医疗在线OLAP场景下基于Apache Hudi 模式演变的改造与应用
背景
在 Apache Hudi支持完整的Schema演变的方案中(https://mp.weixin.qq.com/s/rSW864o2YEbHw6oQ4Lsq0Q), 读取方面,只完成了SQL on Spark的支持(Spark3以上,用于离线分析场景),Presto(用于在线OLAP场景)及Apache Hive(Hudi的bundle包)的支持,在正式发布版本中(Hudi 0.12.1, PrestoDB 0.277)还未支持。在当前的医疗场景下,Schema变更发生次数较多,且经常使用Presto读取Hudi数据进行在线OLAP分析,在读到Schema变更过的表时很可能会产生错误结果,造成不可预知的损失,所以必须完善Presto在读取方面对Schema完整演变的支持。
另外用户对使用presto对Hudi读取的实时性要求较高,之前的方案里Presto只支持Hudi的读优化方式读取。读优化的情况下,由于默认的布隆索引有如下行为:
- insert 操作的数据,每次写入提交后能够查询到;
- update,delete操作的数据必须在发生数据合并后才能读取到;
- insert与(update,delete)操作 presto 能够查询到的时间不一致;
- 所以必须增加presto对hudi的快照查询支持。
由于Presto分为两个分支(Trino和PrestoDB),其中PrestoDB的正式版本已经支持快照查询模式,而Trino主线还不存在这个功能,所以优先考虑在PrestoDB上实现,我们基于Trino的方案也在开发中。
计划基于Prestodb的Presto-Hudi模块改造,设计自 RFC-44: Hudi Connector for Presto。单独的Hudi连接器可以抛开当前代码的限制,高效地进行特定优化、添加新功能、集成高级功能并随着上游项目快速发展。
术语说明
read_optimized(读优化):COW表和MOR表的ro表,只读取parquet文件的查询模式
snapshot(快照):MOR表的rt表,读取log文件和parquet并计算合并结果的查询模式
现状:
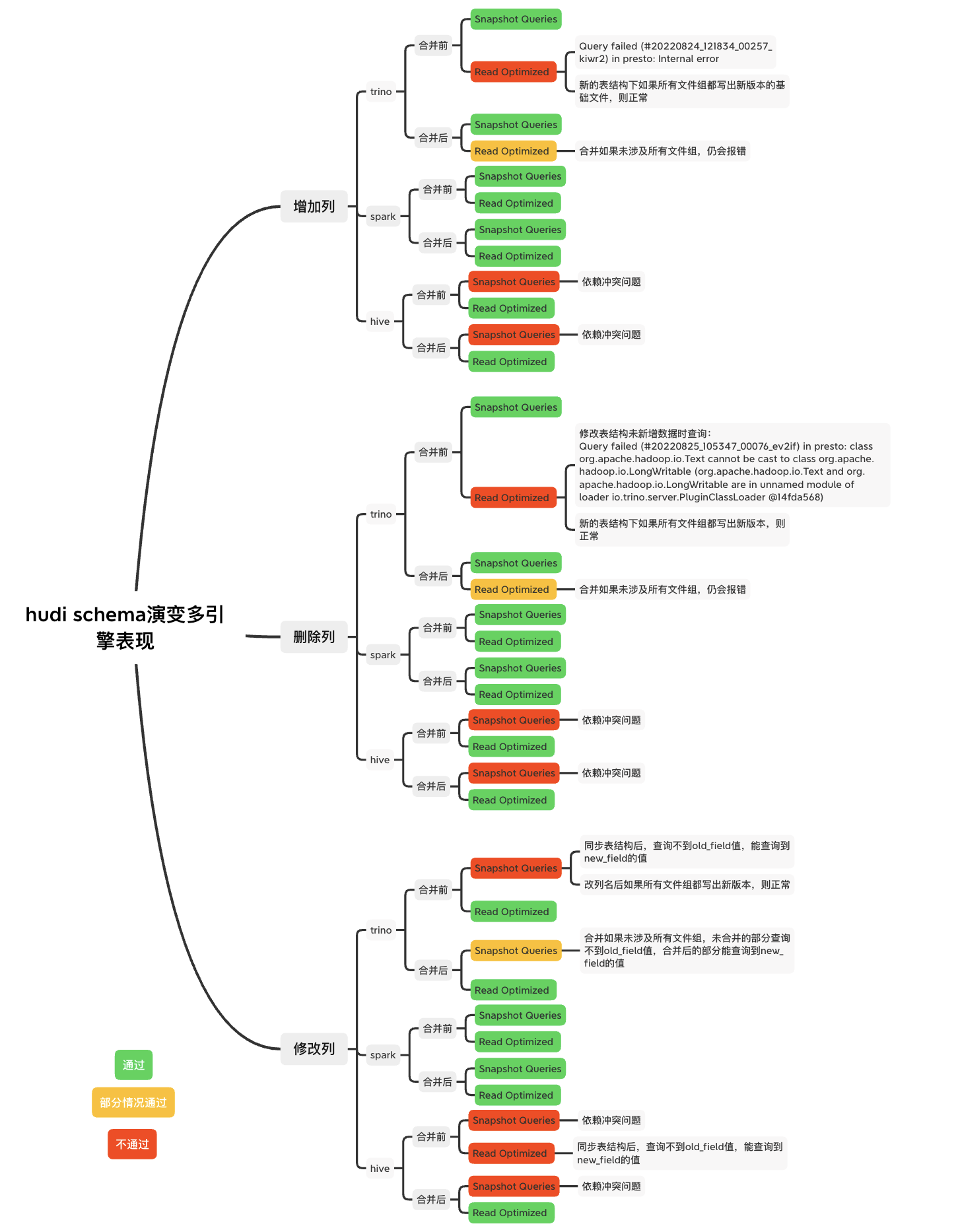
Hudi的Schema演变过程中多种引擎的表现
其中trino是以官方360版本为基础开发的本地版本,部分参考某打开状态的pr,使其支持了快照查询
Hive对Hudi支持的情况
hive使用hudi提供的hudi-hadoop-mr模块的InputFormat接口,支持完整schema的功能在10月28日合入Hudi主线。
