MappedByteBuffer以及ByteBufer的底层原理
最近在用java中的ByteBuffer,一直不明所以,尤其是对MappedByteBuffer使用的内存映射这个概念云里雾里。
于是首先补了物理内存、虚拟内存、页面文件、交换区的只是:小科普——物理内存、页面文件、交换区和虚拟内存
然后阅读了ByteBuffer的文章:ByteBuffer使用和实现以及文件内存映射。
Bytebuffer分为两种:间接地和直接的,所谓直接就是指MappedByteBuffer,直接使用内存映射(java的话就意味着在JVM之外分配虚拟地址空间);而间接的ByteBuffer是在JVM的堆上面的,说白了就是管理一群byte数组的包装。
这里面最核心最关键的也即是内存映射了,下面的内容来自这篇文章:内存映射文件原理探索
内存映射:
原理
首先,“映射”这个词,就和数学课上说的“一一映射”是一个意思,就是建立一种一一对应关系,在这里主要是只 硬盘上文件 的位置与进程 逻辑地址空间 中一块大小相同的区域之间的一一对应,如图1中过程1所示。这种对应关系纯属是逻辑上的概念,物理上是不存在的,原因是进程的逻辑地址空间本身就是不存在的。在内存映射的过程中,并没有实际的数据拷贝,文件没有被载入内存,只是逻辑上被放入了内存,具体到代码,就是建立并初始化了相关的数据结构(struct address_space),这个过程有系统调用mmap()实现,所以建立内存映射的效率很高。
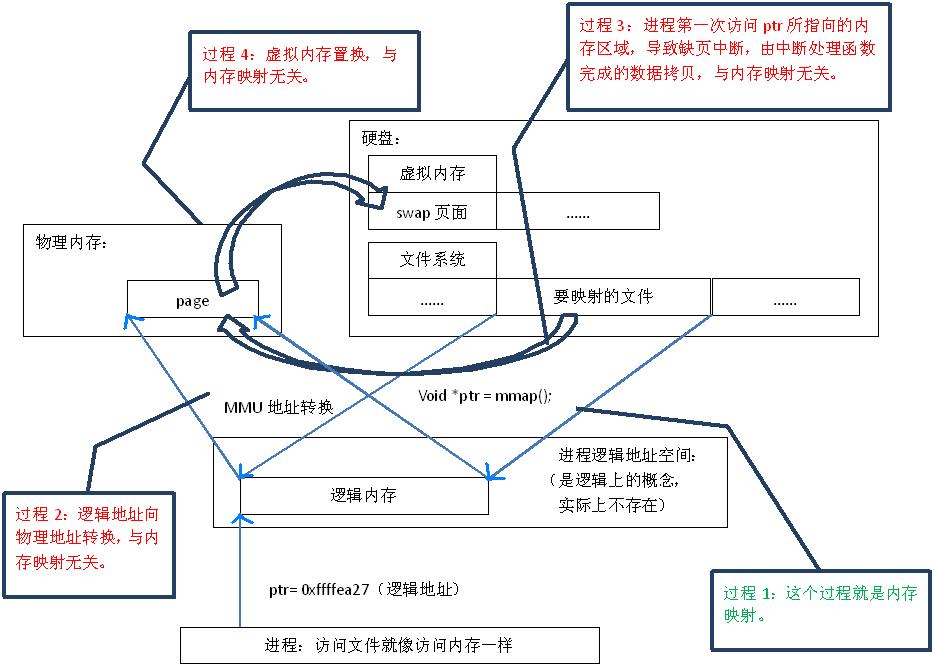
图1.内存映射原理
既然建立内存映射没有进行实际的数据拷贝,那么进程又怎么能最终直接通过内存操作访问到硬盘上的文件呢?那就要看内存映射之后的几个相关的过程了。
mmap()会返回一个指针ptr,它指向进程逻辑地址空间中的一个地址,这样以后,进程无需再调用read或write对文件进行读写,而只需要通过ptr就能够操作文件。但是ptr所指向的是一个逻辑地址,要操作其中的数据,必须通过MMU将逻辑地址转换成物理地址,如图1中过程2所示。这个过程与内存映射无关。
