三十二 Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启
scrapy的每一个爬虫,暂停时可以记录暂停状态以及爬取了哪些url,重启时可以从暂停状态开始爬取过的URL不在爬取
实现暂停与重启记录状态
1、首先cd进入到scrapy项目里
2、在scrapy项目里创建保存记录信息的文件夹
3、执行命令:
scrapy crawl 爬虫名称 -s JOBDIR=保存记录信息的路径
如:scrapy crawl cnblogs -s JOBDIR=zant/001
执行命令会启动指定爬虫,并且记录状态到指定目录
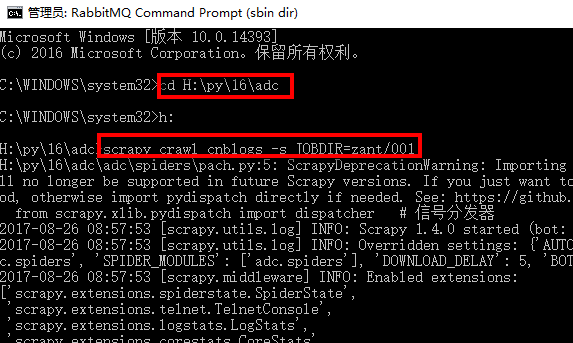
爬虫已经启动,我们可以按键盘上的ctrl+c停止爬虫
停止后我们看一下记录文件夹,会多出3个文件
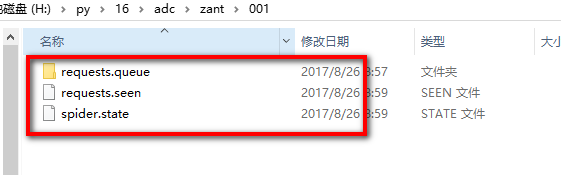
其中的requests.queue文件夹里的p0文件就是URL记录文件,这个文件存在就说明还有未完成的URL,当所有URL完成后会自动删除此文件
当我们重新执行命令:scrapy crawl cnblogs -s JOBDIR=zant/001 时爬虫会根据p0文件从停止的地方开始继续爬取,
三十二 Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启的更多相关文章
- 三十六 Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码
scrapy-redis是一个可以scrapy结合redis搭建分布式爬虫的开源模块 scrapy-redis的依赖 Python 2.7, 3.4 or 3.5,Python支持版本 Redis & ...
- 三十五 Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点
1.分布式爬虫原理 2.分布式爬虫优点 3.分布式爬虫需要解决的问题
- 二十二 Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy模拟登陆和知乎倒立文字验证码识别
第一步.首先下载,大神者也的倒立文字验证码识别程序 下载地址:https://github.com/muchrooms/zheye 注意:此程序依赖以下模块包 Keras==2.0.1 Pillow= ...
- 三十八 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
elasticsearch(搜索引擎)介绍 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.Elasticse ...
- 四十二 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作
注意:前面讲到的各种操作都是一次http请求操作一条数据,如果想要操作多条数据就会产生多次请求,所以就有了mget和bulk批量操作,mget和bulk批量操作是一次请求可以操作多条数据 1.mget ...
- 三十四 Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy信号详解
信号一般使用信号分发器dispatcher.connect(),来设置信号,和信号触发函数,当捕获到信号时执行一个函数 dispatcher.connect()信号分发器,第一个参数信号触发函数,第二 ...
- 三十九 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念
elasticsearch的基本概念 1.集群:一个或者多个节点组织在一起 2.节点:一个节点是集群中的一个服务器,由一个名字来标识,默认是一个随机的漫微角色的名字 3.分片:将索引(相当于数据库)划 ...
- Python分布式爬虫打造搜索引擎完整版-基于Scrapy、Redis、elasticsearch和django打造一个完整的搜索引擎网站
Python分布式爬虫打造搜索引擎 基于Scrapy.Redis.elasticsearch和django打造一个完整的搜索引擎网站 https://github.com/mtianyan/Artic ...
- 四十六 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
前面我们讲到的elasticsearch(搜索引擎)操作,如:增.删.改.查等操作都是用的elasticsearch的语言命令,就像sql命令一样,当然elasticsearch官方也提供了一个pyt ...
随机推荐
- javascript 闭包 内存
- 下拉刷新&上拉加载
效果演示 核心codehtml <ion-view view-title="学生list"> <ion-content > <ion-refreshe ...
- javaScript动画1 offsetWidth、offsetLeft
offsetWidth和offsetHeight <!DOCTYPE html> <html lang="en"> <head> <met ...
- 关于http响应状态码
http状态返回代码 1xx(临时响应) 表示临时响应并需要请求者继续执行操作的状态代码. http状态返回代码 代码 说明 100 (继续) 请求者应当继续提出请求. 服务器返回此代码表示已 ...
- java并发内存模型
java中线程之间的共享变量存储在主内存(java堆)中,每个线程都有一个私有的本地内存,本地内存存储了该线程以读.写共享变量的副本.本地内存是一个抽象概念,并不真实存储.它涵盖了cache,寄存器记 ...
- 新linux系统上rz 与sz命令不可用
使用命令进行安装:yum install lrzsz 即可使用
- Docker-docker制作镜像
一.下载镜像 a.以daocloud为mirror下载Nginx镜像 配置daocloud为mirror,下载Nginx镜像:(daocloud官网登陆后,发现镜像里找到Nginx镜像) 下载Ngin ...
- 为什么 PHP 程序员应该学习使用 Swoole
最近两个月一直在研究 Swoole,研究成果即将在6.21正式开源发布,这段时间没有来水文章,趁着今天放假来水水吧. 借助这篇文章,我希望能够把 Swoole 安利给更多人.虽然 Swoole 可能目 ...
- Python高阶函数(Map、Reduce、Filter)和lambda函数一起使用 ,三剑客
Map函数 map()函数接收两个参数,一个是函数,一个是序列,map将传入的函数依次作用到序列的每个元素,并把结果作为新的list返回. 举例说明 比如我们有一个函数f(x)=x2,要把这个函数作用 ...
- Mac下需要安装的一些软件及常用的配置文件
常用软件配置文件 1..gitconfig # This is Git's per-user configuration file. [user] name = 张文 email = zhangwen ...