Trino对Hudi支持的情况
Trino版本主线分支无法用快照模式查询。Hudi连接器最终于22年9月28日合入主线,仍没有快照查询的功能。本地版本基于trino360主动合入社区中打开状态的pr(Hudi MOR changes),基于hive连接器完成了快照查询能力。
PrestoDB对Hudi支持的情况
PrestoDB版本主线分支支持Hudi连接器,本身没有按列位置获取列值的功能,所以没有串列问题,并且支持快照查询模式。
改造方案
版本
Hudi: 0.12.1
Presto: 0.275
该模块的设计如下
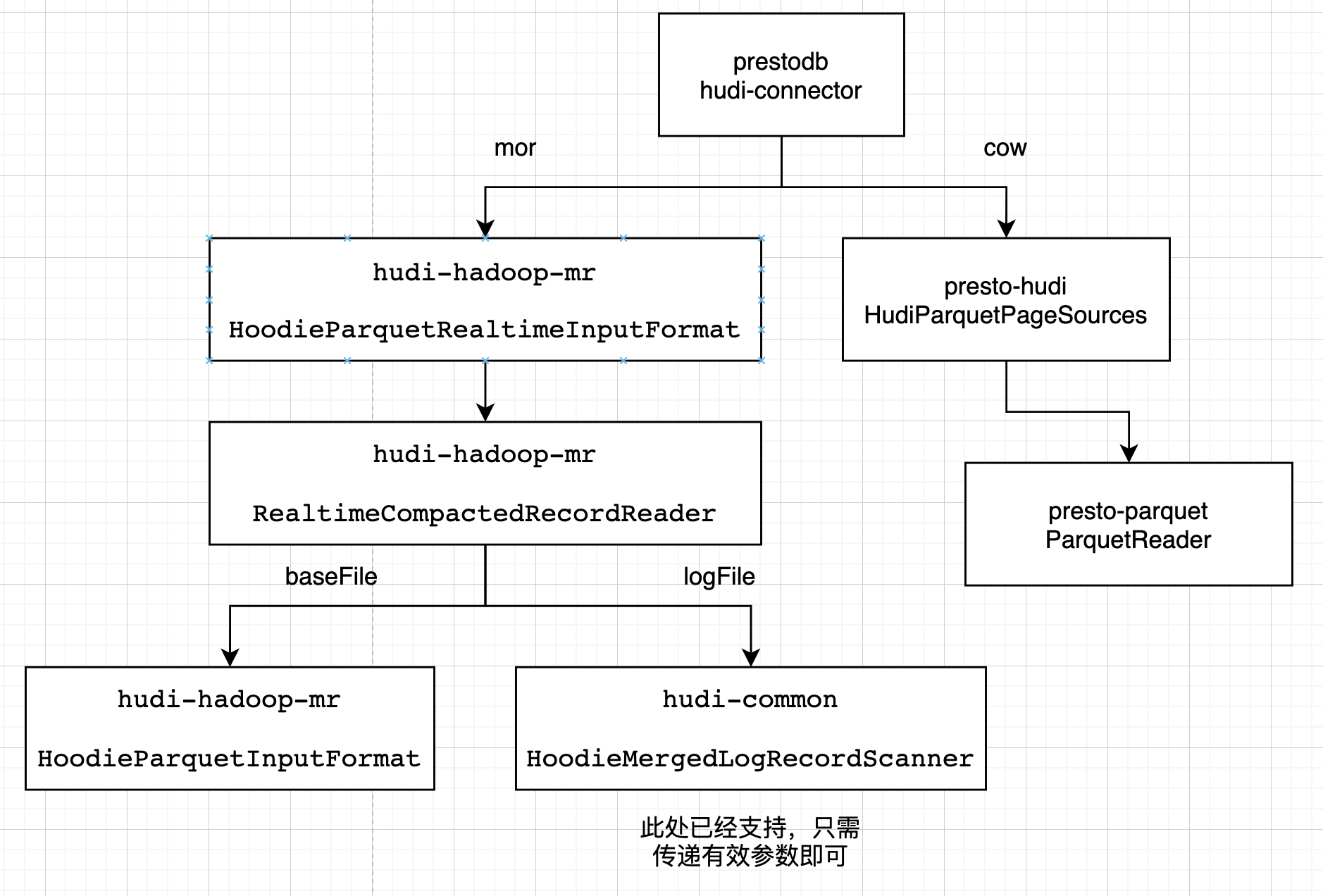
读优化
Presto 会使用它自己优化的方式读parquet文件。在presto-hudi的HudiPageSourceProvider -> HudiParquetPageSources -> 最终使用presto-parquet 的 ParquetReader读取
快照
Presto 针对mor表的快照读,会使用hudi提供的huid-hadoop-mr的InputFormat接口。在presto-hudi的HudiPageSourceProvider -> HudiRecordCursors里创建 HoodieParquetRealtimeInputFormat -> 获取RealtimeCompactedRecordReader,基础文件使用HoodieParquetInputFormat的getRecordReader,日志文件使用HoodieMergedLogRecordScanner扫描
读优化的改造
基本思想:在presto-hudi模块的HudiParquetPageSources中,获取文件和查询的 InternalSchema ,merge后与presto里的schema列信息转换,进行查询。
具体步骤:
- 使用TableSchemaResolver的getTableInternalSchemaFromCommitMetadata方法获取最新的完整InternalSchema
- 使用HudiParquetPageSources类的createParquetPageSource方法传入参数regularColumns(List),与完整InternalSchema通过InternalSchemaUtils.pruneInternalSchema方法获取剪枝后的InternalSchema
- 通过FSUtils.getCommitTime方法利用文件名的时间戳获取commitInstantTime,再利用InternalSchemaCache.getInternalSchemaByVersionId方法获取文件的InternalSchema
