使用scrapy进行12306车票查询
概述
详细
一、环境搭建
1. 安装配置python3.6
示例网站使用的是python 3.6.1
下载地址:https://www.python.org/downloads/release/python-361/
根据自己的系统选择相应的版本
2. 安装Twisted
Windows:
进入http://www.lfd.uci.edu/~gohlk...下载对应twisted

转到下载目录, 命令行执行:pip install Twisted-17.9.0-cp36-cp36m-win_amd64.whl
3. 安装Scrapy
mac或linux:
pip install Scrapy
windows:
pip install pywin32
pip install Scrapy
二、项目结构以及程序实现
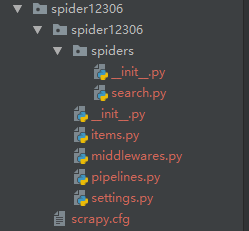
上图是使用scrapy startproject spider12306 命令生成的基本模板, 之后使用scrapy genspider search 12307.cn 生成了一个基本爬虫,在此基础上进行自己需要的爬虫改写.
思路:
找到网页接口——进行查询后通过chrome找到查询地址是这样的:
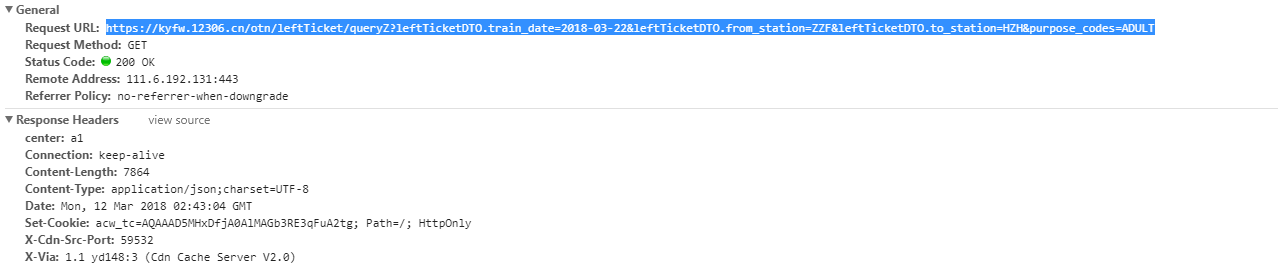
通过这个地址可以看出,查询是通过向https://kyfw.12306.cn/otn/leftTicket发送GET请求来执行查询的。参数一共有4个:
leftTicketDTO.train_date: 日期
leftTicketDTO.from_station: 出发站
leftTicketDTO.to_station: 到达站
purpos_codes:车票类型 ADULT 成人票
现在有一个问题,出发站和到达站用的是缩写,查询返回的结果用的也是缩写,所以我们需要知道英文缩写对应的车站,之后我就找到了这个东西:
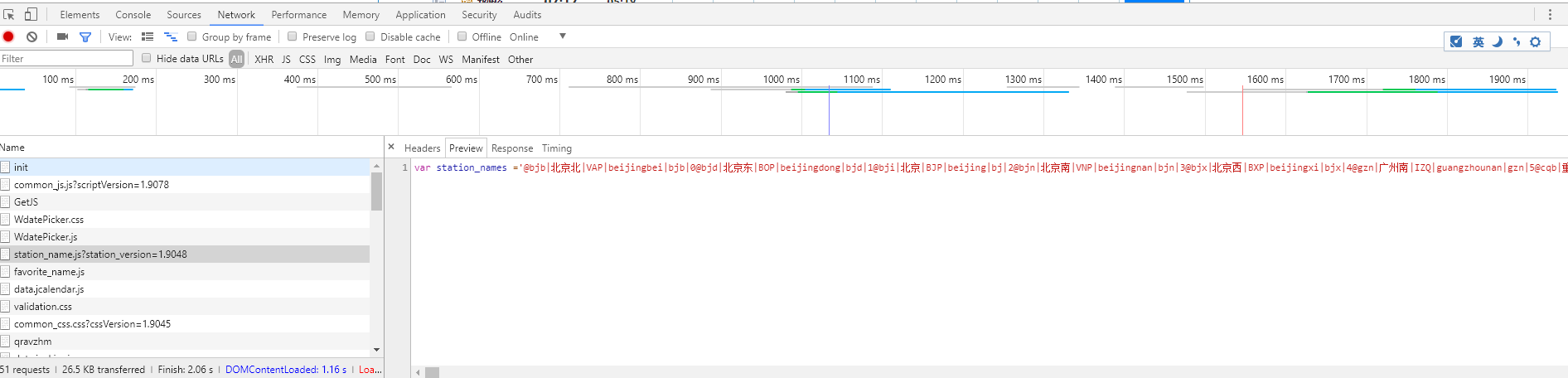
有一个名为:station_name 的js文件,其中就记录所有的中文站名以及其缩写。
通过正则等方法将其保存为两个json文件(本人用的是笨办法),键值对分别是:
站点名: 缩写 以及 缩写: 站点名 方便我们将来查询
之后就可以编写爬虫了
1. 根据顺序来我们先设置起始站点为查询站点缩写的js文件
class SearchSpider(scrapy.Spider):
name = 'search'
allowed_domains = ['12306.cn']
# 出发时间 日期如果小于今天 会报错的
train_data = '2018-03-22'
# 出发站
from_station = '郑州'
# 到
to_station = '杭州'
