Windows + IDEA 手动开发MapReduce程序
- 参见马士兵老师的博文:map_reduce
环境配置
Windows本地解压Hadoop压缩包,然后像配置JDK环境变量一样在系统环境变量里配置HADOOP_HOME和path环境变量。注意:hadoop安装目录尽量不要包含空格或者中文字符。
形如:
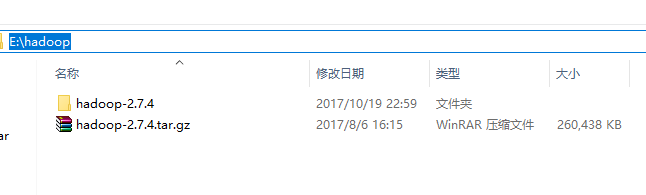
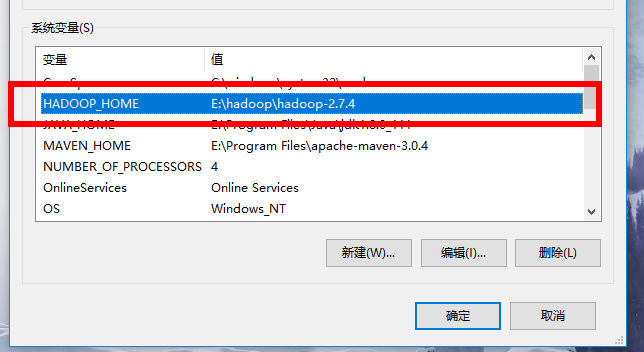
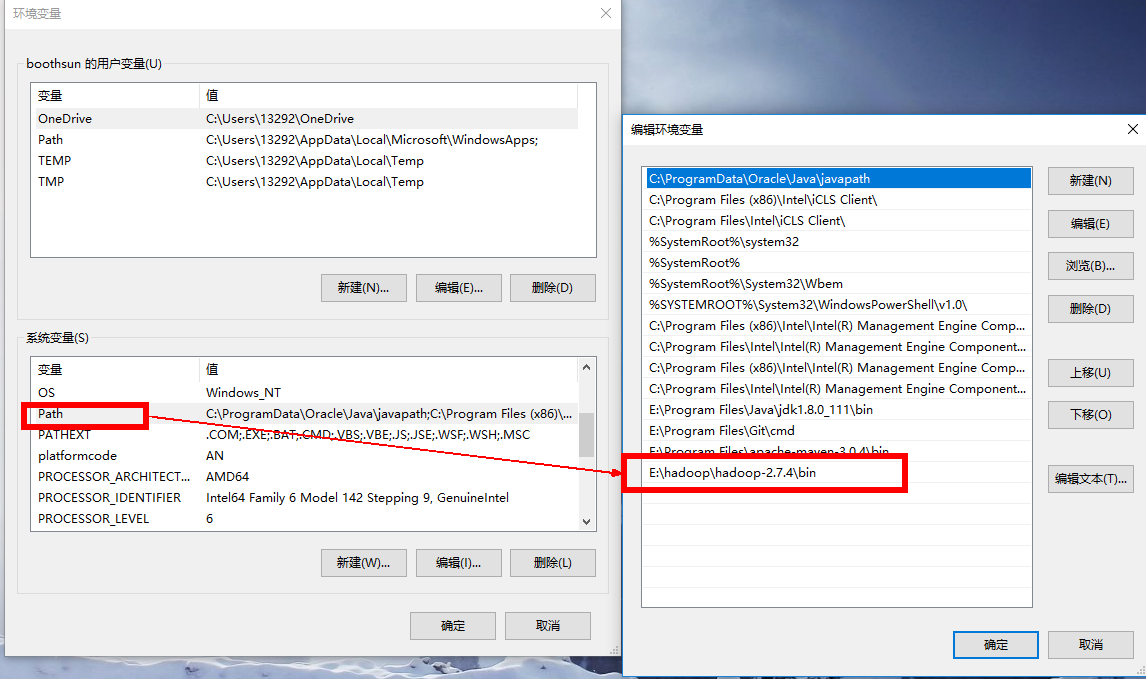
添加windows环境下依赖的库文件
- 把盘中(盘地址 提取码:s6uv)共享的bin目录覆盖HADOOP_HOME/bin目录下的文件。
- 如果还是不行,把其中hadoop.dll复制到C:\windows\system32目录下,可能需要重启机器。
- 注意:配置好之后不需要启动Windows上的Hadoop
pom.xml
<!-- hadoop start -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-minicluster</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-assemblies</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-maven-plugins</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.4</version>
</dependency>
<!-- hadoop end -->
代码
WordMapper:
public class WordMapper extends Mapper<Object,Text,Text,IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
public void map(Object key , Text value , Context context) throws IOException, InterruptedException{
StringTokenizer itr = new StringTokenizer(value.toString()) ;
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word,one);
}
}
}
WordReducer::
public class WordReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable() ;
public void reduce(Text key , Iterable<IntWritable> values, Context context) throws IOException , InterruptedException {
int sum = 0 ;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key,result);
}
}
本地计算 + 本地HDFS文件
public static void main(String[] args) throws Exception{
//如果配置好环境变量,没有重启机器,然后报错找不到hadoop.home 可以手动指定
// System.setProperty("hadoop.home.dir","E:\\hadoop\\hadoop-2.7.4");
List<String> lists = Arrays.asList("E:\\input","E:\\output");
Configuration configuration = new Configuration();
Job job = new Job(configuration,"word count") ;
job.setJarByClass(WordMain.class); // 主类
job.setMapperClass(WordMapper.class); // Mapper
job.setCombinerClass(WordReducer.class); //作业合成类
