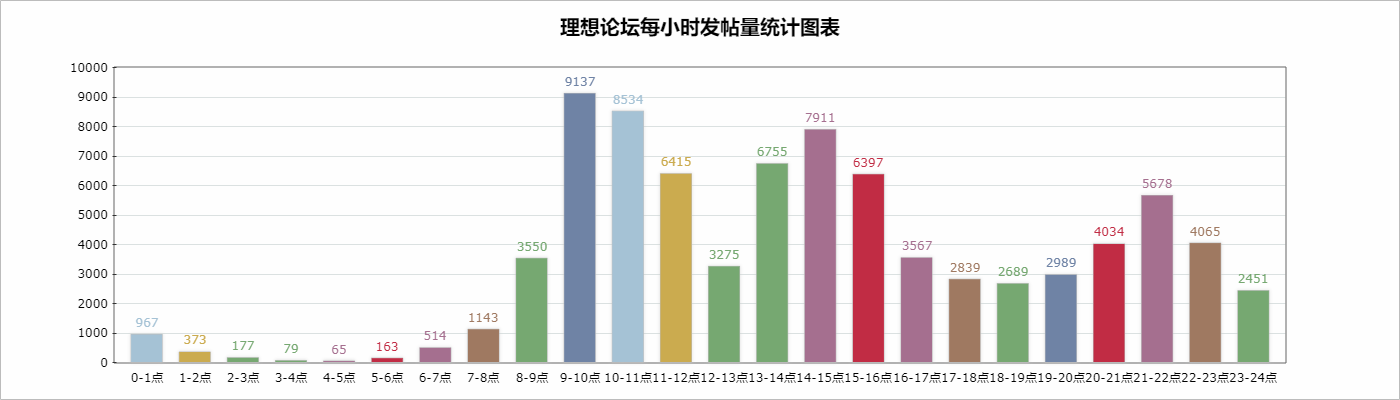
【ichartjs】爬取理想论坛前30页帖子获得每个子贴的发帖时间,总计83767条数据进行统计,生成统计图表
统计数据如下:
{': 2451}
图形化后效果如下:
源码:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<title> New Document </title>
<meta name="Generator" content="EditPlus">
<meta name="Author" content="">
<meta name="Keywords" content="">
<meta name="Description" content="">
</head>
<script src="ichart.1.2.min.js"></script>
<body>
<div id='canvasDiv'></div>
</body>
</html>
<script type="text/javascript">
<!--
//定义数据
var data = [
{name : '0-1点',value : 967,color:'#a5c2d5'},
{name : '1-2点',value : 373,color:'#cbab4f'},
{name : '2-3点',value : 177,color:'#76a871'},
{name : '3-4点',value : 79,color:'#76a871'},
{name : '4-5点',value : 65,color:'#a56f8f'},
{name : '5-6点',value : 163,color:'#c12c44'},
{name : '6-7点',value : 514,color:'#a56f8f'},
{name : '7-8点',value : 1143,color:'#9f7961'},
{name : '8-9点',value : 3550,color:'#76a871'},
{name : '9-10点',value : 9137,color:'#6f83a5'},
{name : '10-11点',value : 8534,color:'#a5c2d5'},
{name : '11-12点',value : 6415,color:'#cbab4f'},
{name : '12-13点',value : 3275,color:'#76a871'},
{name : '13-14点',value : 6755,color:'#76a871'},
{name : '14-15点',value : 7911,color:'#a56f8f'},
{name : '15-16点',value : 6397,color:'#c12c44'},
{name : '16-17点',value : 3567,color:'#a56f8f'},
{name : '17-18点',value : 2839,color:'#9f7961'},
{name : '18-19点',value : 2689,color:'#76a871'},
{name : '19-20点',value : 2989,color:'#6f83a5'},
{name : '20-21点',value : 4034,color:'#c12c44'},
{name : '21-22点',value : 5678,color:'#a56f8f'},
{name : '22-23点',value : 4065,color:'#9f7961'},
{name : '23-24点',value : 2451,color:'#76a871'}
];
$(function(){
var chart = new iChart.Column2D({
render : 'canvasDiv',//渲染的Dom目标,canvasDiv为Dom的ID
data: data,//绑定数据
title : '理想论坛每小时发帖量统计图表',//设置标题
width : 1400,//设置宽度,默认单位为px
height : 400,//设置高度,默认单位为px
shadow:true,//激活阴影
shadow_color:'#c7c7c7',//设置阴影颜色
coordinate:{//配置自定义坐标轴
scale:[{//配置自定义值轴
position:'left',//配置左值轴
start_scale:0,//设置开始刻度为0
end_scale:10000,//设置结束刻度为26
scale_space:1000,//设置刻度间距
listeners:{//配置事件
parseText:function(t,x,y){//设置解析值轴文本
return {text:t+""}
}
}
}]
}
});
//调用绘图方法开始绘图
chart.draw();
});
//-->
</script>
下载:
https://files.cnblogs.com/files/xiandedanteng/lxsum83767.rar
【ichartjs】爬取理想论坛前30页帖子获得每个子贴的发帖时间,总计83767条数据进行统计,生成统计图表的更多相关文章
- 【Python】爬取理想论坛单帖爬虫
代码: # 单帖爬虫,用于爬取理想论坛帖子得到发帖人,发帖时间和回帖时间,url例子见main函数 from bs4 import BeautifulSoup import requests impo ...