start_urls = ['https://kyfw.12306.cn/otn/resources/js'
'/framework/station_name.js?station_version=1.9048']
2. 解析并保存结果为json文件
if not os.path.exists('stations.json'):
text = response.body.decode('utf-8')
content = re.match('.+?(@.+)', text)
if content:
# 获取所有车站信息
text = content.group(1)
# 进行清洗后写入json文件
l = text.split('|')
a, b = 1, 2
stations = {}
search = {}
while b < len(l):
stations[l[a]] = l[b]
search[l[b]] = l[a]
a += 5
b += 5
stations = json.dumps(stations, ensure_ascii=False)
with open('stations.json', 'w', encoding='utf-8') as f:
f.write(stations)
search = json.dumps(search, ensure_ascii=False)
with open('search.json', 'w', encoding='utf-8') as f:
f.write(search)
else:
(response.body.decode())
3. 根据需要查询的内容向查询地址发出get请求并接受查询结果
with open('stations.json', 'rb') as f:
station = json.load(f)
query_url = 'https://kyfw.12306.cn/otn/leftTicket/queryZ?' \
'leftTicketDTO.train_date={}&' \
'leftTicketDTO.from_station={}&' \
'leftTicketDTO.to_station={}&' \
'purpose_codes=ADULT'.format(
self.train_data, station[self.from_station],
station[self.to_station])
yield scrapy.Request(query_url, callback=self.query_parse)
4. 解析查询结果并保存为csv文件(可使用excel打开)
通过观察发现,返回的结果都是用'|'隔开的,貌似只能用下标来定位, 所以采用了下面的方法,如果有更好的方法请联系我,谢谢!
def query_parse(self, response):