- 使用InternalSchemaMerger的mergeSchema方法,获取剪枝后的查询InternalSchema和文件InternalSchema进行merge的InternalSchema
- 使用merge后的InternalSchema的列名list,转换为HudiParquetPageSources的requestedSchema,改变HudiParquetPageSources的getDescriptors和getColumnIO等方法逻辑的结果
实现为 https://github.com/prestodb/presto/pull/18557 (打开状态)
快照的改造
基本思想:改造huid-hadoop-mr模块的InputFormat,获取数据和查询的 InternalSchema ,将merge后的schema列信息设置为hive任务所需的属性,进行查询。
具体步骤:
1.基础文件支持完整schema演变,spark-sql的实现此处无法复用,添加转换类,在HoodieParquetInputFormat中使用转换类,根据commit获取文件schema,根据查询schema和文件schema进行merge,将列名和属性设置到job的属性里serdeConstants.LIST_COLUMNS,ColumnProjectionUtils.READ_COLUMN_NAMES_CONF_STR,serdeConstants.LIST_COLUMN_TYPES;
2.日志文件支持完整schema演变,spark-sql的实现此处可以复用。HoodieParquetRealtimeInputFormat的RealtimeCompactedRecordReader中,使用转换类设置reader对象的几个schema属性,使其复用现有的merge数据schema与查询schema的逻辑。
已经存在pr可以达到目标 https://github.com/apache/hudi/pull/6989 (合入master,0.13)
Presto的配置
${presto_home}/etc/catalog/hudi.properties,基本复制hive.properties;主要修改为
connector.name=hudi
Presto的部署
此处分别为基于hudi0.12.1和prestodb的release0.275合入pr后打的包,改动涉及文件不同版本间差异不大,无需关注版本问题
分别将mor表改造涉及的包:
hudi-presto-bundle-0.12.1.jar