job.setReducerClass(WordReducer.class); // reducer
job.setOutputKeyClass(Text.class); // 设置作业输出数据的关键类
job.setOutputValueClass(IntWritable.class); // 设置作业输出值类
FileInputFormat.addInputPath(job,new Path(lists.get(0))); //文件输入
FileOutputFormat.setOutputPath(job,new Path(lists.get(1))); // 文件输出
System.exit(job.waitForCompletion(true) ? 0 : 1); //等待完成退出
}
本地计算 + 远程HDFS文件
把远程HDFS文件系统中的文件拉到本地来运行。
相比上面的改动点:
FileInputFormat.setInputPaths(job, "hdfs://master:9000/wcinput/");
FileOutputFormat.setOutputPath(job, new Path("hdfs://master:9000/wcoutput2/"));
注意这里是把HDFS文件拉到本地来运行,如果观察输出的话会观察到jobID带有local字样,同时这样的运行方式是不需要yarn的(自己停掉jarn服务做实验)。
远程计算 + 远程HDFS文件
这个方式是将文件打成一个jar文件,通过Hadoop Client自动上传到Hadoop集群,然后使用远程HDFS文件进行计算。
java代码:
public static void main(String[] args) throws Exception{
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "hdfs://master:9000/");
configuration.set("mapreduce.job.jar", "target/wc.jar");
configuration.set("mapreduce.framework.name", "yarn");
configuration.set("yarn.resourcemanager.hostname", "master");
configuration.set("mapreduce.app-submission.cross-platform", "true");
Job job = new Job(configuration,"word count") ;
job.setJarByClass(WordMain2.class); // 主类
job.setMapperClass(WordMapper.class); // Mapper
job.setCombinerClass(WordReducer.class); //作业合成类
job.setReducerClass(WordReducer.class); // reducer
job.setCombinerClass(WordReducer.class); //作业合成类
job.setOutputKeyClass(Text.class); // 设置作业输出数据的关键类
job.setOutputValueClass(IntWritable.class); // 设置作业输出值类
FileInputFormat.setInputPaths(job, "/opt/learning/hadoop/wordcount/*.txt");
FileOutputFormat.setOutputPath(job, new Path("/opt/learning/output7/"));
System.exit(job.waitForCompletion(true) ? 0 : 1); //等待完成退出
}
如果运行过程中遇到权限问题,配置执行时的虚拟机参数 -DHADOOP_USER_NAME=root 。
形如下图:

Windows + IDEA 手动开发MapReduce程序的更多相关文章
- windows环境下Eclipse开发MapReduce程序遇到的四个问题及解决办法
按此文章<Hadoop集群(第7期)_Eclipse开发环境设置>进行MapReduce开发环境搭建的过程中遇到一些问题,饶了一些弯路,解决办法记录在此: 文档目的: 记录windows环 ...