前面讲过,建立内存映射并没有实际拷贝数据,这时,MMU在地址映射表中是无法找到与ptr相对应的物理地址的,也就是MMU失败,将产生一个缺页中断,缺页中断的中断响应函数会在swap中寻找相对应的页面,如果找不到(也就是该文件从来没有被读入内存的情况),则会通过mmap()建立的映射关系,从硬盘上将文件读取到物理内存中,如图1中过程3所示。这个过程与内存映射无关。
如果在拷贝数据时,发现物理内存不够用,则会通过虚拟内存机制(swap)将暂时不用的物理页面交换到硬盘上,如图1中过程4所示。这个过程也与内存映射无关。
效率
从代码层面上看,从硬盘上将文件读入内存,都要经过文件系统进行数据拷贝,并且数据拷贝操作是由文件系统和硬件驱动实现的,理论上来说,拷贝数据的效率是一样的。但是通过内存映射的方法访问硬盘上的文件,效率要比read和write系统调用高,这是为什么呢?原因是read()是系统调用,其中进行了数据拷贝,它首先将文件内容从硬盘拷贝到内核空间的一个缓冲区,如图2中过程1,然后再将这些数据拷贝到用户空间,如图2中过程2,在这个过程中,实际上完成了 两次数据拷贝 ;而mmap()也是系统调用,如前所述,mmap()中没有进行数据拷贝,真正的数据拷贝是在缺页中断处理时进行的,由于mmap()将文件直接映射到用户空间,所以中断处理函数根据这个映射关系,直接将文件从硬盘拷贝到用户空间,只进行了 一次数据拷贝 。因此,内存映射的效率要比read/write效率高。
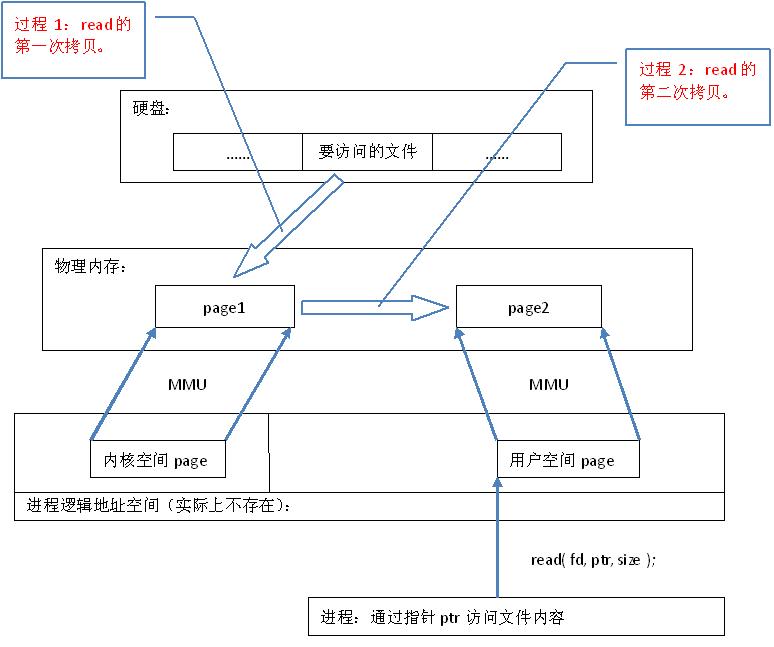
图2.read系统调用原理
MappedByteBuffer以及ByteBufer的底层原理的更多相关文章
- Neo4j图数据库简介和底层原理
现实中很多数据都是用图来表达的,比如社交网络中人与人的关系.地图数据.或是基因信息等等.RDBMS并不适合表达这类数据,而且由于海量数据的存在,让其显得捉襟见肘.NoSQL数据库的兴起,很好地解决了海 ...
- 【T-SQL进阶】02.理解SQL查询的底层原理
本系列[T-SQL]主要是针对T-SQL的总结. [T-SQL基础]01.单表查询-几道sql查询题 [T-SQL基础]02.联接查询 [T-SQL基础]03.子查询 [T-SQL基础]04.表表达式 ...
