HDFS原理
1 . NameNode 概述
a、 NameNode 是 HDFS 的核心。
b、 NameNode 也称为 Master。
c、 NameNode 仅存储 HDFS 的元数据:文件系统中所有文件的目录树,并跟踪整个集群中的文件。
d、 NameNode 不存储实际数据或数据集。数据本身实际存储在 DataNodes 中。
e、 NameNode 知道 HDFS 中任何给定文件的块列表及其位置。使用此信息NameNode 知道如何从块中构建文件。
f、 NameNode 并不持久化存储每个文件中各个块所在的 DataNode 的位置信息,这些信息会在系统启动时从数据节点重建。
g、 NameNode 对于 HDFS 至关重要,当 NameNode 关闭时,HDFS / Hadoop 集群无法访问。
h、 NameNode 是 Hadoop 集群中的单点故障。
i、 NameNode 所在机器通常会配置有大量内存(RAM)。

2 . DataNode 概述
a、 DataNode 负责将实际数据存储在 HDFS 中。
b、 DataNode 也称为 Slave。
c、 NameNode 和 DataNode 会保持不断通信。
d、 DataNode 启动时,它将自己发布到 NameNode 并汇报自己负责持有的块列表。
e、 当某个 DataNode 关闭时,它不会影响数据或群集的可用性。NameNode 将安排由其他 DataNode 管理的块进行副本复制。
f、 DataNode 所在机器通常配置有大量的硬盘空间。因为实际数据存储在DataNode 中。
g、 DataNode 会定期(dfs.heartbeat.interval 配置项配置,默认是 3 秒)向NameNode 发送心跳,如果 NameNode 长时间没有接受到 DataNode 发送的心跳, NameNode 就会认为该 DataNode 失效。
