【已解决】BeautifulSoup已经获得了Unicode的Soup但是print出来却是乱码
【问题】
某人遇到的问题:
关于BeautifulSoup抓取表格及SAE数据库导入的问题(跪求大神帮忙)
简单说就是:
用如下代码:
|
1
2
3
4
5
6
7
|
import re,urllib2from BeautifulSoup import BeautifulSoupfrom urllib import urlopensoup = BeautifulSoup(doc,fromEncoding="GB2312")这里怎么改也没用a=soup.findAll("td")print a |
但是得到的打印输出还是显示的是乱码:
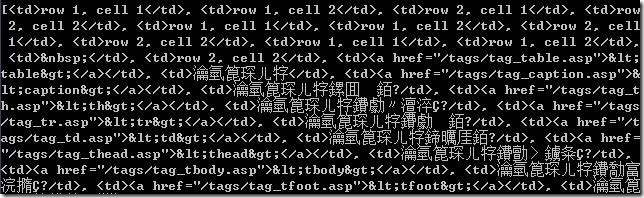
【解决过程】
1. 此处专门通过实际测试,然后再去查证资料,最终,完整的代码和解释,如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
|
#!/usr/bin/python# -*- coding: utf-8 -*-"""Function:【已解决】BeautifulSoup已经获得了Unicode的Soup但是print出来却是乱码Author: Crifan LiVersion: 2013-05-30Contact: http://www.crifan.com/contact_me/""" import re,urllib2from BeautifulSoup import BeautifulSoupfrom urllib import urlopen def scrapeW3school(): #soup = BeautifulSoup(html); #此句效果是一样的: #实测结果是:不加fromEncoding,也是可以自动正确(去判断原始的字符编码为GB2312,然后去)解析(出后来的Unicode的soup)的 soup = BeautifulSoup(html, fromEncoding="GB2312"); #print "soup=",soup; allTdSoup = soup.findAll("td"); print "type(allTdSoup)=",type(allTdSoup); #type(allTdSoup)= <class 'BeautifulSoup.ResultSet'>,但是实际上算是个List print "len(allTdSoup)=",len(allTdSoup); #len(allTdSoup)= 32,此处List的长度是32 print "allTdSoup=",allTdSoup; # allTdSoup= [<td>row 1, cell 1</td>, <td>row 1, cell 2</td>, <td>row 2, ......, <td><a href="/tags/tag_tfoot.asp"><tfoot></a></td> # , <td>瀹氫箟琛ㄦ牸鐨勯〉鑴氥€?/td>, <td><a href="/tags/tag_col.asp"><col></a></td>, <td>瀹氫箟鐢ㄤ簬琛ㄦ牸鍒楃殑灞 # 炴€с€?/td>, <td><a href="/tags/tag_colgroup.asp"><colgroup></a></td>, <td>瀹氫箟琛ㄦ牸鍒楃殑缁勩€?/td>] #此处,看起来是乱码,但是实际上,此处得到的allTdSoup是个列表,而其中的每个soup,虽然内部编码都是正常的unicode了 #但还是会打印出来乱码,那是因为: #1.先看官网的解释: #"当你调用__str__,prettify或者renderContents时, 你可以指定输出的编码。默认的编码(str使用的)是UTF-8。" #所以: #此处,对于去打印allTdSoup,即去打印一个soup的List,所以,针对List中的每个soup(其本质是个对象),而将其输出为字符串的话,默认是调用其__str__属性 #所以就相当于: #针对allTdSoup中的每个soup: # 调用该soup的__str__获得对应的字符串(表示的该soup的内容) #最终组合输出你所看到的["xxx", "xxx", ...]之类的结果, #其中,"xxx",就是对应的每个soup.__str__的结果 #而此处的每个soup的__str__的值: #如官网所述,默认是UTF-8的编码 #所以,此处获得的字符串是UTF-8编码的字符串, #所以print输出到此处cmd #而cmd是GBK编码 #所以,将UTF-8编码的字符,在GBK的cmd中显示,就显示出乱码了 #其中: #(1)如果对于cmd是GBK不了解,去看: #设置字符编码:简体中文GBK/英文 #http://www.crifan.com/files/doc/docbook/soft_dev_basic/release/html/soft_dev_basic.html#cmd_encoding #(2)如果对于GBK,UTF-8本身不了解,去看: #字符编码详解 #(3)针对于soup本身,其实已经是Unicode编码,所以可以通过官网所说的,指定__str__输出时的编码为GBK,以使得此处正确显示非乱码的中文 for eachTdSoup in allTdSoup: print "type(eachTdSoup)=",type(eachTdSoup); #type(eachTdSoup)= <type 'instance'>,说明类型是BeautifulSoup的实例instance print "eachTdSoup.string=",eachTdSoup.string; #输出soup的string属性,即该tag中的字符串内容部分,其本身已经是Unicode,所以可以正常输出非乱码的中文 print "type(eachTdSoup.string)=",type(eachTdSoup.string); #但是要注意一下,此处不是Unicode类型,而是:type(eachTdSoup.string)= <class 'BeautifulSoup.NavigableString'> print "eachTdSoup=",eachTdSoup; #直接输出soup本身,所以相当于:eachTdSoup.__str__ == eachTdSoup.__str__("UTF-8"),所以遇到中文时是乱码 print "eachTdSoup.renderContents()=",eachTdSoup.renderContents(); #直接输出内容本身,默认也是用的是UTF-8,所以遇到中文时也是乱码 print "eachTdSoup.__str__('GBK')=",eachTdSoup.__str__('GBK');#专门指定了GBK编码,所以可以正常显示非乱码的中文 #摘录其中部分输出: # type(eachTdSoup)= <type 'instance'> # eachTdSoup.string= row 1, cell 1 # type(eachTdSoup.string)= <class 'BeautifulSoup.NavigableString'> # eachTdSoup= <td>row 1, cell 1</td> # eachTdSoup.renderContents()= row 1, cell 1 # eachTdSoup.__str__('GBK')= <td>row 1, cell 1</td> # ...... # type(eachTdSoup)= <type 'instance'> # eachTdSoup.string= 定义表格列的组。 # type(eachTdSoup.string)= <class 'BeautifulSoup.NavigableString'> # eachTdSoup= <td>瀹氫箟琛ㄦ牸鍒楃殑缁勩€?/td> # eachTdSoup.renderContents()= 瀹氫箟琛ㄦ牸鍒楃殑缁勩€ # eachTdSoup.__str__('GBK')= <td>定义表格列的组。</td> # #(4)另外,关于BeautifulSoup可以根据html中的charset猜测其编码的事情,不了解的去看: #【整理】关于HTML网页源码的字符编码(charset)格式(GB2312,GBK,UTF-8,ISO8859-1等)的解释 if __name__ == "__main__": scrapeW3school(); |
【总结】
所以说:
表面上看起来从BeautifulSoup解析后得到的soup,打印出来是乱码,但是实际上其本身已经是,正确的(从原始的GB2312编码)解析(为Unicode)后的了。
之所以乱码,那是因为,打印soup时,调用的是__str__,其默认是UTF-8,所以输出到GBK的cmd中,才显示是乱码。
总结下来就是:
非得搞懂了:
各种编码本身的逻辑:啥是GBK,啥是UTF-8,啥是Unicode
BeautifulSoup的逻辑:可以通过fromEncoding去正确的解析html为Unicode编码的
print一个对象的逻辑:内部是调用对象的__str__得到对应的字符串的,此处对应的是soup的__str__
soup的__str__的逻辑:默认编码是UTF-8
cmd的逻辑:(中文的系统中)编码为GBK
然后才能明白此处的问题的根本的原因的。
【已解决】BeautifulSoup已经获得了Unicode的Soup但是print出来却是乱码的更多相关文章
- 【已解决】python中文字符乱码(GB2312,GBK,GB18030相关的问题)
http://againinput4.blog.163.com/blog/static/1727994912011111011432810/ [已解决]python中文字符乱码(GB2312,GB ...
- Microsoft.Office.Interop.Excel, Version=12.0.0.0版本高于引用的程序集(已解决)
Microsoft.Office.Interop.Excel, Version=12.0.0.0版本高于引用的程序集(已解决) 论坛里的帮助:http://bbs.csdn.net/topics/39 ...
- 解决 git 中文路径显示 unicode 代码的问题
解决 git 中文路径显示 unicode 代码的问题 当被修改的文件中带有中文字符时,中文字符会被转换为 unicode 代码,看不出原来的文件名. 这时,只要配置 :: git config -- ...
- 使用Notepad++编码编译时报错(已解决?)