- spring框架的IOC的底层原理
1.IOC概念:spring容器创建对象并管理 2.IOC的底层原理的具体实现: 1)所使用的技术: (1). dom4j解析xml配置文件 (2).工厂设计模式(解耦合) (3).反射 第一步:配置 ...
- 深入研究Sphinx的底层原理和高级使用
深入研究Sphinx的底层原理和高级使用
- 深入研究Node.js的底层原理和高级使用
深入研究Node.js的底层原理和高级使用
- HashMap的底层原理
简单说: 底层原理就是采用数组加链表: 两张图片很清晰地表明存储结构: 既然是线性数组,为什么能随机存取?这里HashMap用了一个小算法,大致是这样实现: // 存储时: int hash = ke ...
- 操作系统底层原理与Python中socket解读
目录 操作系统底层原理 网络通信原理 网络基础架构 局域网与交换机/网络常见术语 OSI七层协议 TCP/IP五层模型讲解 Python中Socket模块解读 TCP协议和UDP协议 操作系统底层原理 ...
- Servlet底层原理、Servlet实现方式、Servlet生命周期
Servlet简介 Servlet定义 Servlet是一个Java应用程序,运行在服务器端,用来处理客户端请求并作出响应的程序. Servlet的特点 (1)Servlet对像,由Servlet容器 ...
- Spring Aop底层原理详解
Spring Aop底层原理详解(来源于csdn:https://blog.csdn.net/baomw)
随机推荐
- HDU 5428 The Factor 分解因式
题目链接: http://acm.hdu.edu.cn/showproblem.php?pid=5428 The Factor Accepts: 101 Submissions: 811 Tim ...
- cobbler-web 网络安装服务器套件 Cobbler(补鞋匠)
Cobbler作为一个预备工具,使部署RedHat/Centos/Fedora系统更容易,同时也支持Suse和Debian系统的部署. 它提供以下服务集成: * PXE服务支持 * DHCP服务管 ...
- cobbler配置要基于PXE 环境,cobbler是pxe环境的二次封装
一:安装cobbler.httpd yum install -y cobbler httpd 二:启动cobbler.httpd systemctl start cobblerd.service sy ...
- 【week11】回顾
一.回答五个问题 第一次阅读<构建之法>之后的五个问题: 1.关于敏捷,书中说了我理解的就是介绍了敏捷就是“没有既定的计划与文档,马上写代码,随时发牢骚”,但是开发也是需要有一定的流程的, ...
- url传带有汉字的参数乱码解决
url传带有汉字的参数乱码解决 var reg = new RegExp("(^|&)createName=([^&]*)(&|$)"); var r = ...
- 按位与&、按位或|、按位异或^
与1进行位与&运算,值保持不变: 与0进行位与&运算,值清0: 按位与&常用于将整型变量中某些位清0,而其他位保持不变. 与1进行位或|运算,值置1: 与0进行位或|运算,值保 ...
- String Problem HDU - 3374(最大最小表示法+循环节)
题意: 给出一个字符串,问这个字符串经过移动后的字典序最小的字符串的首字符位置和字典序最大的字符串的首字符的位置,和能出现多少次最小字典序的字符串和最大字典序的字符串 解析: 能出现多少次就是求整个字 ...
- [FJWC2018]全排列 DP
题面 题面 题解 (表示第一段文字导致我在考场上没看懂题--因为我以为这个定义是定义在整个排列上的,所以相似 = 相同.结果其实是可以应用在一个区间上--) 首先我们发现,2个区间相似,其实就是离散化 ...
- 洛谷P4606 [SDOI2018]战略游戏 【圆方树 + 虚树】
题目链接 洛谷P4606 双倍经验:弱化版 题解 两点之间必经的点就是圆方树上两点之间的圆点 所以只需建出圆方树 每次询问建出虚树,统计一下虚树边上有多少圆点即可 还要讨论一下经不经过根\(1\)的情 ...
- Linux内核分析第三周学习博客——跟踪分析Linux内核的启动过程
Linux内核分析第三周学习博客--跟踪分析Linux内核的启动过程 实验过程截图: 过程分析: 在Linux内核的启动过程中,一共经历了start_kernel,rest_init,kernel_t ...