h、 block 汇报时间间隔取参数 dfs.blockreport.intervalMsec,参数未配置的话默认为 6 小时.
3 . HDFS的工作机制
NameNode 负责管理整个文件系统元数据;DataNode 负责管理具体文件数据块存储;Secondary NameNode 协助 NameNode 进行元数据的备份。
HDFS 的内部工作机制对客户端保持透明,客户端请求访问 HDFS 都是通过向NameNode 申请来进行。
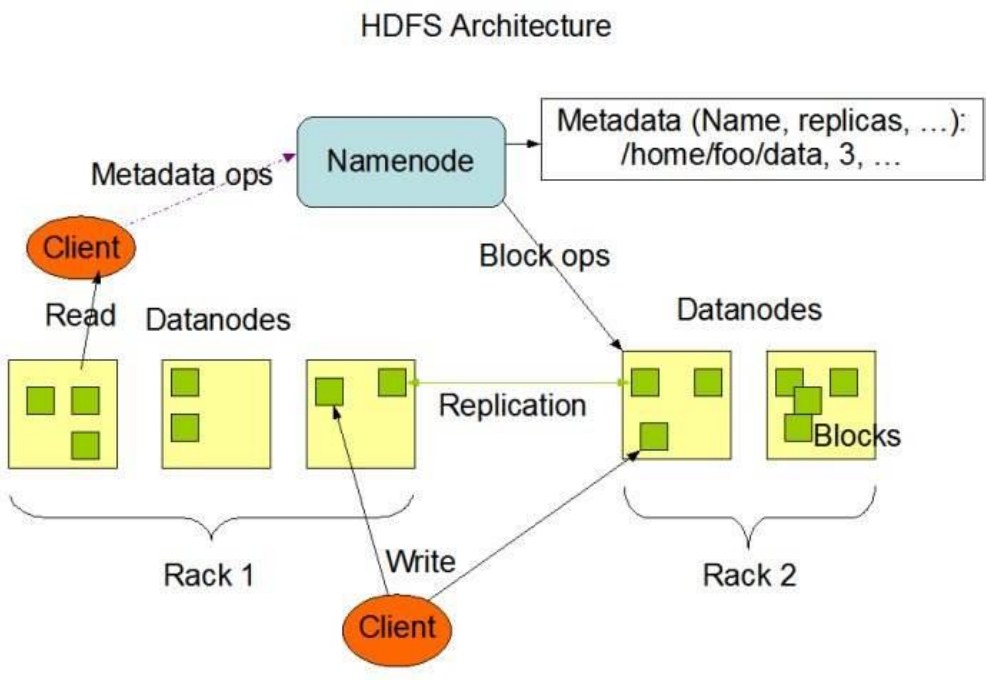
3.1 . HDFS 写数据流程
详细步骤解析:
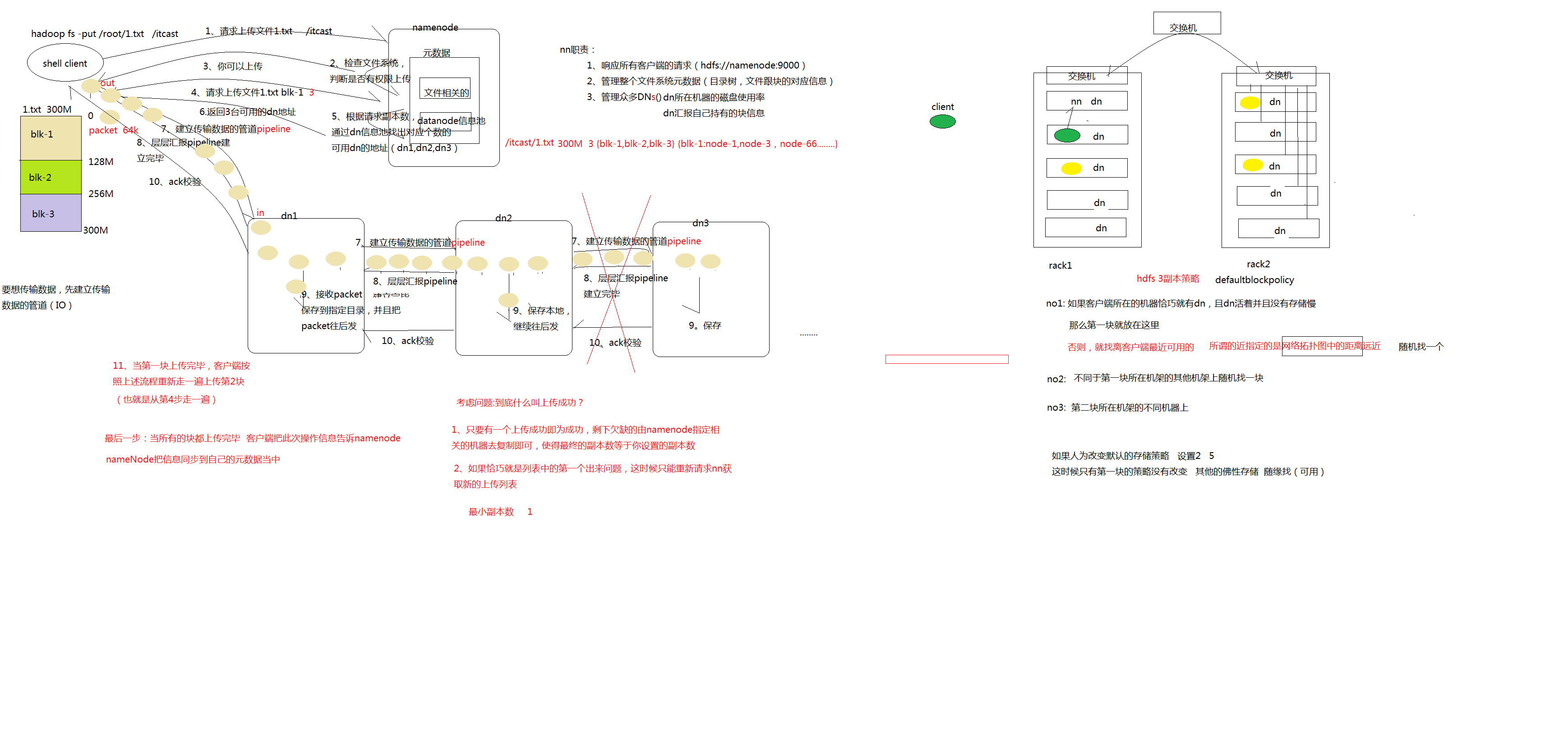
1、 client 发起文件上传请求,通过 RPC 与 NameNode 建立通讯,NameNode检查目标文件是否已存在,父目录是否存在,返回是否可以上传;
2、 client 请求第一个 block 该传输到哪些 DataNode 服务器上;
3、 NameNode 根据配置文件中指定的备份数量及副本放置策略进行文件分配,返回可用的 DataNode 的地址,如:A,B,C;
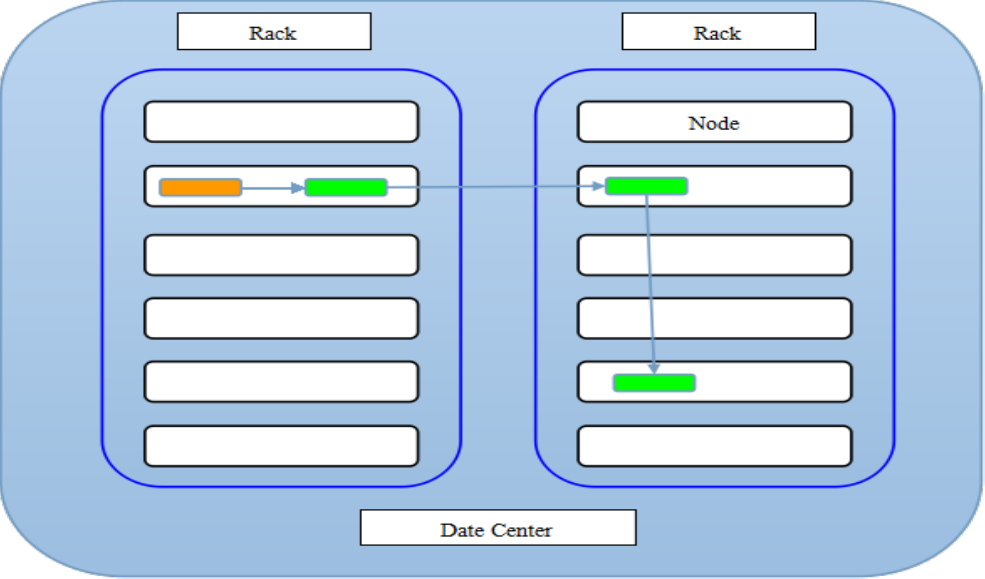
注:默认存储策略由 BlockPlacementPolicyDefault 类支持。也就是日常生活中提到最经典的 3 副本策略 。
1st replica 如果写请求方所在机器是其中一个 datanode,则直接存放在本地,否则随机在集群中选择一个 datanode.
2nd replica 第二个副本存放于不同第一个副本的所在的机架.
3rd replica 第三个副本存放于第二个副本所在的机架,但是属于不同的节点