以及cow表改造涉及的包:
presto-hudi-0.275.1-SNAPSHOT.jar
放入${presto_home}/etc/catalog/hudi.propertiesplugin/hudi
重启presto服务
开发过程遇到的问题及解决

总结
当前已经实现PrestoDB对Hudi的快照读,以及对schema完整演变的支持,满足了大批量表以MOR的表格式快速写入数据湖,且频繁变更表结构的同时,能够准确实时地进行OLAP分析的功能。但由于Trino社区更加活跃,以前的很多功能基于Trino开发,下一步计划改造Trino,使其完整支持快照读与两种查询模式下的schema完整演变。
医疗在线OLAP场景下基于Apache Hudi 模式演变的改造与应用的更多相关文章
- 基于Apache Hudi构建数据湖的典型应用场景介绍
1. 传统数据湖存在的问题与挑战 传统数据湖解决方案中,常用Hive来构建T+1级别的数据仓库,通过HDFS存储实现海量数据的存储与水平扩容,通过Hive实现元数据的管理以及数据操作的SQL化.虽然能 ...
- 字节跳动基于Apache Hudi构建EB级数据湖实践
来自字节跳动的管梓越同学一篇关于Apache Hudi在字节跳动推荐系统中EB级数据量实践的分享. 接下来将分为场景需求.设计选型.功能支持.性能调优.未来展望五部分介绍Hudi在字节跳动推荐系统中的 ...
- 基于 Apache Hudi 和DBT 构建开放的Lakehouse
本博客的重点展示如何利用增量数据处理和执行字段级更新来构建一个开放式 Lakehouse. 我们很高兴地宣布,用户现在可以使用 Apache Hudi + dbt 来构建开放Lakehouse. 在深 ...
- 基于 Apache Hudi 极致查询优化的探索实践
摘要:本文主要介绍 Presto 如何更好的利用 Hudi 的数据布局.索引信息来加速点查性能. 本文分享自华为云社区<华为云基于 Apache Hudi 极致查询优化的探索实践!>,作者 ...
- 基于 Apache Hudi 构建增量和无限回放事件流的 OLAP 平台
1. 摘要 在本博客中,我们将讨论在构建流数据平台时如何利用 Hudi 的两个最令人难以置信的能力. 增量消费--每 30 分钟处理一次数据,并在我们的组织内构建每小时级别的OLAP平台 事件流的无限 ...
- 基于Apache Hudi 的CDC数据入湖
作者:李少锋 文章目录: 一.CDC背景介绍 二.CDC数据入湖 三.Hudi核心设计 四.Hudi未来规划 1. CDC背景介绍 首先我们介绍什么是CDC?CDC的全称是Change data Ca ...