使用Notepad++编码编译时报错(已解决?) 使用Notepad++编码,编译的时候经常会报错,说什么GBK编码啥啥啥~~~但同样的编码用ECLIPSE就没有问题.再有,用记事本把他保存成ANSI ...
- 已解决】Sublime中运行带input或raw_input的Python代码出错:EOFError: EOF when reading a line(转)
[问题] 在折腾: [已解决]Sublime Text 2中运行Python程序出错:The system cannot find the file specified 的过程中,虽然解决了找不到py ...
- 【已解决】Android ADT中增大AVD内存后无法启动:emulator failed to allocate memory 8
[问题] 折腾: [已解决]Android ADT中增大AVD内存后无法启动:emulator failed to allocate memory 8 过程中,增大对应AVD的内存为2G后,结果无法启 ...
- Access中出现改变字段“自己主动编号”类型,不能再改回来!(已解决)
Access中出现改变字段"自己主动编号"类型,不能再改回来! (已解决) 一次把access中的自增字段改成了数值,再改回自增时,提示:在表中输入了数据之后,则不能将不论什么字段 ...
- sqlserver,执行生成脚本时“引发类型为“System.OutOfMemoryException”的异常”(已解决)
sqlserver,执行生成脚本时“引发类型为“System.OutOfMemoryException”的异常”(已解决) 出现此错误主要是因为.sql的脚本文件过大(一般都超过100M)造成内存无法 ...
- LOL是什么意思? - 已解决 - 搜狗问问
LOL是什么意思? - 已解决 - 搜狗问问 N A T S U . |分类:QQ工具栏 2009-05-04 LOL是什么意思? 满意答案 Shim Nyong 19级 2009-05-04 LOL ...
随机推荐
- SQL Server 数据类型映射 (ADO.NET)
SQL Server 数据类型映射 (ADO.NET) .NET Framework 3.5 更新:November 2007 SQL Server 和 .NET Framework 基于不同的类型系 ...
- 标准C++ 字符串处理增强函数
转自:http://dewei.iteye.com/blog/1566734 //标准C++ string 去除首尾空白字符 2012-8-12 By Dewei static inline void ...
- andriod开发,简单的封装网络请求并监听返回.
一.为什么封装 因为android 4.0 以后的发送网络请求必须要放到异步线程中,而异步线程必须跟handle合作才能更新主线程中的UI,所以建议用一个类继承handler来异步处理网络请求. 二. ...
- 配置错误 在唯一密钥属性“fileExtension”设置为“.log”时,无法添加类型为“mimeMap”的重复集合项
错误提示: 配置错误 在唯一密钥属性“fileExtension”设置为“.log”时,无法添加类型为“mimeMap”的重复集合项 配置文件 \\?\D:\www\abc\web.config 出现 ...
- #定位系统性能瓶颈# strace & ltrace
strace和ltrace分别相应的是系统调用和库函数调用, 系统调用实际上就是指最底层的一个调用,在linux程序设计里面就是底层调用的意思,面向的是硬件. 而库函数调用则面向的是应用开发的.相当于 ...
- 脚本命令高级Bash脚本编程指南(31):数学计算命令
题记:写这篇博客要主是加深自己对脚本命令的认识和总结实现算法时的一些验经和训教,如果有错误请指出,万分感谢. 高等Bash脚本编程指南(31):数学盘算命令 成于坚持,败于止步 操作数字 factor ...
- C++中使用union的几点思考(转)
C++中使用union的几点思考 大卫注:这段时间整理旧资料,看到一些文章,虽然讲的都是些小问题,不大可能用到,但也算是一个知识点,特整理出来与大家共享.与此相关的那篇文章的作者的有些理解是错误的,我 ...
- 使用IIS 7.0 Smooth Streaming 优化视频服务
http://www.cnblogs.com/dudu/archive/2013/06/08/iis_webserver_settings.html (支持高并发的IIS Web服务器常用设置) ht ...
- onClick,onServerClick,onClientClick
<asp:button id=button1 runat=server test=button1 onclick=button1_onclick/> <input type=butt ...
- 简化LINUX的命令输入 简化linux命令
在LINUX中,有很多常用的命令,常用的命令我们可以熟练的记忆,但是对于不经常使用的命令恐怕是需要翻阅手册了,但是我们可以简化这些命令的输入来达到简便记忆的效果. 这里以BSH为例: 编辑/etc/b ...