4、 client 请求 3 台 DataNode 中的一台 A 上传数据(本质上是一个 RPC 调用,建立 pipeline),A 收到请求会继续调用 B,然后 B 调用 C,将整个pipeline 建立完成,后逐级返回 client;
5、 client 开始往 A 上传第一个 block(先从磁盘读取数据放到一个本地内存缓存),以 packet 为单位(默认 64K),A 收到一个 packet 就会传给 B,B 传给 C;A 每传一个 packet 会放入一个应答队列等待应答。
6、 数据被分割成一个个 packet 数据包在 pipeline 上依次传输,在pipeline 反方向上,逐个发送 ack(命令正确应答),最终由 pipeline中第一个 DataNode 节点 A 将 pipeline ack 发送给 client;
7、 当一个 block 传输完成之后,client 再次请求 NameNode 上传第二个block 到服务器。
详细步骤图:
3.2 . HDFS 读数据流程
详细步骤解析:
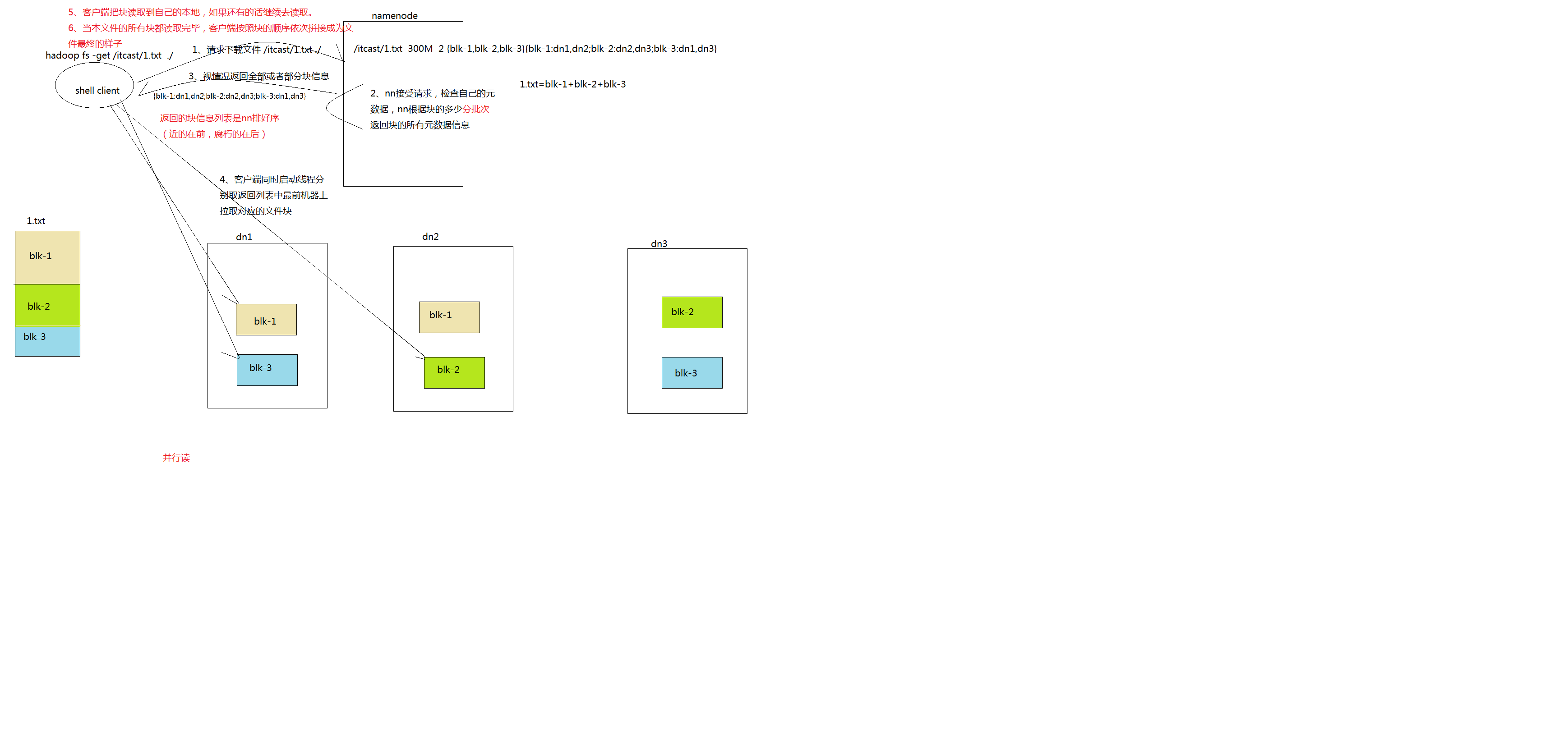
1、 Client 向 NameNode 发起 RPC 请求,来确定请求文件 block 所在的位置;
2、 NameNode会视情况返回文件的部分或者全部block列表,对于每个block,NameNode 都会返回含有该 block 副本的 DataNode 地址;
3、 这些返回的 DN 地址,会按照集群拓扑结构得出 DataNode 与客户端的距离,然后进行排序,排序两个规则:网络拓扑结构中距离 Client 近的排靠前;心跳机制中超时汇报的 DN 状态为 STALE,这样的排靠后;
4、 Client 选取排序靠前的 DataNode 来读取 block,如果客户端本身就是DataNode,那么将从本地直接获取数据;