- Java爬取校内论坛新帖
Java爬取校内论坛新帖 为了保持消息灵通,博主没事会上上校内论坛看看新帖,作为爬虫爱好者,博主萌生了写个爬虫自动下载的想法. 嗯,这次就选Java. 第三方库准备 Jsoup Jsoup是一款比较好 ...
- Java爬取先知论坛文章
Java爬取先知论坛文章 0x00 前言 上篇文章写了部分爬虫代码,这里给出一个完整的爬取先知论坛文章代码. 0x01 代码实现 pom.xml加入依赖: <dependencies> & ...
- python 使用selenium模块爬取同一个url下不同页的内容(浏览器模拟人工翻页)
页面翻页,下一页可能是一个新的url 也有可能是用js进行页面跳转,url不变,解决方法是实现浏览器模拟人工翻页 目标:爬取同一个url下不同页的数据(上述第二种情况) url:http://www. ...
- 【Python项目】爬取新浪微博个人用户信息页
微博用户信息爬虫 项目链接:https://github.com/RealIvyWong/WeiboCrawler/tree/master/WeiboUserInfoCrawler 1 实现功能 这个 ...
- requests+正则爬取猫眼电影前100
最近复习功课,日常码农生活. import requests from requests.exceptions import RequestException import re import jso ...
- python3爬取豆瓣排名前250电影信息
#!/usr/bin/env python # -*- coding: utf-8 -*- # @File : doubanmovie.py # @Author: Anthony.waa # @Dat ...
- 【Python爬虫案例学习】Python爬取天涯论坛评论
用到的包有requests - BeautSoup 我爬的是天涯论坛的财经论坛:'http://bbs.tianya.cn/list.jsp?item=develop' 它里面的其中的一个帖子的URL ...
- Python爬虫实战(1):爬取Drupal论坛帖子列表
1,引言 在<Python即时网络爬虫项目: 内容提取器的定义>一文我们定义了一个通用的python网络爬虫类,期望通过这个项目节省程序员一半以上的时间.本文将用一个实例讲解怎样使用这个爬 ...
随机推荐
- JSP之登录验证码
1.JSP页面中设置输入选项和验证码 <form action=login.do" method="post" > <div class="l ...
- Unity Shader 之 渲染流水线
Unity Shader 之渲染流水线 什么是渲染流水线 一个渲染流程分成3个步骤: 应用阶段(Application stage) 几何阶段(Geometry stage) 光栅化阶段(Raster ...
- FastReport.Net使用:[16]图片控件使用
FastReport中,图片(Picture)控件的用法? 支持的图片格式 1.BMP, PNG, JPG, GIF, TIFF, ICO, EMF, WMF 支持的数据源 支持图片,数据列,文件名, ...
- JZYZOJ1330 土地购买 dp 斜率优化
不用long long的话只能ac一半的点而且完全查不出来错...放弃cin保平安.. x[i],y[i]分别为第i块土地的长和宽,输入后需要排序然后去掉冗余数据,最后得到的x[i]递增y[i]递 ...
- 【推导】【贪心】【高精度】Gym - 101194E - Bet
题意:每个队伍有个赔率pi,如果你往他身上押x元,它赢了,那么你得到x+(1/pi)x元,否则你一分都得不到.问你最多选几支队伍去押,使得存在一种押的方案,不论你押的那几支队伍谁赢,你都能赚得到钱. ...
- js异步处理工作机制(setTimeout, setInterval)
经常谈到异步,但是发现自己一直没深入理解setTimeout, setInterval,逛论坛的时候发现了这篇好文章,分享一下. ————————————————————以下为原文—————————— ...
- 内功心法 -- java.util.LinkedList<E> (2)
写在前面的话:读书破万卷,编码如有神--------------------------------------------------------------------下文主要对java.util ...
- [转]软件版本号扫盲——Beta RC Preview release等
1.软件版本阶段说明 *Alpha版:此版本表示该软件在此阶段主要是以实现软件功能为主,通常只在软件开发者内部交流,一般而言,该版本软件的Bug较多,需要继续修改. *Beta版:该版本相对于α版 ...
- centos安装openssl
1.跳转到文件下载目录 cd install-file 2.下载openssl安装文件 wget http://www.openssl.org/source/openssl-1.0.2a.tar.gz ...
- php curl 抓取
<?php set_time_limit(0); function curl_multi($urls) { if (!is_array($urls) or count($urls) == 0) ...