"""解析查询结果"""
text = response.body.decode('utf-8')
message_fields = ['车次', '始发站', '终点站', '出发站', '到达站', '出发时间', '到达时间',
'历时', '特等座', '一等座', '二等座', '软卧', '硬卧', '硬座', '无座']
writer = csv.writer(open('ans.csv', 'w'))
writer.writerow(message_fields)
infos = json.loads(text)['data']['result']
with open('search.json', 'rb') as f:
search = json.load(f)
for info in infos:
info = info.split('|')[3:]
if info[8] == 'N':
continue
row = [info[0], search[info[1]], search[info[2]], search[info[3]],
search[info[4]], info[5], info[6], info[7], info[29],
info[28], info[27], info[20], info[25], info[26], info[23]]
writer.writerow(row)
pass
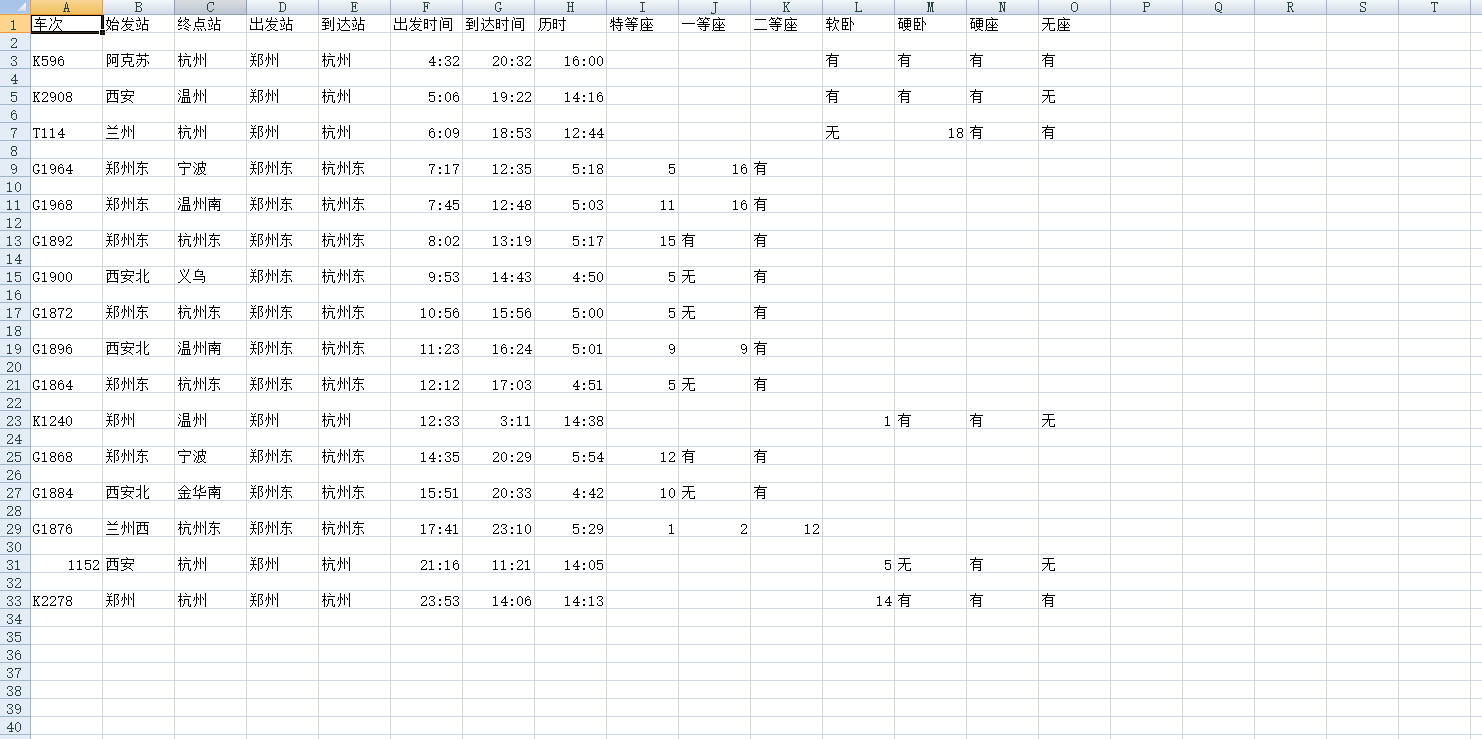
详细代码在例子包中, 仅供参考.....
运行
进入spider12306文件夹,在装有scrapy的虚拟环境或真实环境中运行
scrapy crawl search
即可, 然后可在运行目录找到 ans.csv 文件 打开后类似上图
注:本文著作权归作者,由demo大师发表,拒绝转载,转载需要作者授权
使用scrapy进行12306车票查询的更多相关文章
- PyQt5+requests实现车票查询工具
PyQt5+requests实现一个车票查询工具,供大家参考,具体内容如下 结构图 效果图 思路 1.search(QPushButton)点击信号(clicked)连接到自定义的槽函数(ev ...
- 12306火车票查询--python
最近我看到看到使用python实现火车票查询,我自己也实现了,感觉收获蛮多的,下面我就把每一步骤都详细给分享出来.(注意使用的是python3) 首先我将最终结果给展示出来: 在cmd命令行执行:py ...
- 聚合数据Android SDK 12306火车票查询订票演示示例
1.聚合SDK是聚合数据平台,为移动开发者提供的免费数据接口.使用前请先到聚合平台(http://www.juhe.cn/)注册,申请相关数据. 2.下载聚合数据SDK,将开发包里的juhe_sdk_ ...