5、 底层上本质是建立 Socket Stream(FSDataInputStream),重复的调用父类 DataInputStream 的 read 方法,直到这个块上的数据读取完毕;
6、 当读完列表的 block 后,若文件读取还没有结束,客户端会继续向NameNode 获取下一批的 block 列表;
7、 读取完一个 block 都会进行 checksum 验证,如果读取 DataNode 时出现错误,客户端会通知 NameNode,然后再从下一个拥有该 block 副本的DataNode 继续读。
8、 read 方法是并行的读取 block 信息,不是一块一块的读取;NameNode 只是返回Client请求包含块的DataNode地址,并不是返回请求块的数据;
9、 最终读取来所有的 block 会合并成一个完整的最终文件。
详细步骤图:
HDFS原理的更多相关文章
- HDFS原理介绍
HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.是根据google发表的论文翻版的.论文为GFS(Google File System)Googl ...
- HDFS 原理、架构与特性介绍--转载
原文地址:http://www.uml.org.cn/sjjm/201309044.asp 本文主要讲述 HDFS原理-架构.副本机制.HDFS负载均衡.机架感知.健壮性.文件删除恢复机制 1:当前H ...
- Hadoop之HDFS原理及文件上传下载源码分析(上)
HDFS原理 首先说明下,hadoop的各种搭建方式不再介绍,相信各位玩hadoop的同学随便都能搭出来. 楼主的环境: 操作系统:Ubuntu 15.10 hadoop版本:2.7.3 HA:否(随 ...