- OnZoom 基于Apache Hudi的流批一体架构实践
1. 背景 OnZoom是Zoom新产品,是基于Zoom Meeting的一个独一无二的在线活动平台和市场.作为Zoom统一通信平台的延伸,OnZoom是一个综合性解决方案,为付费的Zoom用户提供创 ...
- KLOOK客路旅行基于Apache Hudi的数据湖实践
1. 业务背景介绍 客路旅行(KLOOK)是一家专注于境外目的地旅游资源整合的在线旅行平台,提供景点门票.一日游.特色体验.当地交通与美食预订服务.覆盖全球100个国家及地区,支持12种语言和41种货 ...
- Uber基于Apache Hudi构建PB级数据湖实践
1. 引言 从确保准确预计到达时间到预测最佳交通路线,在Uber平台上提供安全.无缝的运输和交付体验需要可靠.高性能的大规模数据存储和分析.2016年,Uber开发了增量处理框架Apache Hudi ...
- 触宝科技基于Apache Hudi的流批一体架构实践
1. 前言 当前公司的大数据实时链路如下图,数据源是MySQL数据库,然后通过Binlog Query的方式消费或者直接客户端采集到Kafka,最终通过基于Spark/Flink实现的批流一体计算引擎 ...
随机推荐
- 通过Thread Pool Executor类解析线程池执行任务的核心流程
摘要:ThreadPoolExecutor是Java线程池中最核心的类之一,它能够保证线程池按照正常的业务逻辑执行任务,并通过原子方式更新线程池每个阶段的状态. 本文分享自华为云社区<[高并发] ...
- 前端三件套 HTML+CSS+JS基础知识内容笔记
HTML基础 目录 HTML基础 HTML5标签 doctype 标签 html标签 head标签 meta标签 title标签 body标签 文本和超链接标签 标题标签 段落标签 换行标签 水平标签 ...
- UDP协议编程
#接收代码 import socket # 使用IPV4协议,使用UDP协议传输数据 s=socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # 绑定端口 ...
- MySQL用户也可以是个角色
前言 角色(Role),可以认为是一些权限的集合,一直是存在各个数据库中,比如Oracle.SQL Server.OceanBase等,MySQL 自从 8.0 release 才引入角色这个概念. ...
- .Net CLR异常简析
楔子 前面一篇研究了下C++异常的,这篇来看下,CLR的异常内存模型,实际上都是一个模型,承继自windows异常处理机制.不同的是,有VC编译器(vcruntime.dll)接管的部分,被CLR里面 ...
- MasaFramework -- 异常处理
前言 在程序设计中,我们会遇到各种各样的异常问题,一个异常处理不仅仅可以帮助开发者快速的定位问题,也可以给用户更好的使用体验,那么我们在AspNetCore项目中如何捕获以及处理异常呢? 而对应Asp ...
- 成功解决:Can‘t find Python executable “python“, you can set the PYTHON env variable.
今天跑公司新项目的时候.运行前端vue.报了一个关于python的错误.就离谱 1.问题报错全部代码 actual version of core-js. npm ERR! code 1 npm ER ...
- 题解 P6745 『MdOI R3』Number
前言 不知道是不是正解但是觉得挺好理解. 科学计数法 将一个数表示为\(a\times 10^x\) 的形式.其中\(a\leq10\),\(x\) 为整数. \(\sf Solution\) 其实这 ...
- Istio(十一):向istio服务网格中引入虚拟机
目录 一.模块概览 二.系统环境 三.虚拟机负载 3.1 虚拟机负载 3.2 单网络架构 3.3 多网络架构 3.4 Istio 中如何表示虚拟机工作负载? 四.实战:向istio Mesh中引入虚拟 ...
- webpack中 hash chunkhash
hash一般是结合CDN缓存来使用,通过webpack构建之后,生成对应文件名自动带上对应的MD5值.如果文件内容发生改变的话,那么对应文件hash值也会改变,对应的HTML引用的URL地址也会改变, ...