- [MapReduce_add_1] Windows 下开发 MapReduce 程序部署到集群
0. 说明 Windows 下开发 MapReduce 程序部署到集群 1. 前提 在本地开发的时候保证 resource 中包含以下配置文件,从集群的配置文件中拷贝 在 resource 中新建 ...
- 本地idea开发mapreduce程序提交到远程hadoop集群执行
https://www.codetd.com/article/664330 https://blog.csdn.net/dream_an/article/details/84342770 通过idea ...
- [b0010] windows 下 eclipse 开发 hdfs程序样例 (二)
目的: 学习windows 开发hadoop程序的配置 相关: [b0007] windows 下 eclipse 开发 hdfs程序样例 环境: 基于以下环境配置好后. [b0008] Window ...
- 在Eclipse中开发MapReduce程序
一.Eclipse的安装与设置 1.在Eclipse官网上下载eclipse-jee-oxygen-3a-linux-gtk-x86_64.tar.gz文件并将其拷贝到/home/jun/Resour ...
- [b0007] windows 下 eclipse 开发 hdfs程序样例
目的: 学习使用hdfs 的java命令操作 相关: 进化: [b0010] windows 下 eclipse 开发 hdfs程序样例 (二) [b0011] windows 下 eclipse 开 ...
- [b0011] windows 下 eclipse 开发 hdfs程序样例 (三)
目的: 学习windows 开发hadoop程序的配置. [b0007] windows 下 eclipse 开发 hdfs程序样例 太麻烦 [b0010] windows 下 eclipse 开发 ...
- Windows平台开发Mapreduce程序远程调用运行在Hadoop集群—Yarn调度引擎异常
共享原因:虽然用一篇博文写问题感觉有点奢侈,但是搜索百度,相关文章太少了,苦苦探寻日志才找到解决方案. 遇到问题:在windows平台上开发的mapreduce程序,运行迟迟没有结果. Mapredu ...
- hadoop开发MapReduce程序
准备工作: 1.设置HADOOP_HOME,指向hadoop安装目录 2.在window下,需要把hadoop/bin那个目录替换下,在网上搜一个对应版本的 3.如果还报org.apache.hado ...
随机推荐
- eclipse里配置Android ndk环境,用eclipse编译.so文件
做Android NDK开发时,c代码需要用ndk-build来进行编译,而java代码则需要用Android sdk编译. 编译c代码有两种方法: 一.写好c代码后,然后用cygwin搭建ndk-b ...
- poco普通线程
#include "Poco/Thread.h" #include "Poco/RunnableAdapter.h" #include <iostream ...
- Django CRM系统
本节内容 业务痛点分析 项目需求讨论 使用场景分析 表结构设计 业务痛点分析 我2013年刚加入老男孩教育的时候,学校就一间教室,2个招生老师,招了学生后,招生老师就在自己的excel表里记录一下,每 ...
- OpenCV学习笔记(01)我的第一个OpenCV程序(环境配置)
昨天刚刚考完编译原理,私心想着可以做一些与考试无关的东西了.一直想做和图像处理相关的东西,趁这段时间有空学习一下OpenCV,搭建环境真是一件麻烦的事情,搞了近三个小时终于OK了.先来张图: 大致描述 ...
- ubuntu18.04server设置静态IP
16.04以后的版本配置静态IP是类似这样的文件 /etc/netplan/50-cloud-init.yaml 1.查询网卡名称 2.修改配置文件/etc/netplan/50-cloud-init ...
- jsoup select 选择器
转载自:http://blog.csdn.net/zhejingyuan/article/details/11801027 方法 利用方法:Element.select(String selector ...
- java加载驱动
加载驱动方法 1.Class.forName("com.microsoft.sqlserver.jdbc.SQLServerDriver"); 2. DriverManager.r ...
- SpringBoot打war包并部署到tomcat下运行
一.修改pom.xml. 1.packaging改为war 2.build节点添加<finalName>你的项目名</finalName> 二.修改项目启动类,继承Spring ...
- redis cluster以及master-slave在windows下环境搭建
一.redis cluster环境搭建: 1.了解Redis Cluster原理: 详细了解可参考:http://doc.redisfans.com/topic/cluster-tutorial.ht ...
- 注意for循环中变量的作用域
for e in collections: pass 在for 循环里, 最后一个对象e一直存在在上下文中.就是在循环外面,接下来对e的引用仍然有效. 这里有个问题容易被忽略,如果在循环之前已经有一个 ...