- Hadoop之HDFS原理及文件上传下载源码分析(下)
上篇Hadoop之HDFS原理及文件上传下载源码分析(上)楼主主要介绍了hdfs原理及FileSystem的初始化源码解析, Client如何与NameNode建立RPC通信.本篇将继续介绍hdfs文 ...
- 【Hadoop】HDFS原理、元数据管理
1.HDFS原理 2.元数据管理原理
- HDFS 原理、架构与特性介绍
本文主要讲述 HDFS原理-架构.副本机制.HDFS负载均衡.机架感知.健壮性.文件删除恢复机制 1:当前HDFS架构详尽分析 HDFS架构 •NameNode •DataNode •Senc ...
- HDFS原理及操作
1 环境说明 部署节点操作系统为CentOS,防火墙和SElinux禁用,创建了一个shiyanlou用户并在系统根目录下创建/app目录,用于存放 Hadoop等组件运行包.因为该目录用于安装had ...
- hadoop学习之HDFS原理
HDFS原理 HDFS包括三个组件: NameNode.DataNode.SecondaryNameNode NameNode的作用是存储元数据(文件名.创建时间.大小.权限.与block块映射关系等 ...
- 读Hadoop3.2源码,深入了解java调用HDFS的常用操作和HDFS原理
本文将通过一个演示工程来快速上手java调用HDFS的常见操作.接下来以创建文件为例,通过阅读HDFS的源码,一步步展开HDFS相关原理.理论知识的说明. 说明:本文档基于最新版本Hadoop3.2. ...
- 【转载】经典漫画讲解HDFS原理
分布式文件系统比较出名的有HDFS 和 GFS,其中HDFS比较简单一点.本文是一篇描述非常简洁易懂的漫画形式讲解HDFS的原理.比一般PPT要通俗易懂很多.不难得的学习资料. 1.三个部分: 客户 ...
随机推荐
- JIAVA知识点整理
Java具有垃圾回收机制,程序退出之后,使用的所有内存全部都将被释放,如要保存数据你就要建立文件,因为当保存时是保存在运行内存中的. int 有返回值void 不需要返回值 1.判断语句if else ...
- %02hhX
大家经常会遇到将 调试信息例如从网络收到的数据包 或者 转换后的数据 打印出来,调试问题. 如果以ascii码打印的话,控制字符和ascii码以外的字符不能很好的查看具体值(看不到,或者乱码,尤其对于 ...
- 040同步条件event
条件同步和条件变量同步差不多意思,只是少了锁功能,因为条件同步设计于不访问共享资源的条件环境,event=threading.Event():条件环境对象,初始值为False.event.isSet( ...
- Webpack笔记(一)——从这里入门Webpack
准备了挺久,一直想要好好深入了解一下Webpack,之前一直嫌弃Webpack麻烦,偏向于Parcel这种零配置的模块打包工具一些,但是实际上还是Webpack比较靠谱,并且Webpack功能更加强大 ...
- Eclipse Ctrl + Shift + O in IntelliJ IDEA
In Eclipse, you press CTRL + SHIFT + O “Organize Imports” to import packages automatically. For Inte ...
- 文件是数据(字节)流的抽象-为什么C++中会把文件操作抽象为fstream?
这不过是返祖罢了.正确的问题是为什么会把数据流抽象成文件. 设备-字节流-文件. 一切皆为文件,所有不同种类的类型都被抽象成文件(比如:块设备,socket套接字,pipe队列). 文件抽象为数据流一 ...
- BZOJ2431:[HAOI2009]逆序对数列(DP,差分)
Description 对于一个数列{ai},如果有i<j且ai>aj,那么我们称ai与aj为一对逆序对数.若对于任意一个由1~n自然数组成的 数列,可以很容易求出有多少个逆序对数.那么逆 ...
- java8的4大核心函数式接口
//java8的4大核心函数式接口//1.Consumer<T>:消费性接口//需求:public void happy(double money, Consumer<Double& ...
- Objective-C中,ARC下的 strong和weak指针原理解释
Objective-C中,ARC下的 strong和weak指针原理解释 提示:本文中所说的"实例变量"即是"成员变量","局部变量"即是& ...
- MyEclipse 远程调试Tomcat
当Web项目部署在服务器之后,当项目出现问题的时候就需要远程调试[远程调试的代码要与本地代码一致] 配置远程调试的具体步骤如下: 1.Linux 中配置tomcat在catalina.sh中添加如下C ...