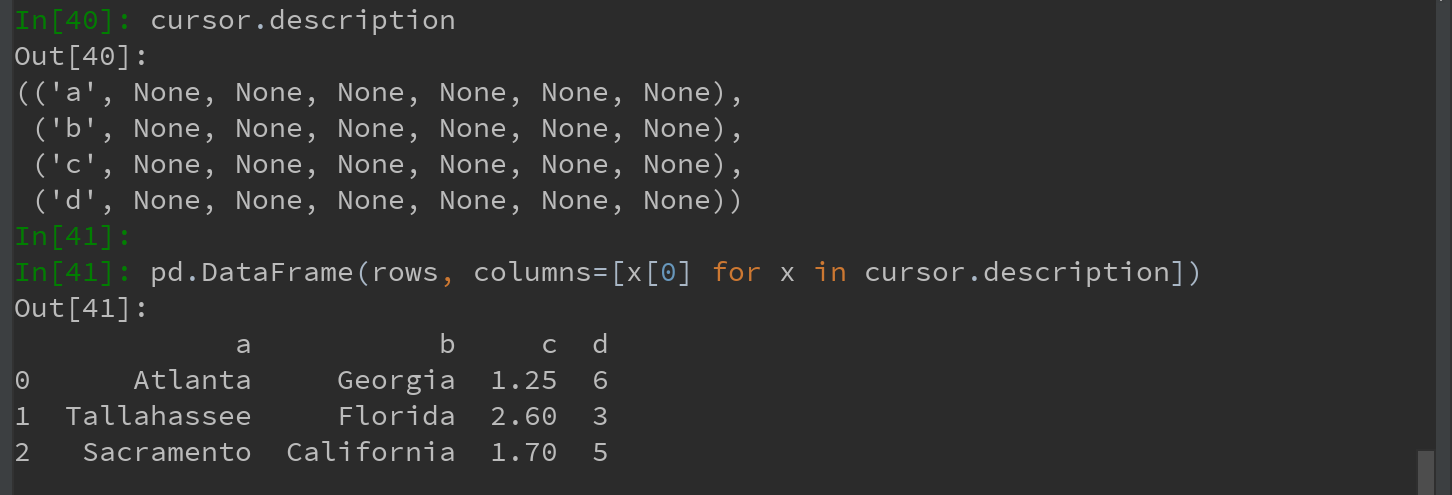
从表中选取数据时, 大部分Python SQL驱动器(PyODBC、psycopg2、MySQLdb、pymssql等)都会返回一个元组列表:

可将这个元组列表传给DataFrame构造器,但还需要列名(位于光标的description属性中):
如果不想每查一次数据库就重写一次,可使用另一个流行的Python SQL工具SQLAlchemy项目。pandas有一个read_sql函数,可以轻松的从SQLAlchemy连接读取数据。
如下,使用SQLAlchemy连接SQLite数据库,并从之前创建的表读取数据:

(这一块需要深入学习)
6.5 总结
访问数据通常是数据分析的第一步。本章已经介绍学习了一些有用的工具,接下来的章节中,将深入研究数据规整、数据可视化、时间序列分析和其他主题。
利用Python进行数据分析 第6章 数据加载、存储与文件格式(2)的更多相关文章
- 利用python进行数据分析之数据加载存储与文件格式
在开始学习之前,我们需要安装pandas模块.由于我安装的python的版本是2.7,故我们在https://pypi.python.org/pypi/pandas/0.16.2/#downloads ...
- 利用Python进行数据分析 第8章 数据规整:聚合、合并和重塑.md
学习时间:2019/11/03 周日晚上23点半开始,计划1110学完 学习目标:Page218-249,共32页:目标6天学完(按每页20min.每天1小时/每天3页,需10天) 实际反馈:实际XX ...
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- 利用Python进行数据分析_Pandas_处理缺失数据
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. 1 读取excel数据 import pandas as pd import ...
- 利用Python进行数据分析 第4章 IPython的安装与使用简述
本篇开始,结合前面所学的Python基础,开始进行实战学习.学习书目为<利用Python进行数据分析>韦斯-麦金尼 著. 之前跳过本书的前述基础部分(因为跟之前所学的<Python基 ...
- 《利用python进行数据分析》读书笔记--第六章 数据加载、存储与文件格式
http://www.cnblogs.com/batteryhp/p/5021858.html 输入输出一般分为下面几类:读取文本文件和其他更高效的磁盘存储格式,加载数据库中的数据.利用Web API ...
- 利用Python进行数据分析 第7章 数据清洗和准备(2)
7.3 字符串操作 pandas加强了Python的字符串和文本处理功能,使得能够对整组数据应用字符串表达式和正则表达式,且能够处理烦人的缺失数据. 7.3.1 字符串对象方法 对于许多字符串处理和脚 ...
- 利用Python进行数据分析 第4章 NumPy基础-数组与向量化计算(3)
4.2 通用函数:快速的元素级数组函数 通用函数(即ufunc)是一种对ndarray中的数据执行元素级运算的函数. 1)一元(unary)ufunc,如,sqrt和exp函数 2)二元(unary) ...
- 利用Python进行数据分析 第7章 数据清洗和准备(1)
学习时间:2019/10/25 周五晚上22点半开始. 学习目标:Page188-Page217,共30页,目标6天学完,每天5页,预期1029学完. 实际反馈:集中学习1.5小时,学习6页:集中学习 ...
随机推荐
- web前端兼容性问题
传送门:https://www.cnblogs.com/zhoudawei/p/7497544.html
- js插件---弹出层sweetalert2(总结)
js插件---弹出层sweetalert2(总结) 一.总结 一句话总结: sweetalert2的效果非常好,效果比较Q萌,移动端适配也比较好,感觉比layer.js效果好点 1.SweetAler ...
- SQL中join和cross join的区别
SQL中的连接可以分为内连接,外连接,以及交叉连接 . 1. 交叉连接CROSS JOIN 如果不带WHERE条件子句,它将会返回被连接的两个表的笛卡尔积,返回结果的行数等于两个表行数的乘积: 举例, ...
- linux中截取字段与#、$区别
1.Linux shell 截取字符变量的前8位 实现方法有如下几种: expr substr “$a” 1 8 echo $a|awk ‘{print substr(,1,8)}’ echo $a| ...
- python 设计模式之单例模式 Singleton Pattern
#引入 一个类被设计出来,就意味着它具有某种行为(方法),属性(成员变量).一般情况下,当我们想使用这个类时,会使用new 关键字,这时候jvm会帮我们构造一个该类的实例.这么做会比较耗费资源. 如果 ...
- leetcode 11. Container With Most Water 、42. Trapping Rain Water 、238. Product of Array Except Self 、407. Trapping Rain Water II
11. Container With Most Water https://www.cnblogs.com/grandyang/p/4455109.html 用双指针向中间滑动,较小的高度就作为当前情 ...
- git git push某一次的commit记录
$ git push <remote name> <commit hash>:<remote branch name> # Example:$ git push o ...
- python初级 1 内存和变量
一.回顾: 1.什么是程序 一堆指令的集合 2.回想一下猜数游戏程序的特征: 1)需要输入(input) 2)会处理输入(process) 3)产生输出(output) 二.程序的一般特征:输入.处理 ...
- 123457123456#0#-----com.tym.niuniuChengYu05--前拼后广--最牛成语tym
com.tym.niuniuChengYu05--前拼后广--最牛成语tym
- WebException 请求被中止: 操作超时
HTTP 请求时出现 :WebException 请求被中止: 操作超时 处理HTTP请求的服务器 CPU 100% ,重启后正常.