- 微信小程序火车票查询 直取12306数据
最终效果图: 样式丑哭了,我毕竟不是前端,宗旨就是练练手,体验微信小程序的开发,以最直接的方式获取12306数据查询火车票. 目录结构: search1是出发站列表,search2是目的站列表,命名没 ...
- 技术揭秘12306改造(一):尖峰日PV值297亿下可每秒出票1032张
[编者按]12306网站曾被认为是"全球最忙碌的网站",在应对高并发访问处理方面,曾备受网民诟病. 2015年铁路客票春运购票高峰期已过,并且12306网站今年没"瘫痪& ...
- python3.7之12306抢票脚本实现
悲催的12306,彻底沦为各路抢票软件的服务提供方.元旦伊始,纯粹12306官网及APP抢票,愈一周的时间,仅到手一张凌晨3:55回家的站票.为远离脑残,无奈选择抢票软件,预购年后返沪车票.BTW,研 ...
- 小工具:天气查询 Vs自定义设置 DevGridControl中GridView排序问题 小工具:火车票查询 小工具:邮件发送 小工具:截图&简单图像处理
小工具:天气查询 开发一个天气查询的工具主要由两步构成,一是数据的获取,二是数据的展示. 一.数据获取 数据获取又可以分为使用其它公司提供的API和手动抓取其它网站数据. 1. 某公司提供的AP ...
- python写12306抢票
#!/usr/bin/env python # -*- coding: utf-8 -*- ''' 利用splinter写的一个手动过验证及自动抢票的例子, 大家可以自己扩展或者弄错窗体.web端. ...
- scrapy 爬虫基础
Scrapy是Python开发的一个快速.高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘.监测和自动化测试. 安装Scrapy的 ...
随机推荐
- 高效的 itertools 模块(转)
原文地址:http://python.jobbole.com/87380/ 我们知道,迭代器的特点是:惰性求值(Lazy evaluation),即只有当迭代至某个值时,它才会被计算,这个特点使得迭代 ...
- CSS 笔记——文本字体
5. 文本字体 -> 文本 (1)text-indent 基本语法 text-indent : length 语法取值 length : 百分比数字 | 由浮点数字和单位标识符组成的长度值,允许 ...
- 2017 Multi-University Training 1 解题报告
Add More Zero Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 131072/131072 K (Java/Others)T ...
- HDU 6041 I Curse Myself(二分+搜索)
[题目链接] http://acm.hdu.edu.cn/showproblem.php?pid=6041 [题目大意] 给出一个仙人掌图,求第k小生成树 [题解] 首先找到仙人掌图上的环,现在的问题 ...
- 【线段树/区间开平方】BZOJ3211-花神游历各国
[题目大意] 给出一些数,有两种操作.(1)将区间内每一个数开方(2)查询每一段区间的和 [思路] 普通的线段树保留修改+开方优化.可以知道当一个数为0或1时,无论开方几次,答案仍然相同.所以设置fl ...
- Problem D: 指针:调用自定义排序函数sort,对输入的n个数进行从小到大输出。
#include<stdio.h> int sort(int *p,int n) { int i,j,temp; ;i<n-;i++) for(j=i;j<n;j++) if( ...
- 141.最小m 段和问题--划分性DP(特殊数据)
3278 最小m 段和问题 时间限制: 1 s 空间限制: 256000 KB 题目等级 : 黄金 Gold 题解 查看运行结果 题目描述 Description 给定 n 个整数(不一定是正整 ...
- Ubuntu 16.04搭建原始Git服务器
说明:不要把有限的生命浪费到权限斗争中! 1.安装SSH sudo apt-get install openssh-server sudo service ssh start 2.安装Git sudo ...
- ARM的存储器映射与存储器重映射
转:http://www.360doc.com/content/12/1006/00/1299815_239693009.shtml arm 处理器本身所产生的地址为虚拟地址,每一个arm芯片内都有存 ...
- Unity3D 手游开发中所有特殊的文件夹
这里列举出手游开发中用到了所有特殊文件夹. 1.Editor Editor文件夹可以在根目录下,也可以在子目录里,只要名子叫Editor就可以.比如目录:/xxx/xxx/Editor 和 /Edi ...